
In SQL Server 2000, INFORMATION_SCHEMA was the way I derived all of my metadata information – table names, procedure names, column names and data types, relationships… the list goes on and on. I used system tables like sysindexes from time to time, but I tried to stay away from them when I could.
In SQL Server 2005, this all changed with the introduction of catalog views. For one thing, they're a lot easier to type. sys.tables vs. INFORMATION_SCHEMA.TABLES? Come on; no contest there – even on a case insensitive collation where you don't have to make those ugly upper-case words consistent. But further to that, I found them generally easier to use, in addition to including feature and implementation details that are not covered by the INFORMATION_SCHEMA views. A few examples:
IDENTITY columns
Here are the columns available in the INFORMATION_SCHEMA.COLUMNS view:
TABLE_CATALOG TABLE_SCHEMA TABLE_NAME COLUMN_NAME ORDINAL_POSITION COLUMN_DEFAULT IS_NULLABLE DATA_TYPE CHARACTER_MAXIMUM_LENGTH CHARACTER_OCTET_LENGTH NUMERIC_PRECISION NUMERIC_PRECISION_RADIX NUMERIC_SCALE DATETIME_PRECISION CHARACTER_SET_CATALOG CHARACTER_SET_SCHEMA CHARACTER_SET_NAME COLLATION_CATALOG COLLATION_SCHEMA COLLATION_NAME DOMAIN_CATALOG DOMAIN_SCHEMA DOMAIN_NAME
Nothing in there about IDENTITY properties. Whereas in sys.columns, we have the is_identity column, as well as the catalog view sys.identity_columns, with all kinds of additional information. Now, it should be no surprise that this data is missing from the INFORMATION_SCHEMA views, since IDENTITY columns are proprietary to SQL Server and aren't part of the standard. But if you need to retrieve metadata information, this will often include the need for information about IDENTITY columns, and if you're trying to avoid using the catalog views (or proprietary SQL Server functions like COLUMNPROPERTY), you'll be out of luck.
Indexes, partitions, statistics…
Since these are physical implementation details, there is no coverage anywhere in INFORMATION_SCHEMA. Go ahead, create an index (that is not also participating in a constraint), or partition a table, and try to find any evidence of either of these structures in any INFORMATION_SCHEMA view (including filtered indexes, XML indexes, spatial indexes, fulltext indexes, and include columns). Also try to find out if a table has a clustered index, if a primary key is clustered or non-clustered, or if there are any statistics available. This is all important data, and the person trying to find the information may not have any idea about the line between physical and logical, or why the "recommended" approach to obtaining metadata should treat them differently or ignore physical details altogether.
Non-standard Foreign Key constraints
SQL Server allows something that the standard doesn't allow: foreign key constraints referencing unique indexes. Here is an example:
CREATE TABLE dbo.FKExample ( ColA INT, ColB INT ); CREATE UNIQUE INDEX UQ ON dbo.FKExample(ColA, ColB); CREATE TABLE dbo.FKExampleRef ( ColA INT, ColB INT, CONSTRAINT FK_UQ FOREIGN KEY(ColA, ColB) REFERENCES dbo.FKExample(ColA, ColB) );
To determine these relationships using INFORMATION_SCHEMA views, we'd normally perform a join between INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS, INFORMATION_SCHEMA.TABLE_CONSTRAINTS, and INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE. But since the unique index is not a constraint, there is no data in INFORMATION_SCHEMA.TABLE_CONSTRAINTS, so no way to dig deeper and determine the columns used in the "constraint" without going out to catalog views.
SELECT CONSTRAINT_NAME, UNIQUE_CONSTRAINT_NAME FROM INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS;
CONSTRAINT_NAME UNIQUE_CONSTRAINT_NAME --------------- ---------------------------- FK_UQ UQ
SELECT CONSTRAINT_NAME FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS WHERE CONSTRAINT_NAME = 'UQ' UNION ALL SELECT CONSTRAINT_NAME FROM INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE WHERE CONSTRAINT_NAME = 'UQ';
CONSTRAINT_NAME --------------- 0 row(s) affected.
Because this "constraint" was implemented only as an index, the INFORMATION_SCHEMA views do not contain any further information about it. But we can still get the information using sys.foreign_keys, sys.foreign_key_columns, and sys.columns, just like we would for a foreign key that referenced a unique constraint or a primary key constraint:
SELECT FK = fk.name, FKTable = QUOTENAME(OBJECT_SCHEMA_NAME(fkcol.[object_id])) + '.' + QUOTENAME(OBJECT_NAME(fkcol.[object_id])), FKCol = fkcol.name, ' references => ', PKTable = QUOTENAME(OBJECT_SCHEMA_NAME(pkcol.[object_id])) + '.' + QUOTENAME(OBJECT_NAME(pkcol.[object_id])), PKCol = pkcol.name FROM sys.foreign_keys AS fk INNER JOIN sys.foreign_key_columns AS fkc ON fk.[object_id] = fkc.constraint_object_id INNER JOIN sys.columns AS fkcol ON fkc.parent_object_id = fkcol.[object_id] AND fkc.parent_column_id = fkcol.column_id INNER JOIN sys.columns AS pkcol ON fkc.referenced_object_id = pkcol.[object_id] AND fkc.referenced_column_id = pkcol.column_id ORDER BY fkc.constraint_column_id;
Results:

If you were relying on a similar join within the INFORMATION_SCHEMA views, you would not realize that this relationship existed.
Default constraints
While INFORMATION_SCHEMA.COLUMNS stores the *definition* of a default constraint, nowhere in these views will you find the *name* of the constraint. This can be particularly problematic if you use shorthand and allow SQL Server to name your constraints. Instead you will have to look at sys.default_constraints.
Computed columns
Computed columns are another area where the INFORMATION_SCHEMA views turn a blind eye. Consider the following simple example:
CREATE TABLE dbo.ComputedExample ( a INT, b AS (CONVERT(INT, a + 10)) );
Reviewing the list of INFORMATION_SCHEMA.COLUMNS columns listed above, or just running a query, you can see no place for the definition of the second column, or any discernible difference between the two columns – they're both integers and, apart from COLUMN_NAME and ORDINAL_POSITION, all the column values are identical. In sys.columns, we have a flag called is_computed, and we can retrieve the definition of the column from sys.computed_columns using the following query:
SELECT c.name, cc.[definition] FROM sys.columns AS c LEFT OUTER JOIN sys.computed_columns AS cc ON c.[object_id] = cc.[object_id] AND c.is_computed = 1 WHERE c.[object_id] = OBJECT_ID(N'dbo.ComputedExample') ORDER BY c.column_id;
Results:
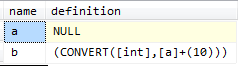
As far as the INFORMATION_SCHEMA views are concerned, b is just an ordinary column.
Sparse columns
Much like computed columns, there is no spot in the INFORMATION_SCHEMA.COLUMNS view to indicate whether a column is sparse or a column_set. In sys.columns you will find the columns is_sparse and is_column_set to quickly identify which columns in which tables have been defined as sparse and how the columns are used.
Module definitions
If you are trying to get the definition for a stored procedure, function, or other module from INFORMATION_SCHEMA, and the definition happens to be greater than 4,000 characters, good luck. This column is truncated to NVARCHAR(4000), even though it is defined as NVARCHAR(MAX). This isn't all that much worse than what the backward compatibility view syscomments does (it stores the definition on separate rows in chunks of 4,000 characters). If you might have to sometimes use sys.sql_modules or OBJECT_DEFINITION() to retrieve the entire definition in one piece, why would you ever want to use a less reliable way?
Sequences
SQL Server 2012 added INFORMATION_SCHEMA.SEQUENCES for the Sequence functionality they added. However, only the information covered by the standard is included in the view. If you want to determine if the Sequence is exhausted, for example, or the current value of the Sequence object, you won't find that from INFORMATION_SCHEMA.SEQUENCES; you'll have to go to sys.sequences anyway. Example:
CREATE SEQUENCE dbo.SequenceExample AS INT MINVALUE 1 MAXVALUE 65535 START WITH 1 CACHE 1000 CYCLE; GO SELECT NEXT VALUE FOR dbo.SequenceExample; GO 3 SELECT current_value, is_exhausted FROM sys.sequences WHERE name = 'SequenceExample';
Results:
![]()
object_id is missing
As we know, much of SQL Server's internal mechanisms identify metadata using surrogate identifiers like object_id, which don't exist in the INFORMATION_SCHEMA views – they are entirely name-based. This makes joins much more cumbersome – instead of:
SELECT /* cols */ FROM sys.tables AS t INNER JOIN sys.columns AS c ON t.[object_id] = c.[object_id];
You have to say:
SELECT /* cols */ FROM INFORMATION_SCHEMA.TABLES AS t INNER JOIN INFORMATION_SCHEMA.COLUMNS AS c ON t.TABLE_SCHEMA = c.TABLE_SCHEMA AND t.TABLE_NAME = c.TABLE_NAME;
It doesn't look like that much more code, but combined with all the other extra typing you're doing, it will add up if you are writing a lot of metadata queries.
Alias type inconsistency
If you use alias types (in spite of my warnings about them), you'll notice some inconsistency. In INFORMATION_SCHEMA.COLUMNS and INFORMATION_SCHEMA.ROUTINE_COLUMNS, for example, the alias name is in a column called DOMAIN_NAME. In INFORMATION_SCHEMA.PARAMETERS, the column name is USER_DEFINED_TYPE_NAME. And in INFORMATION_SCHEMA.SEQUENCES the column is called DECLARED_DATA_TYPE. (With the catalog views, everything maps back to sys.types columns user_type_id and/or system_type_id.) Now, the view INFORMATION_SCHEMA.COLUMN_DOMAIN_USAGE has a row for every usage within tables, views and table-valued functions – however your joins or unions to pull this information are going to be quite convoluted if you have to look up how the column is referenced differently in every single view.
Misleading information about updatable views
While there are a whole bunch of criteria used to determine whether a view is updatable (including details in the query that is trying to perform the update, such as whether the columns affected reside in only one of the base tables affected by the update), the INFORMATION_SCHEMA.VIEWS view will *always* tell you a view is not updatable.
Other ramblings
Further to these things that I have observed, Microsoft seems to be going out of its way to steer you away from the INFORMATION_SCHEMA views as well. For example, the INFORMATION_SCHEMA.SCHEMATA topic says:
** Important ** Do not use INFORMATION_SCHEMA views to determine the schema of an object. INFORMATION_SCHEMA views only represent a subset of the metadata of an object. The only reliable way to find the schema of an object is to query the sys.objects catalog view.
And the INFORMATION_SCHEMA.TABLES topic says:
** Important ** only reliable way to find the schema of an object is to query the sys.objects catalog view. INFORMATION_SCHEMA views could be incomplete since they are not updated for all new features.
The warnings originally stated that the INFORMATION_SCHEMA views were incorrect, but they fixed the wording after I complained here.
Also, the System Information Schema Views topic says:
The information schema views included in SQL Server comply with the ISO standard definition for the INFORMATION_SCHEMA.
…
Important
Some changes have been made to the information schema views that break backward compatibility. These changes are described in the topics for the specific views.
It is important to note that this statement of compliance was true for ANSI/ISO SQL-92, but not for revisions that have been made to the standard since then. There are changes present in SQL:1999, for example, that have not been reflected in the SQL Server implementation. And as I've highlighted above, there are many features in SQL Server that fall outside of the SQL standard that also do not appear within the INFORMATION_SCHEMA views.
Summary
So you don't have to remember when you have to fall back to the catalog views to get a complete picture, do what I do, and avoid the INFORMATION_SCHEMA views altogether. This will make your programming more consistent; after all, why use the catalog views only when you HAVE to?
I know that for some of you this is counter-intuitive because you deal with other RDBMS platforms where you also use INFORMATION_SCHEMA. I don't really have a good answer for folks in that boat, except to be cognizant of the inconsistencies and omissions on each platform, and perhaps to resign yourself to learning the metadata approach relevant to each platform rather than try a one-size-fits-all approach.
@AaronBertrand I am using SQL 2000 Since last 4 or five days i am getting a error msg when i want to try to open tables in my database in Enterprise Manager. Even if i run sp_Help than same error msg occurs please give me some solution for this problem .i already tried database restore on Another server but same proble exist
Msg is given below:
Location: q:\SPHINX\NTDBMS\storeng\drs\include\record.inl:1447
Expression: m_SizeRec > 0 && m_SizeRec <= MAXDATAROW
SPID: 51
Process ID: 1652
Connection Broken
@L While I agree about standards compliance (and I argue for that in other posts, such as using COALESCE over ISNULL, <> over !=, and CURRENT_TIMESTAMP over GETDATE()), sometimes consistency within a specific platform is subjectively more important than consistency over all platforms. Outside of Joe Celko's classroom and people who truly write apps that need to submit the same ad hoc SQL to multiple RDBMS platforms, the number of times in my 20-year career where I've seen a legitimate need for cross-platform, fully standards-compliant SQL could fit on one hand.
I don't consider it "growing my skills" to learn how to deal with the limitations of INFORMATION_SCHEMA and memorizing when I need to look elsewhere for metadata information. And no, I work for a company that builds software for SQL Server, so switching to Oracle because it pays more or assuming that PostgreSQL is the "best" platform are both laughable.
Would my title make you feel better if it said "MY case against INFORMATION_SCHEMA views BUT ONLY IF YOU ARE USING SQL SERVER?" The content should make it fairly obvious that I'm not talking about industry-wide standards but rather for coding against SQL Server specifically. If through reading that and my replies to your comments you still don't get that, /*shrug*/.
@AaronBertrand, I think it's a matter of point of view.
I, as a DBA, who works in SQLServer, Oracle, MySQL on bad days and PostgreSQL on the good ones, would rather keep as much standards-compliant SQL as possible, only adding the necessary vendor-specific "mess" where absolutely necessary.
As a person who likes growing my skills, limiting myself to the Microsoft-Sybase interpretation of an RDBMS is not an option.
I guess if you look at it from a strictly professional point of view, I wonder why you wouldn't go Oracle since it pays more.
If it's outside the corporate world, why not use the best tools available, like PostgreSQL –
Basically, you and I have very different definitions of what constitutes a meaningful compromise.
I just wanted to highlight how your title implies your personal compromise should be a standard.
@L imho I think I have shown why sys.* should be the rule, not the exception, ***in SQL Server.*** If you're using some other platform, or you need to write code that works on all platforms, then this post is not for you. (I'd still be curious how you're going to write code that gets index information, for example, and works on MySQL, SQL Server, and PostgreSQL.)
Can you name anything you can get from INFORMATION_SCHEMA that you can't get from sys.*? My point was that – if you are only working with SQL Server, at least – if you have to use sys.* in some cases (e.g. indexes), why not just use them all the time? I don't like intentionally choosing between equivalent things in some cases when you have to choose the opposite way in other cases. I would prefer to code consistently against sys.* whether what I happen to need today is only available there or might also be available from INFORMATION_SCHEMA…
The title could have been "why information_schema isn't enough in SQLServer".
This largely seems to be only about how SQLServer's information_schema is incomplete.
As some have already mentioned, if you're not just working with Microsoft's semi-standards-abiding flavor of SQL, sys.* is good to know about, but clearly meant for exceptions rather than the rule.
@Brian, I'm not in any way suggesting there is only one right answer. I'm not writing a rule book that everyone needs to follow, I'm expressing an opinion in a blog post. These are the reasons *I* stopped using INFORMATION_SCHEMA. If those reasons aren't compelling enough for you, and you're okay with inconsistent programming models – switching models when INFORMATION_SCHEMA doesn't give you the answers you want – that's perfectly fine with me.
Avoiding INFORMATION_SCHEMA entirely is an even worse one-size-fits all solution for most (read high-level) structure questions than always using it.
It seems disengenuous to call out brevity as a benefit of the sys tables. They require much more joining, and use of object_name()/object_id() than the INFORMATION_SCHEMA views that already do that work. Joining on a single implementation-specific identifier truly is simpler than the FQON, but when do you need to join on the INFORMATION_SCHEMA views? At least for ad-hoc queries (the only reason to endorse brevity), the questions start from the object names, not their IDs.
Sure, when I need to get much lower-level, or deal with Microsoft-specific extensions, sys is clearly the way to go. (It's not a surprise that Microsoft's standard support continues to be more than a decade behind, but they have still been improving at the best rate they ever tend to manage.)
Often, my problem is that I have to interact with a system written by a vendor who (like too many) does not seem to understand RDBMSs or normalization at all, and rather than defining primary and foreign keys, has only defined unique indexes, to a point where it would be impossible to fix it now. This puts me in a position where I've got a column that *appears* to be a "foreign key" (hopefully not a value hard-coded in their client application) that I need to find the "primary key" table, shopping through hundreds of tables and many scores of thousands of columns. For those needs, INFORMATION_SCHEMA.COLUMNS is the right tool for the job. The sys tables are just too much additional effort.
It seems odd to me to suggest everyone else's use case is similar enough to yours that there is only one right answer. As an admonition against blind exclusive usage of INFORMATION_SCHEMA, and it's limitations, this is great, but I'd avoid overgeneralizing the suitability of one solution over another.
@SALMAN no, SQL Server does not track that information anywhere – you need to do that yourself via default constraints, triggers, auditing…
@Salva sorry about the delay, what version of SQL Server are you using?
Is there any way to look the date and time for each table entry by using information_schema
Hi Aaron, I have some problems with TSQL. I am looking how I can find the sourcefield from an alias in a view. Is there a possibility to get the information? For example:
Select Name AS Company, Lastname as AP
from Company INNER JOIN Person ON Company.ID = Person.ID_AP
Now I would like to get following information:
Alias Table Sourcefield
Company Company Name
AP Person Lastname
I also avoid them for performance reasons.
As they don't expose object ids joining between them can be massively inefficient and lead to horrible plans.
Example:
http://dba.stackexchange.com/questions/15596/sql-query-slow-down-from-1-second-to-11-minutes-why
Hi Aaron,
Very interesting blog, however, I'm trying to determine is it possible that the INFORMATION_SCHEMA views will return wrong information in regards to primary key?
I used the following query
SELECT @keys = Stuff((SELECT ',' + KCU.COLUMN_NAME
FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS AS tc
JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE AS kcu
ON kcu.CONSTRAINT_SCHEMA = tc.CONSTRAINT_SCHEMA
AND kcu.CONSTRAINT_NAME = tc.CONSTRAINT_NAME
AND kcu.TABLE_SCHEMA = tc.TABLE_SCHEMA
AND kcu.TABLE_NAME = tc.TABLE_NAME
WHERE tc.CONSTRAINT_TYPE = 'PRIMARY KEY'
AND TC.TABLE_NAME = @objname
ORDER BY kcu.ORDINAL_POSITION
FOR XML PATH(")),1,1,");
and I am wondering if there is a chance for it to return NULL for the table that does have a primary key? Do you see where it may fail?
For details please see (and reply, if possible) this thread
http://social.msdn.microsoft.com/Forums/en-US/transactsql/thread/732bd071-2c1f-4c23-9215-4ff3822c63c3
By 'does not work' I mean that if the column is type money, the declaration returns "money(8)", instead of "money". I agree that errors in RADIX does not justify using it. Just looking for a solution. system_type_name from sys.dm_exec_describe_first_result_set_for_object looks like exactly what is needed.
Re: varchar. I've never seem varchar declared without a length, until I saw it in the RADIX post. I was wondering what results from this so I googled it, only to find the article that you just linked to. Har.
I'm working on a dynamic ETL system that creates a staging database mostly typed in varchar, so I can get everything into SQL Server before dealing with datatype issues. I've been using SSIS to great frustration (for many reasons, not the least of which is that it takes literally 25 minutes for the package to open), so will mostly be cutting that out, and using varchar Staging database with BULK INSERT from text files, and recursive MERGE JOIN statements. The result is something efficient with better error handling/restartability which dynamically adjusts to schema changes. There are a few specifics to our environment, but otherwise would apply to many situations. I plan to keep and use the core logic for quite some time to come.
Great posts BTW.
@Kyler your explanation seems fuzzy to me. I'm not sure what "does not work" means, and I'm not sure how including a completely inaccurate value in the output justifies not having to deal with a null. The way to do this – no matter where you get your metadata – is to use CASE expressions.
In the future the way to do this is to use the new metadata functionality introduced in SQL Server 2012. It returns friendly data type names precisely so that you don't have to do all this CASE juggling.
/blogs/aaron_bertrand/archive/2010/12/20/sql-server-v-next-denali-metadata-discovery.aspx
Also, please stop using CAST(… AS VARCHAR). Define your length.
/blogs/aaron_bertrand/archive/2009/10/09/bad-habits-to-kick-declaring-varchar-without-length.aspx
I guess it comes down to knowing which column declarations require numeric values in parenthesis. The COALESCE with the …RADIX column handled that because it was NULL for values that should not have numbers following the type. But it suffers from the problems pointed out. So, to use sys.columns effectively, perhaps put in a case statement to not show numbers when type is money, tinyint, smallint, int, bigint, float… which others? It would be nice if there was a system way to know which should not have numbers, so that future data types will be accommodated automatically, rather than hardcoding it.
More detail on my previous question. The following works properly for int, money, float, etc…
SELECT
' ['+column_name+'] ' + data_type + case data_type
when 'sql_variant' then "
when 'text' then "
when 'decimal' then '(' + cast(numeric_precision_radix as varchar) + ', ' + cast(numeric_scale as varchar) + ')'
else coalesce('('+case when character_maximum_length = -1 then 'MAX' else cast(character_maximum_length as varchar) end +')',") end
FROM INFORMATION_SCHEMA.COLUMNS
The following does not work for the same types of columns…
SELECT '['+t2.name+'] ' + t3.name + CASE t3.name
WHEN 'sql_variant' THEN "
WHEN 'text' THEN "
WHEN 'decimal' THEN '(' + cast(t2.precision as varchar) + ', ' + cast(t2.scale as varchar) + ')'
ELSE coalesce('('+ CASE WHEN t2.max_length = -1 then 'MAX' else cast(t2.max_length as varchar) END +')',") END
FROM sys.tables t1 inner join sys.columns t2 on t1.object_id = t2.object_id inner join sys.types t3 on t2.user_type_id = t3.user_type_id
@Kyler I think there is an error in that script that mentions RADIX, and I don't think you want to use it for anything. Two people pointed that out in a comment, but the OP never fixed it (I just did). Always pay attention to the comments in addition to the answers, as there is often valuable information there. Here is why you don't want to use RADIX:
USE tempdb;
GO
CREATE TABLE dbo.fooblbl(a NUMERIC(12,4), b NUMERIC(6,2), c NUMERIC(4,1));
SELECT precision, scale FROM sys.columns WHERE object_id = OBJECT_ID('dbo.fooblbl');
SELECT numeric_precision, numeric_scale, numeric_precision_radix
FROM INFORMATION_SCHEMA.COLUMNS WHERE table_name = 'fooblbl'
Results:
precision scale
12 4
6 2
4 1
numeric_precision numeric_scale numeric_precision_radix
12 4 10
6 2 10
4 1 10
Anyone know what the replacement is for INFORMATION_SCHEMA.COLUMNS.NUMERIC_PRECISION_RADIX? I am trying to generate create table statements, similar to http://stackoverflow.com/questions/21547/in-sql-server-how-do-i-generate-a-create-table-statement-for-a-given-table, but want to use sys.columns.
Thanks for this Aaron.
I've always been confused by which to use where.
The templates that come by default in SSMS use INFORMATION_SCHEMA when checking the existence of an object (see Drop/Create Stored Procedure templates), but then go and use the statement you outlined above about not using INFORMATION_SCHEMA to determine the schema of an object.
I never got that one.
Thanks Chris, just one counter-point, the logical argument rarely comes into play in my experience. In customer environments if I'm looking at schema it involves both. Even if there is an odd case where I'm only concerned about logical constructs, why should I change my programming methodology for just those cases, when the catalog views *also* completely cover the logical design?
Excellent coverage. A good guideline can be if a query can be, or 'should be' scoped to only the logical design of the database, only the information_schema views should be used. You then limit yourself to objects that affect the logical structure, and should have some reasonable level of expectation of being able to share that query across database platfroms. If the query involves the physical design as well, then go for it using the catalog views, and don't have any expectation of being to share the exact code across platforms, only the concept.
A salient point is speaking about 'indexes':
"Go ahead, create an index (that is not also participating in a constraint), or partition a table, and try to find any evidence of either of these structures in any INFORMATION_SCHEMA view". Exactly! the index doesn't affect the logical design. In practice, a few blurry edges – that whole 'unique index' throws me for a loop as it is a physical design consideration that has logical impacts. Would it be good practice to have a corresponding unique constraint to any unique indexes?
I like the ANSI compliance bit where it works and makes sense. For example, I'm glad that OFFSET was implemented in a standard way, unlike how MySQL did it. Microsoft is guilty of the same kind of thing over time (TIMESTAMP still bites us today, for example). I'm also glad that they're filling out the missing spots in the standard regarding window functions.
That said, I'm not a big fan of letting ANSI compliance hold us back. If there are features that the standard doesn't cover, Microsoft can find itself in a pickle – especially when the standard finally adds those things. Should it implement those changes now, and risk non-compliance later, or should it stifle functionality growth to ensure compliance? If the latter, how long do we wait for the standard to catch up?
I think there is a case for adhering to the standard where possible, and I would never advocate contradicting the standard. But I don't believe it will ever be practical to have 100% compliance, no matter how much resources you put behind the thing. You are always going to have areas that are not practical to implement, and you're always going to be adding or enhancing features beyond the standard.
I'm in the same boat. I used to use them extensively and now I almost never use them. For the same reasons you outlined. I believe that they are maintained for ANSI SQl compliance only and this brings up another question. Is there any real value in being ANSI SQL compliant (to a limited degree)? Should SQL Server just drop the ANSI compliance altogether?
Yes, that is true. Like IDENTITY columns, the primary goal is not to represent a sequence without gaps, but rather just ensure uniqueness. If they went out of their way to prevent gaps, it would mean that every time you change a table they'd have to renumber the column_ids *and* go out and fix all the column_id references in all the other tables and views across the schema (think of all the column_id references used in indexes, foreign keys and other constraints, even dependency metadata).
If you want to present a gapless ordinal position list to users without revealing that the table has changed, provided that they weren't going to use that to do programmatic lookups in the metadata themselves, you could simply say ORDINAL_POSITION = ROW_NUMBER() OVER (ORDER BY column_id) …
Thanks! Didn't saw that before!
seems that column_id always grows, but can have gaps, if drop some column in middle of table.
Janis, you can get the same information from sys.columns.column_id. This column doubles as the column identifier and the ordinal position of the column.
Is there way to find ordinal possition in other way than querying INFORMATION_SCHEMA.COLUMNS?
Select ORDINAL_POSITION
From INFORMATION_SCHEMA.COLUMNS
Amen. They've thrown me for loops on numerous occasions.