
See the full index.
Today I wanted to touch on massive and wasteful views that are re-used a little too much. The one-size-fits-all view: you've seen them, you've had to use them, you may have even created them. Why do we use them? Convenience, laziness, you name it.
Picture a forums system where you have users. On the user page you will see a bunch of data: demographic information, a picture, reputation score, badges, activity, last login time, questions asked, questions answered, etc. This system probably has tables like this (please allow me to grossly simplify things here):
CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, Username NVARCHAR(255) NOT NULL UNIQUE, FirstName NVARCHAR(32) NOT NULL, LastName NVARCHAR(32) NOT NULL, ProfilePictureURL VARCHAR(1024), CreatedDate SMALLDATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ); CREATE TABLE dbo.Questions ( QuestionID INT PRIMARY KEY, UserID INT NOT NULL REFERENCES dbo.Users(UserID), Question NVARCHAR(MAX), EventDate SMALLDATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ); CREATE TABLE dbo.Answers ( AnswerID INT PRIMARY KEY, QuestionID INT NOT NULL REFERENCES dbo.Questions(QuestionID), UserID INT NOT NULL REFERENCES dbo.Users(UserID), Answer NVARCHAR(MAX) NOT NULL, EventDate SMALLDATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ); CREATE TABLE dbo.ReputationPoints ( UserID INT NOT NULL REFERENCES dbo.Users(UserID), QuestionID INT REFERENCES dbo.Questions(QuestionID), AnswerID INT REFERENCES dbo.Answers(AnswerID), PointValue INT NOT NULL DEFAULT (10), EventDate SMALLDATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ); CREATE TABLE dbo.BadgesEarned ( BadgeID INT NOT NULL REFERENCES dbo.Badges(BadgeID), UserID INT NOT NULL REFERENCES dbo.Users(UserID), EventDate SMALLDATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP );
There are likely a bunch of other columns and indexes geared for the different ways the application will use the data, but this core schema should be a good enough start to get my point across. Let's start from the user page I was talking about, where you see something like this:

Now, if you were tasked to write a query that retrieved all of the data necessary to display this page, it would probably be something like this:
DECLARE @UserID INT; SELECT @UserID = 1; SELECT u.UserID, u.UserName, u.ProfilePictureURL, u.FirstName, u.LastName, Reputation = COALESCE(r.Reputation, 0), MemberSince = u.CreatedDate, LastActivity = q.EventDate, QuestionsAsked = q.QuestionCount, QuestionsAnswered = q.AnswerCount, BadgesEarned = COUNT(b.BadgeID) FROM dbo.Users AS u LEFT OUTER JOIN ( SELECT UserID, Reputation = SUM(PointValue) FROM dbo.ReputationPoints WHERE UserID = @UserID GROUP BY UserID ) AS r ON u.UserID = r.UserID LEFT OUTER JOIN ( SELECT UserID, EventDate = MAX(EventDate), QuestionCount = MAX(QuestionCount), AnswerCount = MAX(AnswerCount), FROM ( SELECT UserID, EventDate = MAX(EventDate), QuestionCount = 0, AnswerCount = COUNT(*) FROM dbo.Answers WHERE UserID = @UserID GROUP BY UserID UNION ALL SELECT UserID, EventDate = MAX(EventDate), QuestionCount = COUNT(*), AnswerCount = 0 FROM dbo.Questions WHERE UserID = @UserID GROUP BY UserID ) AS s ) AS q ON u.UserID = q.UserID LEFT OUTER JOIN dbo.BadgesEarned AS b ON u.UserID = b.UserID WHERE u.UserID = @UserID;
A lot of people will turn this into a view, so that when they need to get this information from a different stored procedure, they don't have to repeat a lot of the same code. Creating the view only requires that you take out the WHERE clauses:
CREATE VIEW dbo.UserData AS SELECT u.UserID, u.UserName, u.ProfilePictureURL, u.FirstName, u.LastName, Reputation = COALESCE(r.Reputation, 0), MemberSince = u.CreatedDate, LastActivity = q.EventDate, QuestionsAsked = q.QuestionCount, QuestionsAnswered = q.AnswerCount, BadgesEarned = COUNT(b.BadgeID) FROM dbo.Users AS u LEFT OUTER JOIN ( SELECT UserID, Reputation = SUM(PointValue) FROM dbo.ReputationPoints GROUP BY UserID ) AS r ON u.UserID = r.UserID LEFT OUTER JOIN ( SELECT UserID, EventDate = MAX(EventDate), QuestionCount = MAX(QuestionCount), AnswerCount = MAX(AnswerCount), FROM ( SELECT UserID, EventDate = MAX(EventDate), QuestionCount = 0, AnswerCount = COUNT(*) FROM dbo.Answers GROUP BY UserID UNION ALL SELECT UserID, EventDate = MAX(EventDate), QuestionCount = COUNT(*), AnswerCount = 0 FROM dbo.Questions GROUP BY UserID ) AS s ) AS q ON u.UserID = q.UserID LEFT OUTER JOIN dbo.BadgesEarned AS b ON u.UserID = b.UserID;
Turning this into a view on its own is not necessarily a bad thing. If it is truly for re-use in other queries where most or all of the columns (and hence derived tables) are required, then I see nothing wrong with encapsulating these joins into a single view, instead of repeating those joins and derived tables several times across slightly different stored procedures. The problem comes in when the view gets used in stored procedures that need a very small subset of the columns. Another problem arises when some new interface needs a couple of those columns and then some other key piece of information… instead of writing a new query, the view above is modified to add another left join, or derived table, or correlated subquery, or UDF to calculate an additional column value. Not only is this wasteful for the new application page (since it doesn't need everything above), it is also wasteful for the existing application pages already using the view, since they will simply ignore this extra column. This is obviously a rabbit-hole you don't really want to find yourself stuck in a year or two down the road.
We have inherited legacy views like this that return all kinds of information about a particular type of entity, and they get called even when all that the application needs are a couple of columns from the core table (e.g. UserID and UserName, for populating a drop-down list). Even worse is when we go after a small subset of columns in the view and only for a single user (e.g. just get reputation count) – the stored procedure uses the view presumably because the user copied part of the query from another stored procedure that users the view. Obviously it is very expensive to materialize that view (especially those computations in the derived tables) for the entire set of users in the database, and this is quite wasteful if we're only after data that is found all by itself in the Users table. In this case, at least in my humble opinion, it would be better to just have a stored procedure called dbo.User_GetList, which just went after the dbo.Users table directly, or to create a second view, called UserList, that looked like this (since this is all that application page requires):
CREATE VIEW dbo.UserList AS SELECT UserID, UserName FROM dbo.Users;
Now you have two views to maintain, but one of them is fairly trivial, and will help prevent your server from doing a lot of extra work every time the list of users is presented to the application. And perhaps at this point you could move the larger view code above back into a stored procedure, where it can remain parameterized so that even when all of the columns are needed, it is a narrow set of rows that are evaluated. Again, I'm not sure that I can tell you when you will need the view for re-use, but in most cases I've seen, the page that has a smorgasbord of information about an entity only appears once in an application, and it is likely the case that smaller sets of columns are re-used more widely.
We are working on cleaning some of these up, and this work was the motivation behind this post. And you may laugh, or wonder, "who would do such a thing?", but I've seen it often.
UPDATE
Rob has pointed out several flaws with my example, including my syntax errors, as well as the fact that the query optimizer is smart enough to not materialize every OUTER JOIN that isn't needed in the result set (and this join elimination can happen with INNER JOINs as well, FYI). I'm not going to go back and correct those, and I'll admit that I rushed through my initial thinking of this article. But let's move on and try a slightly more extreme example – and one which is actually much more indicative of the cases where I've seen this kind of problem. Picture a case where you are logging all changes to a user, have normalized certain attributes (in this case a user category), and encapsulated formatting logic (in this case date/time output). You might have something like this:
-- normalize category descriptions CREATE TABLE dbo.UserCategories ( UserCategoryID TINYINT PRIMARY KEY, [Description] NVARCHAR(32) NOT NULL UNIQUE ); GO CREATE FUNCTION dbo.GetUserCategory ( @UserCategoryID TINYINT ) RETURNS NVARCHAR(32) AS BEGIN RETURN ( SELECT [Description] FROM dbo.UserCategories WHERE UserCategoryID = @UserCategoryID ); END GO -- encapsulate consistent date formatting CREATE FUNCTION dbo.FixDate ( @d SMALLDATETIME ) RETURNS CHAR(16) AS BEGIN RETURN ( SELECT CONVERT(CHAR(10), @d, 120) + ' ' + CONVERT(CHAR(5), @d, 108) ); END GO -- standard users table CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, UserName NVARCHAR(255) NOT NULL UNIQUE, UserCategoryID TINYINT NOT NULL REFERENCES dbo.UserCategories(UserCategoryID) /* , other columns */ ); GO -- keep a log of who changed what -- (including initial creation, so always >= 1 row per user) CREATE TABLE dbo.UserChangeLog ( UserID INT NOT NULL REFERENCES dbo.Users(UserID), EventDate SMALLDATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP, Details NVARCHAR(255) NOT NULL ); GO -- now, an uber-view intended for use across -- several different queries CREATE VIEW dbo.UserData AS SELECT u.UserID, u.UserName, /* , other u. columns */ Category = dbo.GetUserCategory(u.UserCategoryID), LastUpdate = dbo.FixDate(a.LastModified) FROM dbo.Users AS u INNER JOIN ( SELECT UserID, LastModified = MAX(EventDate) FROM dbo.UserChangeLog GROUP BY UserID ) AS a ON u.UserID = a.UserID; GO
In this case, you'll see that the entire view is materialized no matter how few columns you ask for in the SELECT. Just turn on the execution plan… you'll see that while the graphical plan is not 100% identical, all of the expensive operators are (click on the exec plan to embiggen):
SELECT UserID FROM dbo.UserData; SELECT * FROM dbo.UserData;
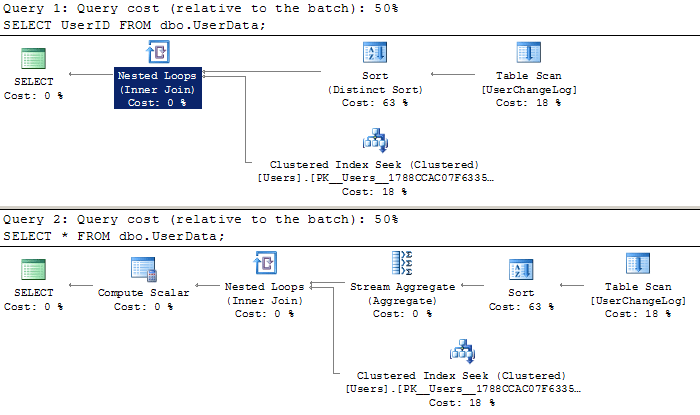
So, unlike in the example I presented earlier, in this case (and thanks Rob for the prodding), I think I can demonstrate that there is extra work being done in the case where you are only after a narrow subset of the columns.
Now, it could be argued that there are plenty of "bad habits" in there that are just as important, or even more important, than the one I am trying to highlight in this post. It could also be argued that folks like Rob or myself, as well as a lot of this site's readers, would never lay out a system like this and expect it to perform. But what I try to keep in mind when I write articles like this is that they are intended for people of all levels – those that may have contributed to this design, or those that may have inherited it and don't understand their current performance issues. And I think it is hard to argue that this type of encapsulation and/or normalization is rare out in the wild, so ultimately it could be an issue that is affecting a lot of environments.
Anyway, is the uber-view always bad? Of course not. My intention here is not to tell you, "you should never do x and that is always true." I just want to point out practices and usage patterns that should be thoroughly thought out as opposed to just blindly implemented.
See the full index.
Quite often I see an entire set of uber-views and then views that join them together. Nothing is more frustrating than trying to optimize a poorly performing query and seeing this:
select * from uberView1
uberView1:
select * from uberView2 join uberView3 join uberView4
uberView2:
select * from uberView4 join uberView5 join uberView6
uberView3:
select * from uberView5 join uberView7 join uberView8
etc. ad infinitum. I think you get the point. After spending about 2-3 hours to finally get this query resolved to the table level, you find that each of the tables are joined in the query 5 or 6 times.
In my own daily work I think I never seen an inner join being optimised away. Such a join would not be needed if it were I would think. The only example I ever seen (recently) where it did get optimised away was on the internet as part of a article highlighting what can be considdered a bug. In that instance the act of optimising away the join caused the outcome of the query to change.
I bumped into the problem of unwanted joins myself a few times. What always seems to work for me but is somehwat restricted is using subselects for individual columns. Granted if you need multiple columns, this becomes awkward, but it works well.
Does anyone know if SQL 2005 and SQL 2008 standard editions differ in the extent to which they optimize joins away? I never dit proper testing for this as only recently got access to SQL 2008.
Thanks Paul, yeah I've found that views usually start out with good intentions, like the case where a certain calculation about an entity needs to be retrieved by multiple stored procedures. The problem is when a 3rd stored procedure comes along, is mimicked from one of the other two, and then encourages the user to modify the view to accommodate some other need in the new procedure (that the existing two do not need).
Brian, I think there are definitely different reasons for creating views, and they aren't always about creating or enforcing business rules. But I get your point.
Aaron, I like this post. A confused moment at a client site was when optimizing a proc that called a view, that called a view, that used a synonym that referenced a monster aggregate view (that only pulled back a couple non-aggregated columns). The two nested views were trivial to find, but hiding a view using a synonym took a few moments to figure out. The net result was a single simplified query right in the proc.
Single level views are great for ad-hoc queries, but I don’t like nesting views or procs that call views – that’s not playing nice for the next guy having to untangle the mess. I guess my view on views is that they’re better as single level rentals than production high-rises.
Aaron, good post, as usual. I have a different take on this particular topic, however:
Although VIEWs can be a problem when designed for a specific purpose, i think that attitude is wrong form the beginning. The purpose of a VIEW is to CREATE a business-rule defined object in the system.
That is, each TABLE in a data model represents an object/entity in the system or a relationship between other objects/entities. A VIEW hardcodes business rules to define more objects.
For example, if there is a business rule that all user's whose name rhyme with "baron", have a black-and-white image account, and post about bad habits should get ad admin access on everyone computer, we should CREATE a VIEW for that:
CREATE VIEW Administrator AS
SELECT Id FROM User_Role WHERE Role = 'Admin' UNION ALL
SELECT Id FROM User WHERE Image_Palette = 'black-and-white' AND First_Name LIKE '_aron' AND EXISTS(SELECT * FROM Post WHERE Post.User = User.Id AND Content LIKE 'Bad Habits%';
This way the rule will never need to be repeated. It is one ares that defines (and hard codes) rules for the business-rule based object.
If that is the case, no matter how complex the VIEW is, it is the only way to do it. Optimize it as required, but do not shy away because of complexity.
There is a second type of VIEW made for convenience. Those should be one per user. As when a user's needs change, so does the VIEW. Giving two user's the same convenience VIEW is just asking for trouble, as you pointed out very well.
Thanks for updating it… In this scenario, I'd be doing some figuring out to see if that INNER JOIN could be replaced with a LEFT JOIN, as this would then provide the simplifying. After all, the definition of that view is "For users with changelog entries, provide this info about them".
This is a very real situation, that I come across all the time. People put logic into views which cause the view definition to be not exactly what they want. The upshot being that they then use this view in other contexts not realising the extra 'functionality' it provides.
And when that's the scenario, I definitely recommend against using such views.
🙂 Sounds good, and feel free to delete my comments if they don't fit. I do appreciate the point behind the post, but I also think that uber-views can be really useful for storing logic considering how much the QO will simplify them out if the joins can be seen as redundant.
Yes Rob, I'll admit I threw the code sample together quickly to illustrate the point. It wasn't intended to be a "see how this runs on your system" kind of sample, just an illustrative one. I'll update the post with something a little closer to home and less made up from my perspective, and show that using a master view to satisfy all potential queries can be a bad thing.
Actually – your code doesn't run right now. You're missing a table called dbo.Badges, you have a rogue column after MAX(AnswerCount) and you need a couple of extra GROUP BY clauses.
I've turned it into the even more ugly (featuring a really horrible-looking group by clause):
CREATE VIEW dbo.UserData
AS
SELECT
u.UserID,
u.UserName,
u.ProfilePictureURL,
u.FirstName,
u.LastName,
Reputation = COALESCE(r.Reputation, 0),
MemberSince = u.CreatedDate,
LastActivity = q.EventDate,
QuestionsAsked = q.QuestionCount,
QuestionsAnswered = q.AnswerCount,
BadgesEarned = COUNT(b.BadgeID)
FROM
dbo.Users AS u
LEFT OUTER JOIN
(
SELECT
UserID,
Reputation = SUM(PointValue)
FROM dbo.ReputationPoints
GROUP BY UserID
) AS r
ON u.UserID = r.UserID
LEFT OUTER JOIN
(
SELECT
UserID,
EventDate = MAX(EventDate),
QuestionCount = MAX(QuestionCount),
AnswerCount = MAX(AnswerCount)
FROM
(
SELECT
UserID,
EventDate = MAX(EventDate),
QuestionCount = 0,
AnswerCount = COUNT(*)
FROM
dbo.Answers
GROUP BY UserID
UNION ALL
SELECT
UserID,
EventDate = MAX(EventDate),
QuestionCount = COUNT(*),
AnswerCount = 0
FROM
dbo.Questions
GROUP BY UserID
) AS s
group by s.UserID
) AS q
ON u.UserID = q.UserID
LEFT OUTER JOIN dbo.BadgesEarned AS b
ON u.UserID = b.UserID
group by u.UserID,
u.UserName,
u.ProfilePictureURL,
u.FirstName,
u.LastName,
r.Reputation,
u.CreatedDate,
q.EventDate,
q.QuestionCount,
q.AnswerCount
;
And the query plan for: SELECT UserID FROM dbo.UserData WHERE UserName = 'Rob'; –is a plan with a single Index Seek, nothing more. No other tables, no lookups, no computed scalars, nothing.
I know you know this stuff, Aaron, I just figured I'd provide an example of the simplification for people that want to try it out for themselves.
I do completely agree with you regarding the re-use of a stored procedure that contains a large query – but I don't find that's an issue with views.
Your example doesn't seem particularly trivial. You're making good use of a view to define how QuestionCount and AnswerCount are to be calculated. It's a very common situation, and one that I would encourage, SO LONG AS the way that it's used doesn't involve selecting columns needlessly.
I see listing columns that aren't needed as the main culprit here, and it will affect covering indexes as well. If you can select only the columns you need, then you see massive opportunity for query simplification.
I guess I'm really just coming from the perspective of having done a bunch of investigation into views like this to try to make querying easier for development teams. So I found these 'join uses' that I mention in the Deep Dives book. Incidentally – if you watch (and like) that video from sqlbits, you did inspire me to set up speakerrate.com/robfarley
Also this was a trivial example. The ones I've run across in real life have had inner joins (e.g. to lookup tables), UDFs referenced in the select list (e.g. to "pretty format" a datetime value), or both. Or even worse – UDFs applied to the values that come back from the inner joined lookup tables. And then those columns aren't even used.
Perhaps I should bake up a more dangerous example.
I should as a caveat that the QO will see that these joins are redundant because of the grouping you've done and the fact that you're using left joins. I also go into this in chapter 7 of sqlservermvpdeepdives.com
Large views like this can be scary, but given the choice of seeing this functionality in one place rather than seeing it all over, I'd rather have it in one place, and check the way that the view is used (eg, avoiding select *)
Thanks Rob, unfortunately what I'm seeing is that this re-use thing is often combined with a stored procedure that does SELECT * (even the one that only needs two columns), and then the application ignores the columns it doesn't need. So in that case everything certainly is materialized and sent over the wire, such a waste. 🙁
The system won't materialise all the columns that aren't involved. In fact, the Query Optimizer will realise that those joins are completely redundant and ignore them if you don't pull back the columns.
Find my video on "Designing for Simplification" from SQLBits V (at sqlbits.com), and you'll see this demonstrated.
I would rather people use a view like this if it has become the standard way of accessing user data. That way, I can be more confident that the logic is being used consistently. I see too many cases where a calculation is slightly different, and the application reports different data in different parts. (Imagine someone else counts Answers differently, around the area of multiple answers on a single question)
The reuse case that frustrates me is the uber-procedure, which returns everything and lets the application do the filtering.