
I talk about an inefficient but common use case for DISTINCT: removing extra rows from joins.

I talk about an inefficient but common use case for DISTINCT: removing extra rows from joins.

Over a decade of posts and videos involving bad habits and best practices in SQL Server.

I've long been pro-schema-prefix, but in this post I talk about an exception to the rule at Stack Overflow, and why it works well.

For my first post on Simple Talk, I rip apart a made-up stored procedure as if I had encountered it during a code review.

For T-SQL Tuesday #158, I talk about a couple of justifiable worst practices.

For this month's T-SQL Tuesday, I talk about a not-quite-yet-announced feature in SQL Server 2022 that has the potential to function as a low-effort bad habit logger.

I talk about why every CTE I write starts with a semi-colon, and why you won't change my mind about it.

In the second part of this series, I show two ways to shift expensive computations to write time.

In this tip I confirm that FORMAT is still a dog compared to even very complex expressions using CONCAT_WS, DATENAME, DATEPART, and CONVERT.

I talk about NULLs in SQL Server, the logical issues with avoiding them, and potential performance impacts.

I talk a bit about bit columns: names with negative context, allowing NULLs, and using cryptic BITWISE operators instead of readable, self-documenting expressions.

In this tip, I use specific examples to counter assumptions that data types are always case insensitive.

In this tip, I discuss one way to help avoid infinite loops in common while loop patterns.

In part 4, I show how to include ad hoc DML queries in the analysis.

In part 3, I tie it together and show how to use relational logic to further eliminate false positives.

In part 2, I show how to identify problematic NOLOCK patterns across multiple databases and multiple instances.

I start a new series on identifying and removing problematic NOLOCK hints from update and delete statements.

I explain why you should eliminate the data types text, ntext, and image from your environment.
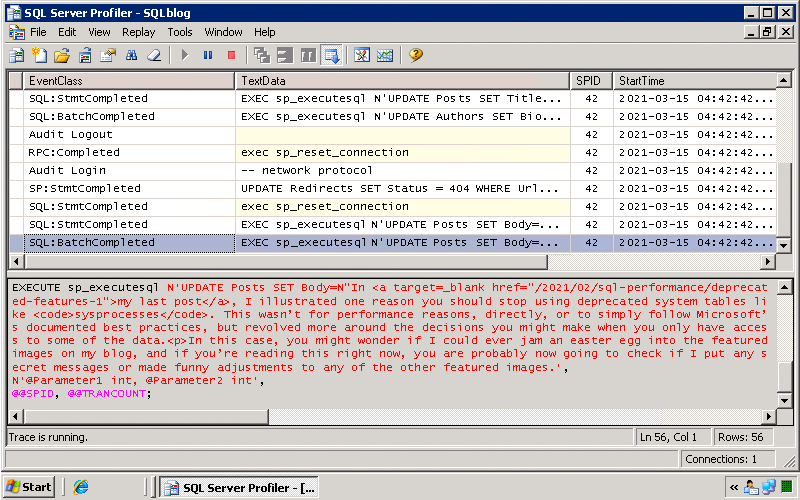
I use a real-world example showing why you shouldn't use deprecated functionality like SQL Server Profiler.
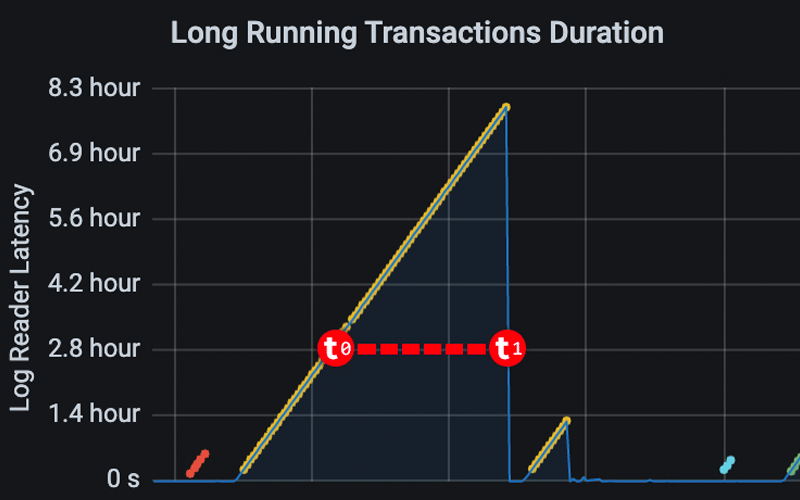
I talk about one scenario where the system table sys.sysprocesses almost led us down the wrong path.
There is a very common anti-pattern you should avoid, involving updating a row if it exists and inserting it if it doesn't. See how to avoid race conditions and deadlocks.

Discover some undocumented or unsupported behavior you might not even realize you're relying on.

Originally published in 2009, I updated this in 2019 with an example showing an effect on the plan cache.

I explain four conventions I always follow when writing T-SQL queries.

Get a first-hand look at some of the ways NOLOCK can produce incorrect data.

This tip was refreshed with status updates for some of the critical bugs discovered in MERGE over the years.

This was mostly tongue-in-cheek, but I show that there is no performance difference between tabs and spaces. (There is, however, a better reason to prefer tabs: accessibility.)
I discuss a couple of potential problems that can occur when you are inconsistent about case sensitivity.

A little advice on the use of MDF/LDF files for backups.

I examine various impacts on SQL Server – not just disk space – when choosing a GUID as a clustering key.

I show some tricks for getting row counts efficiently, and explain why an accurate row count for a large table is a pipe dream.

I repeat "Bad habits" advice from the past about using statement terminators and schema references to avoid debugging troubles.

I point out that an often-used connection setting, AttachDBFileName, may be the source of many wasted hours of debugging and troubleshooting.

I treat a common scenario: behavior differs between two SQL Server databases that may be the same version, but different compatibility levels.
I discuss the NOLOCK hint in SQL Server, and why you want to avoid slapping it onto every table mentioned in every query.

I discuss ten common cases of misplaced optimization.

I explain why you should avoid helper functions, and join against the catalog views instead.

By way of an example, see why most of what you hear about SQL Server is only true some of the time, at best.

Talking about the common misconception that a while looper is faster than a cursor (and why it's still a cursor).

See why I prefer alias = expression over the more standards-compliant expression AS alias syntax.

See several examples supporting the idea that you should use catalog views, not INFORMATION_SCHEMA, in SQL Server.

Learn why you shouldn't use BETWEEN for date range queries, even with the date data type.
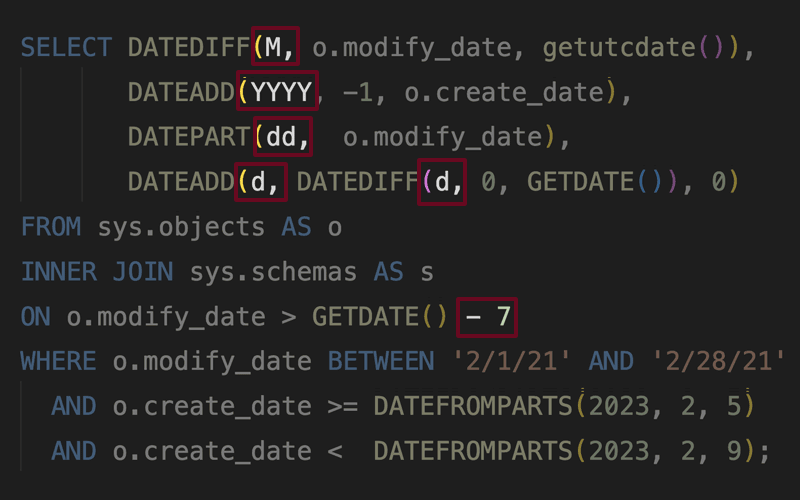
Read about some date/time shorthand you should avoid.

See why you should use sp_executesql instead of EXEC() for running dynamic SQL strings.

See an example that defies a generalization about performance: getting the largest value in a column.

Your naming scheme isn't important, but being consistent is crucial.

I talk about several things you can do to know and optimized what's going in and out of your disk.

I talk about creating a view that joins all the possible tables, and suggest that simplification isn't always worth it.