
I talk about archive tables in SQL Server and how to improve the process using table partitioning.

I talk about archive tables in SQL Server and how to improve the process using table partitioning.

For T-SQL Tuesday #200, I offer up one thing that always raises my eyebrows during a code review: the RIGHT OUTER JOIN.

I recently solved a huge memory grant issue by rewriting a query. Implementing a supporting index wasn't enough to keep SQL Server from turning itself off.

The most recent failover of Stack Overflow – a busy, 8TB database – took 12 seconds. Find out how.
In this series on common SQL Server problems, I provide some guidance around the error message "An invalid length was passed to the LEFT or SUBSTRING function…" errors.

I detail issues we experienced (and maybe should have expected) while upgrading to SQL Server 2025.

In this tip, I show a few pagination tricks to let users filter without killing performance.

In this tip, I talk about an approach to achieve constant (O(1)) performance on every page instead of just the early pages. The approach isn't without its trade-offs, but if you're optimizing for runtime performance…

In this ongoing series on common problems in SQL Server, I explain many possible reasons for "Invalid Object Name" errors.

In the past, we've used xp_cmdshell and PowerShell to send Slack messages from the database. In SQL Server 2025, there's (arguably) a better way…
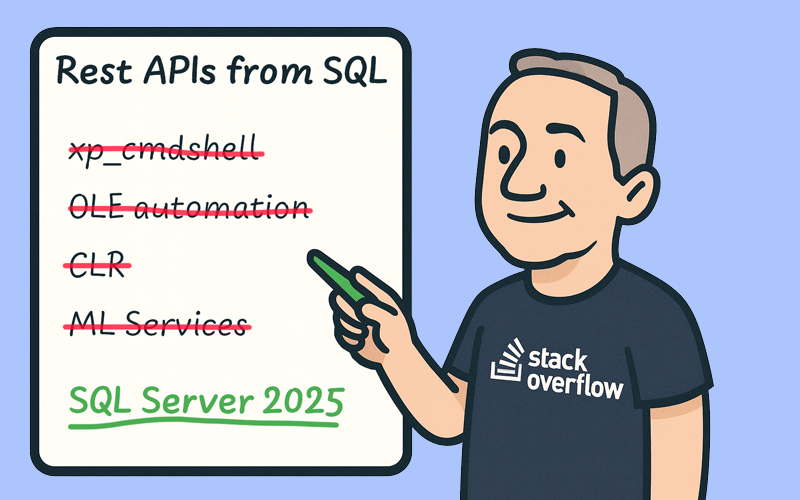
SQL Server 2025 introduced a new way to hit APIs from the engine, but is it better than all the quirky ways we've done this in the past?

In my previous post, I showed how I collect index information across all replicas to get the whole picture. In this follow-up, I add more context.

In this post, I show how I make decisions about unused or redundant indexes with the whole picture: analyzing activity across primary and all secondary replicas.
I recently built a process to create a new filtered index on a schedule to support a UI that only cares about the last 30 days.

I dug a little into one of the new RegEx functions in SQL Server 2025: REGEXP_SPLIT_TO_TABLE.

In this follow-up, I show how we determine all possible point of time restores and identify which backup files to keep in order to meet our recovery objectives.

In this article, I detail some of the things we do to manage backups and retention policies for hundreds of production databases.

I put together a brief list of all the things that can cause "A network-related or instance-specific" error messages, and a few things that can't.

As the SQL Server 2025 public preview hit the streets, I had to test the new backup compression algorithn, ZSTD, on a decently-sized database.

Occasionally, it's fun to talk about our wish lists for SQL Server. In this post, I talk about a few that I came across recently…

I recently had a great conversation with Louis Davidson as part of his "Coffee chat with…" series on Simple Talk.

I show an inline table-valued function to extract values from an integer encoded with days of the week.

I talk about some of the challenges and qualitative factors that influence how you add, remove, and change indexes.

I consolidate many bits of Docker advice that had previously been scattered across several different posts.

In this post, I talk about why it's so important to regularly test that your backups can be restored.

In the last part of the series, I show how I coordinate multiple parallel jobs… and what comes after them.

In part 3 of this series, I dig into some detail about how I further parallelized the work and reduced overall runtime.

In part 2, I show how I take advantage of snake draft order with a couple of real use cases.

In this four-part series, I borrow a concept from fantasy football to solve an optimization problem in a long-running weekly job in SQL Server.

I talk about a technique that can avoid expensive sorting to paginate by large string values.

In this post I talk about how to avoid losing valuable debugging information in the abyss and noise of SQL Server Agent's history.

I put together a few pointers about upgrading SQL Server, including /SkipRules, and avoiding the web installer.

For this month's T-SQL Tuesday, Brent Ozar asks about the last ticket we closed. I came close…

I talk about several things you can do to clean up after yourself and be a good RDP citizen.

If you're planning to roll forward your existing configuration file to SQL Server 2022, read this first.

Azure SQL Database got an update: A new locking model that might finally displace NOLOCK.

2023 was an interesting year for SQLblog.org – I talk about top posts and some changes I made here over the year.

I show how to use metadata to avoid costly reads when retrieving counts, even for a subset of the table.

This month, Kay Sauter encourages us to say thanks to those who helped us this year.

I talk about some rarely-used WAITFOR functionality that I use for testing.

While I've very rarely been jealous of Oracle, 23c added something I really want in SQL Server.

I discuss reasons you might think a data change was successful when it wasn't – or vice-versa.

I talk about the evolution of my thinking on featured images, and how I use generative AI for most post companions these days.

Bit columns can be tricky, and I discuss a few techniques for sanity and performance – including filtered indexes when skew is dramatic.

For this month's T-SQL Tuesday, Steve Jones asks us to talk about problems we've solved using window functions.

UNPIVOT works great when you're populating a single output column, but I talk about how CROSS APPLY can work better in more complex scenarios.

I discuss decisions and trade-offs when migrating Stack Overflow for Teams – first to a new cluster, and then to a new version of SQL Server.

I recognize this year's recipient of my Community Influencer of the Year award.