
See the full index.
I see a lot of people suggest while loops instead of cursors in situations where row-based processing is required (or, at least, where folks think that row-based processing is required). Sometimes the justification is that constructing a while loop is simpler and more straightforward than constructing a cursor. Others suggest that a while loop is faster than a cursor because, well, it isn't a cursor. Of course the underlying mechanics still represent a cursor, it's just not explicitly stated that way using DECLARE CURSOR.
The difficulty of writing a piece of code should not be the primary factor in avoiding that type of code. I use MERGE – while I will likely never memorize that syntax, I know it is safer and less likely to cause deadlocks than typical "UPSERT" methodologies. Looking up the syntax diagram in Books Online, or using templates or snippets, are good workarounds to having to avoid coding constructs because they're "too hard." The same is true for cursors – sure the syntax is cumbersome, but templates or snippets can do most of the work for you.
Besides, is it that much simpler to set up and use a WHILE loop? And is it really that much more efficient? Or any less prone to infinite loops?
Simplicity
I asked a few colleagues to take this code sample and change it from an explicit cursor to a WHILE loop:
DECLARE @schema_name SYSNAME, @object_name SYSNAME, @index_name SYSNAME @s NVARCHAR(MAX) = N''; DECLARE indexes CURSOR LOCAL STATIC FORWARD_ONLY READ_ONLY FOR SELECT s = OBJECT_SCHEMA_NAME(o.[object_id]), o = o.name, i = i.name FROM sys.objects AS o INNER JOIN sys.indexes AS i ON o.[object_id] = i.[object_id] INNER JOIN ( SELECT [object_id], index_id, row_count = SUM(row_count) FROM sys.dm_db_partition_stats GROUP BY [object_id], index_id ) AS s ON o.[object_id] = s.[object_id] AND i.index_id = s.index_id WHERE o.is_ms_shipped = 0 AND i.index_id >= 1 ORDER BY s.row_count DESC, s, o, i; OPEN indexes; FETCH NEXT FROM indexes INTO @schema_name, @object_name, @index_name; WHILE @@FETCH_STATUS = 0 BEGIN -- we're just concatenating here, but pretend we needed to, -- say, call a stored procedure for each row in the cursor: SET @s += CHAR(13) + CHAR(10) + N'ALTER INDEX ' + QUOTENAME(@index_name) + ' ON ' + QUOTENAME(@schema_name) + '.' + QUOTENAME(@object_name) + ' REORGANIZE;'; FETCH NEXT FROM indexes INTO @schema_name, @object_name, @index_name; END CLOSE indexes; DEALLOCATE indexes;
Before you criticize the code sample, or tell me that I could do this without a cursor or a while loop, please understand that I wasn't really trying to solve this problem, I was only trying to come up with a simple string-building exercise that can be accomplished with a cursor. I know that a cursor isn't required to just return a concatenated string, for example you can use FOR XML PATH (or the much simpler STRING_AGG() on modern versions):
DECLARE @s NVARCHAR(MAX); SELECT @s = ( SELECT CHAR(13) + CHAR(10) + 'ALTER INDEX ' + QUOTENAME(i) + ' ON ' + QUOTENAME(s) + '.' + QUOTENAME(o) + ' REORGANIZE;' FROM ( SELECT TOP (1000000) s = OBJECT_SCHEMA_NAME(o.[object_id]), o = o.name, i = i.name FROM sys.objects AS o INNER JOIN sys.indexes AS i ON o.[object_id] = i.[object_id] INNER JOIN ( SELECT [object_id], index_id, row_count = SUM(row_count) FROM sys.dm_db_partition_stats GROUP BY [object_id], index_id ) AS s ON o.[object_id] = s.[object_id] AND i.index_id = s.index_id WHERE o.is_ms_shipped = 0 AND i.index_id >= 1 ORDER BY s.row_count DESC, s, o, i ) AS x FOR XML PATH(''), TYPE ).value('/text()[1]', 'NVARCHAR(MAX)');
Or even simpler concatenation:
DECLARE @s NVARCHAR(MAX) = N''; SELECT @s += CHAR(13) + CHAR(10) + 'ALTER INDEX ' + QUOTENAME(i) + ' ON ' + QUOTENAME(s) + '.' + QUOTENAME(o) + ' REORGANIZE;' FROM ( SELECT TOP (1000000) s = OBJECT_SCHEMA_NAME(o.[object_id]), o = o.name, i = i.name FROM sys.objects AS o INNER JOIN sys.indexes AS i ON o.[object_id] = i.[object_id] INNER JOIN ( SELECT [object_id], index_id, row_count = SUM(row_count) FROM sys.dm_db_partition_stats GROUP BY [object_id], index_id ) AS s ON o.[object_id] = s.[object_id] AND i.index_id = s.index_id WHERE o.is_ms_shipped = 0 AND i.index_id >= 1 ORDER BY s.row_count DESC, s, o, i ) AS x;
(While it's true that these alternatives don't use an explicit cursor or while loop, so may appear to be "set-based," it is important to note that in these approaches the actual output order is not guaranteed. And if you think this is accomplished under the hood without a cursor-like operation, you're only fooling yourself. :-))
Again, the point of the exercise was not to eliminate the cursor, but to see if a simpler, more straightforward while loop could achieve the same result. One of the complications of the desired result is that I want the resulting output to order the indexes by row_count descending. So there is no unique, incrementing column or index to take advantage of, like you might be able to do if you have an IDENTITY column and you don't care about order otherwise. So this was a potential wrench I threw in intentionally because, in my experience, you will often care about order and you won't always have the luxury of a column inherent in the data set that supports the desired order of processing.
I'll show the four while loops that were submitted. They're all quite similar, using either #temp tables or @table variables to hold the intermediate data set before looping. I'm not going to reveal who submitted these approaches, but rather simply label them Colleague #1, #2, #3 and #4 (both to keep them straight and to protect the innocent). I hope they aren't offended that I took a few liberties with their syntax (mostly indenting and statement termination). These are all fairly similar constructs, and in fact I received a 5th contribution just prior to publishing – I didn't include it because it didn't have any elements not present below.
Colleague #1
DECLARE @idx TABLE ( s SYSNAME, o SYSNAME, i SYSNAME, c BIGINT, rn INT ); INSERT @idx(s, o, i, c, rn) SELECT s, o, i, c, rn = ROW_NUMBER() OVER (ORDER BY c DESC, s, o, i) FROM ( SELECT s = OBJECT_SCHEMA_NAME(o.[object_id]), o = o.name, i = i.name, c = s.row_count FROM sys.objects AS o INNER JOIN sys.indexes AS i ON o.[object_id] = i.[object_id] INNER JOIN ( SELECT [object_id], index_id, row_count = SUM(row_count) FROM sys.dm_db_partition_stats GROUP BY [object_id], index_id ) AS s ON o.[object_id] = s.[object_id] AND i.index_id = s.index_id WHERE o.is_ms_shipped = 0 AND i.index_id >= 1 ) AS x; DECLARE @min INT, @max INT, @cur INT = 0, @s NVARCHAR(MAX) = N''; SELECT @min = MIN(rn), @max = MAX(rn) FROM @idx; WHILE (@cur < @max) BEGIN SET @cur += 1; SELECT @s += CHAR(13) + CHAR(10) + 'ALTER INDEX ' + QUOTENAME(i) + ' ON ' + QUOTENAME(s) + '.' + QUOTENAME(o) + ' REORGANIZE;' FROM @idx WHERE rn = @cur; END
Colleague #2
SELECT RowID = ROW_NUMBER() OVER (ORDER BY s.row_count DESC, OBJECT_SCHEMA_NAME(o.[object_id]), o.name, i.name), s = OBJECT_SCHEMA_NAME(o.[object_id]), o = o.name, i = i.name INTO #Temp FROM sys.objects AS o INNER JOIN sys.indexes AS i ON o.[object_id] = i.[object_id] INNER JOIN ( SELECT [object_id], index_id, row_count = SUM(row_count) FROM sys.dm_db_partition_stats GROUP BY [object_id], index_id ) AS s ON o.[object_id] = s.[object_id] AND i.index_id = s.index_id WHERE o.is_ms_shipped = 0 AND i.index_id >= 1 ORDER BY s.row_count DESC, s, o, i; DECLARE @CurrentRowID INT, @s NVARCHAR(MAX) = N''; SELECT @CurrentRowID = MIN(RowID) FROM #Temp; WHILE @CurrentRowID IS NOT NULL BEGIN SELECT @s += CHAR(13) + CHAR(10) + N'ALTER INDEX ' + QUOTENAME(i) + ' ON ' + QUOTENAME(s) + '.' + QUOTENAME(o) + ' REORGANIZE;' FROM #Temp WHERE RowID = @CurrentRowID; SELECT @CurrentRowID = MIN(RowID) FROM #Temp WHERE RowID > @CurrentRowID; END DROP TABLE #Temp;
Colleague #3
DECLARE @Temp TABLE ( RowID INT IDENTITY PRIMARY KEY, SchemaName SYSNAME, ObjectName SYSNAME, IndexName SYSNAME ); INSERT INTO @Temp (SchemaName, ObjectName, IndexName) SELECT s = OBJECT_SCHEMA_NAME(o.[object_id]), o = o.name, i = i.name FROM sys.objects AS o INNER JOIN sys.indexes AS i ON o.[object_id] = i.[object_id] INNER JOIN ( SELECT [object_id], index_id, row_count = SUM(row_count) FROM sys.dm_db_partition_stats GROUP BY [object_id], index_id ) AS s ON o.[object_id] = s.[object_id] AND i.index_id = s.index_id WHERE o.is_ms_shipped = 0 AND i.index_id >= 1 ORDER BY s.row_count DESC, s, o, i; DECLARE @CurrentRowID INT, @s NVARCHAR(MAX) = N''; SELECT @CurrentRowID = MIN(RowID) FROM @Temp; WHILE @CurrentRowID IS NOT NULL BEGIN SELECT @s += CHAR(13) + CHAR(10) + N'ALTER INDEX ' + QUOTENAME(IndexName) + ' ON ' + QUOTENAME(SchemaName) + '.' + QUOTENAME(ObjectName) + ' REORGANIZE;' FROM @Temp WHERE RowID = @CurrentRowID; SELECT @CurrentRowID = MIN(RowID) FROM @Temp WHERE RowID > @CurrentRowID; END
Colleague #4
DECLARE @Row INT = 1, @s NVARCHAR(MAX) = N''; CREATE TABLE #IndexList ( RowID INT IDENTITY(1,1) ,SchemaName SYSNAME ,TableName SYSNAME ,IndexName SYSNAME ); INSERT INTO #IndexList ( SchemaName , TableName , IndexName ) SELECT s = OBJECT_SCHEMA_NAME(o.[object_id]), o = o.name, i = i.name FROM sys.objects AS o INNER JOIN sys.indexes AS i ON o.[object_id] = i.[object_id] INNER JOIN ( SELECT [object_id], index_id, row_count = SUM(row_count) FROM sys.dm_db_partition_stats GROUP BY [object_id], index_id ) AS s ON o.[object_id] = s.[object_id] AND i.index_id = s.index_id WHERE o.is_ms_shipped = 0 AND i.index_id >= 1 ORDER BY s.row_count DESC, s, o, i; WHILE @Row <= (SELECT MAX(RowID) FROM #IndexList) BEGIN SELECT @s += CHAR(13) + CHAR(10) + N'ALTER INDEX ' + QUOTENAME(IndexName) + ' ON ' + QUOTENAME(SchemaName) + '.' + QUOTENAME(TableName) + ' REORGANIZE;' FROM #IndexList WHERE RowID = @Row; SET @Row = @Row + 1; END DROP TABLE #IndexList;
I validated that the resulting value of @s matched the cursor result in all four cases. I don't know about you, and maybe I'm just being dense, but I had to think a lot harder about that than I would have with a cursor, cumbersome syntax and all. As far as I'm concerned, based on these four submissions from esteemed colleagues, constructing a while loop to solve this problem isn't any easier or more straightforward than a cursor. Especially since a DECLARE CURSOR block can easily be constructed for you using Management Studio's templates (or the new snippets feature in SQL Server 2012).
But what about performance? Surely a cursor is slower than a while loop, because it's a cursor, right?
Performance
As I mentioned in a previous article, the cursor usually gets a bad rap for two reasons: (1) folks think a cursor is bad simply because it says DECLARE CURSOR, and (2) people use a cursor (or any row-by-row processing methodology) when it isn't necessary. In cases where it is the best option (e.g. running totals) or it is necessary (e.g. maintenance tasks, or cases where a stored procedure call must be made for every row or conditionally depend on processing that occurred for the previous row), people just say DECLARE c CURSOR FOR … when they should usually be using the most efficient cursor declaration possible (LOCAL STATIC FORWARD_ONLY READ_ONLY). And yes, some will argue that FORWARD_ONLY READ_ONLY could be replaced by FAST_FORWARD, but I prefer the former, because the latter can't be combined with STATIC:
Conflicting cursor options STATIC and FAST_FORWARD.
Now, you are more than welcome to do your own tests with the various cursor options, to see which perform best in your scenario, but I've always come back to the set of options described above. I put my cursor code above into a stored procedure, as well as the two "set-based" concatenations, and the four colleague-provided options. I then ran some performance tests where I measured just duration of each method, executing 1000 times (I ran the middle section three times, then took the average):
SET NOCOUNT ON; GO CREATE TABLE #stats ( rownum INT IDENTITY(1,1), procname SYSNAME, dt DATETIME2 ); GO INSERT #stats(procname,dt) SELECT '-', SYSDATETIME(); GO EXEC dbo.while_cursor; GO 1000 INSERT #stats(procname,dt) SELECT 'cursor', SYSDATETIME(); GO EXEC dbo.while_xmlconcat; GO 1000 INSERT #stats(procname,dt) SELECT 'xml concat', SYSDATETIME(); GO EXEC dbo.while_simpleconcat; GO 1000 INSERT #stats(procname,dt) SELECT 'simple concat', SYSDATETIME(); GO EXEC dbo.while_colleague1; GO 1000 INSERT #stats(procname,dt) SELECT 'colleague 1 while', SYSDATETIME(); GO EXEC dbo.while_colleague2; GO 1000 INSERT #stats(procname,dt) SELECT 'colleague 2 while', SYSDATETIME(); GO EXEC dbo.while_colleague3; GO 1000 INSERT #stats(procname,dt) SELECT 'colleague 3 while', SYSDATETIME(); GO EXEC dbo.while_colleague4; GO 1000 INSERT #stats(procname,dt) SELECT 'colleague 4 while', SYSDATETIME(); GO -- using the new LAG functionality in SQL Server 2012: SELECT procname, duration = DATEDIFF(MILLISECOND, LAG(dt, 1, NULL) OVER (ORDER BY rownum), dt) FROM #stats ORDER BY rownum; GO DROP TABLE #stats; GO
The results (the "winner" highlighted in green):

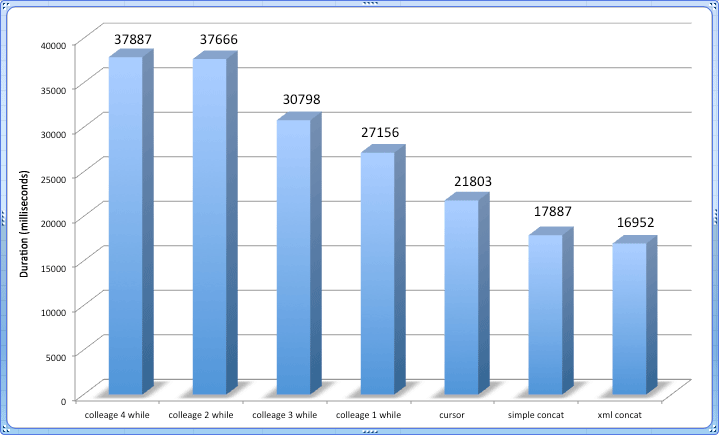
The XML and simple concatenation approaches aside, the cursor clearly outperformed all of the while loops. This may not necessarily be true in simpler scenarios, so I'm not suggesting that a cursor will always be as good as or better than a while loop. But by the same token, I think I've demonstrated that a while loop isn't always faster or easier to write and understand than a cursor.
I would love to hear your experience, especially any examples where a while loop clearly outperforms a cursor or where it is much easier to write or comprehend.
See the full index.
@David be careful, once these <ahem>s realize your while loop is no more or less efficient than a cursor, they'll start looking for WHILE, too.
I googled this 'cos I've asked a team member to replace a cursor with a while loop. Why? Not because I'm against cursors per se, but simply because I know it'll get through the QA process (another team) more easily.
Within the loop there's dynamic sql (hence the need for the cursor), but if I send through code with 1) a cursor and 2) dynamic sql in the same sql paragraph, they're going to have kittens!
Hence I hide my cursor as a While loop.
(I'm only going to loop through around a dozen rows, so performance isn't my primary concern.)
Men with this article, you have teach me a lot, thank you so much.
Thanks for the article
At the possibility of being flamed, I will say that 'yes. while loops are faster than cursors' (with a caveat further below)
as has been well stated before the issue with cursors is misuse and the attempt to force a database engine optimized for set operations to compute in the form of a loop (some new coders tend to think of cursors as the sql version of foreach)
I should also add to my initial comment that although I am confident while loops are faster than cursors… that completely goes out the window if there is data access inside the while loop…
if you're iterating through a temp table of some form via a while loop, then you've just created a cursor… but with out the niceties of READ_ONLY, FORWARD_ONLY
I fully respect the intent of this article and others like it.
the key always seems to boil down to (most – my safety cop out)
tools are useful so long as you understand how they work and when they are better than other options.
if multiple methods are comparable in a given context, then it comes down to aesthetics and/or religious fervor.
PS. that's the final straw, I'm seriously looking into MERGE now…
I didn't realize that functionality was out there, and I feel like writing my triggers to handle simultaneous inserts/updates/deletes wasn't just foolish paranoia.
@IL, yes that is a limitation of PRINT. If you execute the statement it will not be truncated. And I'm sorry but I have no control over how Community Server (which is the platform under this blog) handles copy / paste of code samples.
Aaron, that is my fault, print has 4000 character limit. I've wrote statement without looking Books online like a newbie 🙂
Dear Aaron,
Examples are wonderful! But for me as SQL newbie it's a pain to copy them to SSMS:
1) select script-copy-paste to SSMS results in one long line mixed along with comments. Even if you divide code and comments to synctactically right parts, there is no built-in feature to format the code. SSMS "Delete horizontal white space" feature is useful here, but it does the work in nasty way removing sole spaces completely. It would be nice to be able to copy scripts while preserving format or optionally download them.
2) something wrong is with the string variable the first script besides you declare it as @sql and use as @s the result output of "print @sql" is truncated to 4000 symbols. The last line is "ALTER INDEX [PK_ImportPensEDVSum] ON [dbo].[_". Is it a feature of SSMS to truncate strings when printing?
Thank you!
Uri,
How could I know? Both Oracle and SQL Server are closed source, so there is no way for an outsider to learn why they perform the way they do.
Great Article Aaron,
The "No Cursors" mantra is, like many others, the product of misunderstanding the underlying problem. I was told I should replace a maintenance cursor with ms_ForEachDb and ms_ForEachTable. I asked the reviewer to explain exactly how the procedures managed to cycle through the databases and tables with out some form of looping. As expected there was hem-haw and a fall back to "Cursors are Bad". The same response the narrow minded used to kill the GOTO. In a different session the same reviewer was unable to explain to me why his prefered nested if-Else- continue were preferrable to a single If GoTo.
If the problem is RBAR then find a set based solution or recognize that a looping mechanism is a looping mechanism. Which ever method I choose (Cursor, ms_ForEachxxxxx, While, correlated subquery, recursive CTE,..) has dangers, advantages, and drawbacks. One's responsibility as a Professional is to recognize the strengths and pitfalls of each then choose a good option and implement it properly.
The same argument extends to #temp, @temp, With (CTE)
Sunil, there is definitely a segment I've seen who have insisted that a while loop is faster than a cursor. And the majority of folks who insist that a set-based operation is better is because it's "always faster" – but this obviously isn't always true.
smalone003, can you demonstrate this problem using a forward-only, read-only, local and static cursor?
the recommended way to use a cursor is more like this:
Fetch Next from <cursor> into @var
While @@fetch_status <> -1 /* end of cursor */
begin
if @@fetch_status <> -2 /* row missing */
begin
<your code goes here>
end
Fetch Next from <cursor> into @var
end
The problem with @@fetch_status <> 0 is that you kill the cursor over one missing row. This could leave many row unprocessed.
It was beyond the scope of this article to discuss which combinations of options may or may not result in missing rows and it is a very complex subject. Better to always allow for it.
why not use this one
OPEN @cursor
WHILE ( 1=1)
BEGIN
FETCH NEXT FROM @cursor INTO @id_row
if @@fetch_status <> 0 break
— exec pt_set_busy @id_row,'pt_send_mail'
……
END
Wasn't there a pithy "Kill the Cursor" movement around a few years back when SS2005 came out? It was about the time I started learning T-SQL. I remember being berated for using cursors in code as they're A Bad Thing.
However there was little detailed advice as to what to replace them with. The cognoscenti would wave a finger and advise the use of a set-based operation. But if there was no set-based alternative then the next best advice was to use a While loop. After all, that's not a cursor, is it??
I wish this blog post had been around back then! 😉
Many thanks!
Alex
Hmm, I also seen that PL/SQL cursors are very fast, just curios are there so different algorithms in writing cursors or is it something else between Oracle and SQL Server?
PL/SQL cursors are very fast. It is not uncommon to have a PL/SQL cursor over several million rows run as fast as a set based command.
Another alternative is to write a loop in Java or C# – it will be fast too.
I've generally found that a cursor will outperform a while loop. I have no issues using a cursor if I need to process something in a sequential process. ( or row by row ). Although it's a while ago when I did compares I seem to recollect that a while loop and a cursor handle locking/transactions differently; as far as I remember in the process I was performing the while loop made everything into one transaction whilst the cursor didn't – but it was about 10 years ago.