
See the full index.
In this post, in line with tomorrow's T-SQL Tuesday hosted by Mike Walsh, I wanted to talk about some I/O issues that tend to get ignored in a lot of environments.
Introduction
In my experience, today's SQL Server systems are primarily I/O-bound, not CPU- or memory-bound. And while more CPUs and additional memory banks can't hurt, resolving I/O issues will usually give you much more bang-for-your-buck. I've assembled a few things you can do in your environment to avoid costly I/O issues.
Observe I/O statistics on queries
Particularly in the design phase, you may consider different approaches to table design and solving query requirements. Now, part of the problem is often that you are developing and testing on hardware that differs from your production environment (where performance will be the most important). You may be on a 32-bit system, you may have much less RAM to work with, and you will almost certainly be on a different class of disks. So it is important to understand that the timings and execution plan comparisons are only part of the decision criteria for determine the best approach. An important part of performance analysis that people often set aside during development is I/O; mostly, physical and logical reads. Often these people get to it eventually, as it bites them when their systems scale up and they become truly I/O-bound. So in addition to examining execution plans , do yourself a favor and also check I/O statistics. You can do this using the following SET command in Management Studio:
SET STATISTICS IO ON;
As a result, you will see output like this for each object:
What do you want to watch for? High scans and high logical reads, but more importantly, high physical reads. How much is too much? At the risk of getting hit by ripe tomatoes, I will answer, "it depends." And it really does. If you have two queries that return the same results, and one is slower in your test environment but shows lower I/O in the statistics profile, I would bet on the latter at scale. Ideally you will be able to test at scale now, or at least keep the other version of the query around so that you can test at scale when you get there, and potentially switch in the one that performs better.
The official docs on SET STATISTICS IO are in Books Online:
Consider data compression
Last year I wrote several blog posts talking about data compression in SQL Server 2008 and SQL Server 2008 R2 – here, here, here, and here. Most people think about data compression as a way to save space, and as disks get cheaper, the feature seems less and less important to them. I can assure you that there is another side to data compression: with less data to read / write, you can lower your I/O and memory overhead (of course at the cost of CPU). So in an I/O-bound system with plenty of room for additional CPU cycles, it is definitely worth testing whether this will improve your overall performance in addition to saving disk space. Data compression is only available in SQL Server 2008 and above, and in Enterprise Edition and above, but in the future this may very well be available in all editions. Unfortunately you really have to put your systems through their paces in order to determine how the feature will affect throughput; the stored procedure provided to estimate savings only tells you roughly how much space you will save, but does not give any clue about performance changes. Wouldn't it be great if you could provide a sample workload, or even an execution plan, and the system could tell you how page or row compression would change the performance of the workload or plan? Hey, I can dream, right?
You can read more about data compression at the following places:
Use backup compression, always
SQL Server 2008 added a new feature: backup compression. Like data compression, this trades I/O for CPU, resulting in smaller backups that require slightly higher CPU but still finish faster (at least in every test I've performed to date). If the CPU usage is too high but you still want to take advantage of the space savings, you can use the Resource Governor to limit the CPU impact of compression. For more information, see this documentation or the Resource Governor whitepaper I wrote with Boris Baryshnikov.
For more information on backup compression, see this topic in Books Online:
Get your voice heard during system configuration
For several years, I was stuck with a system that was designed in an IT closet without any input from the rest of the team. What resulted was an EMC Clariion with disks configured in RAID 5, underlying spindles all shared, with allocation unit sizes of either 4K or 8K, and on a Windows Server 2003 with misaligned partitions. Now if I had been in the room when these decisions were being made, I would like to think that I could have influenced at least some of them. I doubt that at the time I would have put much thought into partition alignment, but I would have tried to persuade them to use RAID 10, to split out the storage groups better, and to use larger block sizes. Once a system is out in production, it is very difficult to change any of these things without actually migrating to new hardware (at least temporarily). Unless your maintenance windows can be very large (most cannot). So the rest of the points in this article will try to help arm you with information that will help in your discussions with IT about how a new system should be configured (if you have the luxury of starting from scratch), or how an existing system could be improved. Don't be like me, and be stuck for months or more with a system that can't possibly achieve the performance your boss expects… make sure he or she is aware up front that that performance will come at a cost, or at least with a little planning.
Use different spindles for data, log, and tempdb
Ideally, you will have different storage groups (or physical disks) for data files, log files, and tempdb data files. Placing all your data and log files (never mind tempdb) on the same disk, sooner or later, will sink your battleship. We currently have multiple dedicated LUNs for data, one dedicated LUN for log files, and one dedicated LUN for tempdb (I'll explain our tempdb setup shortly). It is important to split up this activity across different spindles and controllers when possible… in addition to maximizing read and write performance, this also allows you to customize things like RAID and block size for the different I/O characteristics your files will exhibit.
Have a dedicated local drive (or LUN) for backups
This is one I see contested a lot. Some people say, "only backup to the network!", while others say, "only backup locally!" On a SAN there isn't really as much difference as there is with local disks, but the best approach, IMHO, is to have a mix: backup locally, then copy to a safer location on the network; when the copy succeeds and the backup has been verified from the new location, you can delete the local copy. Backing up directly over the network can only be slower than backing up locally. However to make this possible I strongly recommend a dedicated local drive (or LUN). In addition to the additional I/O SQL Server has to perform to take the backup in the first place, the last thing you want to be doing is to have that I/O activity competing with users' activity against the databases. Oh, and don't forget to back up off-site on a regular schedule also… this doesn't have anything to do with the I/O problems I'm trying to outline, just want to be clear that backing up to a different server in the same rack will solve all of your disaster recovery needs.
Stripe tempdb data files
The standard guideline is to create a separate tempdb file for each core (my memory had served me wrong, I thought for sure this was per physical and not logical CPU), and to make them all the same size. This will allow you to spread out the I/O to tempdb in the most efficient way. If you can afford the layout, each file should go on its own dedicated LUN. Of course this is prohibitively expensive in a RAID 10 scenario, since you will need a lot of drives to make up a separate LUN (more importantly, with separate underlying heads/spindles), and the minimum size will still likely be 73GB (I don't know if you can still buy 36GB drives for high-end storage, and you certainly couldn't do this with internal storage). So if you want 4 tempdb files on RAID 10, for example, you will need either 16 or 24 drives — and will likely end up with a lot of expensive, wasted space. In our case, due to a shortage of drives, we placed all four tempdb files (~8GB each) on a single dedicated LUN (73GB). I don't recall if this was a striped mirror or a mirrored stripe, but it was all we had available after creating multiple dedicated LUNs for different segments of our data files.
For more information on optimizing tempdb performance, see this Books Online topic:
Be aware of partition alignment
Partition alignment has received a lot of press lately. Boiled down, the problem is that on Windows Server 2003 and earlier, the default layout of disks leads to inefficient I/O due to an offset of the sectors on the disk. On Windows Server 2008 and above, partitions are created with the right alignment right out of the box.) By fixing this issue, you can expect to dramatically improve your SQL Server performance. But don't take it from me; take it from Jimmy May's excellent presentation or SQL Server Premier Field Engineers
How do you determine if your partitions are aligned? Well, first you can take a look at the offsets of your logical partitions. Fire up a PowerShell window and run this:
$p = @("Name", "StartingOffset") get-wmiobject -query "SELECT * FROM Win32_DiskPartition" | Format-Table $p
For each partition in the result, divide each StartingOffset value / 65536.0. (Sorry, total PowerShell newbie here, otherwise I'd tell you how to do it all in one step.) If any of these numbers result in a remainder other than 0, that partition is probably suspect. (This is usually okay for the boot drive, but not for data or log files. And if you have data / log files on your boot drive, do what you can to move them.) Now, you will need to do some more work to figure out which drives those are (if you are comfortable with WMI, move on to Win32_LogicalDiskToPartition), and then more work still to fix the problem. In addition to the links above, these articles should be of great help:
- Disk Partition Alignment Best Practices for SQL Server
- Disk performance may be slower than expected when you use multiple disks
Another quick way to spot alignment problems, if you are using SQL Sentry, is to look on the Performance Advisor's Disk Space or Disk Activity tabs. Partitions that are misaligned are clearly highlighted in red, as the following screenshot illustrates:
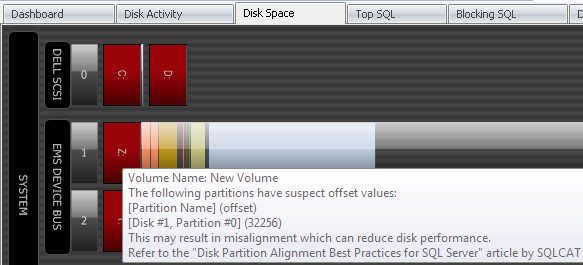
Wow, easy, right? As an added bonus, monitoring tools like this can tell you a lot more about I/O on your servers (and of course many other performance metrics).
Understand RAID
Now, I am not a hardware guy at all, but I know that while more expensive, RAID 10 is superior to RAID 5 in almost all things SQL Server (except log, is usually okay on RAID 1). If you don't have direct access to the disks, ask your IT/SAN guy what RAID level all of your LUNs are using. For each LUN that hosts data files (including tempdb) and isn't using disks at RAID 10, find out why, and find out how to fix it. For some databases RAID 5 will be "good enough," but in most cases you will want RAID 10 if you can afford it. I'll let the following articles help guide your decisions on RAID level:
Add memory
Sounds funny: increase memory to improve I/O? Well, let's think about it: for any operations that require memory (for example, sorting), if they can't get it, the operations will spool to disk. So, you can often see high I/O as a symptom of memory pressure. How much memory will you need? I'll give the classic answer: "it depends." There is no easy way to predict how much memory a system will need, especially before you've scaled and learned the actual usage patterns that will occur when the application is at its peak . The best advice I can give, if you don't have the ability to determine this beforehand, is to spend the best money on the storage subsystem, and spend the rest on memory. If you still have budget, get more memory. 🙂
Conclusion
I/O is a huge topic, but I see it set aside as secondary in a lot of environments. This is a huge mistake, IMHO. Even with the onset of solid state drives (I'll leave the other experts to talk about SSDs for today), I don't see I/O as a problem that will be magically solved any time soon. In fact it is the rate at which memory and CPU advances have been made that have assisted in demonstrating to us how far I/O still has to go.
See the full index.
A lot of really helpful information here. I still can't understand why Microsoft only added backup compression to Enterprise edition. Partition alignment is probably one of the most forgotten about subject nowadays. Hopefully more people will reads posts like this and start to get a hint. Great Post Aaron!
Cool adaptation Ben, thanks!
I played around a little bit and got the following for doing the WMI query in one shot:
get-wmiobject -query "select name, StartingOffset FROM Win32_DiskPartition" -computerName $server | select name, StartingOffset, @{Name="OffsetGood"; Expression={$_.StartingOffset % 65536 -eq 0}} | format-table
Aaron, I couldn't agree with you more, but it is the recommended starting point. Even Microsoft implies that an adjustment is likely necessary. Test, test, and test again!
Thanks Wes, corrected. My memory sucks. Still, I'm not sure if you will do much better with 16 tempdb files on a 16-core system than with 8 tempdb files, especially if they're all on the same LUN (or local disk), and even more so if they are on a disk with other data and/or log files. So I don't think that the general rule should be, "always stripe tempdb to the number of cores, no matter what."
Aaron, as per your own reference and SQL CAT, the "standard configuration" is one tempdb file per CPU, where *each core* counts as a CPU, not one file per socket.
Here is the quote from Microsoft’s guidance (emphasis on second sentence):
"As a general guideline, create one data file for each CPU on the server (accounting for any affinity mask settings) and then adjust the number of files up or down as necessary. Note that a dual-core CPU is considered to be two CPUs."
GREAT series, I cannot agree more! … ignored IO and config up front are (not necessarily the fun things) but a performance black-hole of ignored!!!
Before I saw the #tsql2sday I had been working on a post with a data warehouse spin, you cover it (with a lot fewer words) 🙂 http://stefbauer.wordpress.com/2010/03/01/help-my-disk-performance/
Thanks for the posts!!