
For the last part in my series on using a calendar table, and with some help from Itzik Ben-Gan, I describe how you can solve complex scheduling problems.

For the last part in my series on using a calendar table, and with some help from Itzik Ben-Gan, I describe how you can solve complex scheduling problems.

In this part of my "using a calendar table" series, I talk about filling gaps and identifying gaps and islands.

It seems a lifetime ago I wrote about creating a calendar table; now I've started a new series showing how to use the calendar table. In the first installment, I deal with business day problems.

A not exactly innovative post about using Temporal Tables functionality to automatically update a LastModified column.
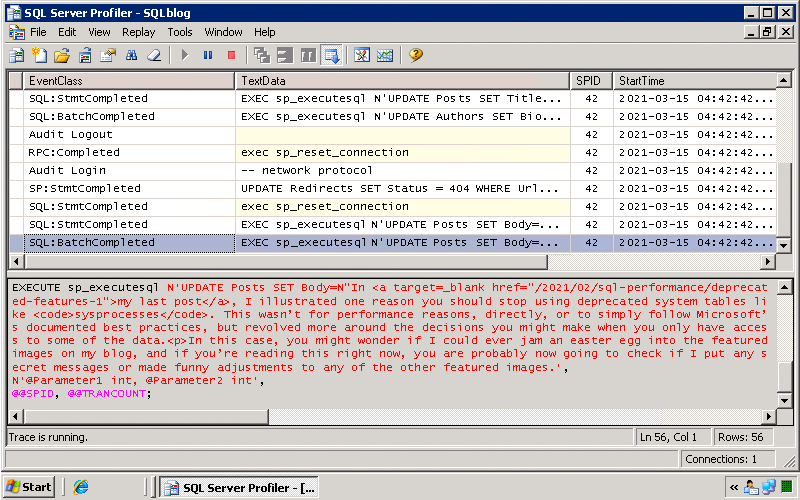
I use a real-world example showing why you shouldn't use deprecated functionality like SQL Server Profiler.

For this month's T-SQL Tuesday, I talk about my two least favorite data types: money and datetimeoffset.

In this tip, I talk about cases where SQL Server will interpret YYYY-MM-DD as YYYY-DD-MM, which is less than optimal.
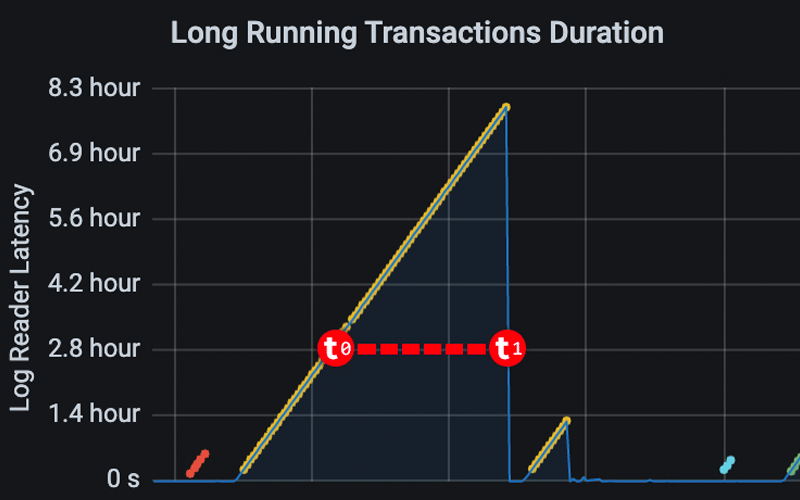
I talk about one scenario where the system table sys.sysprocesses almost led us down the wrong path.
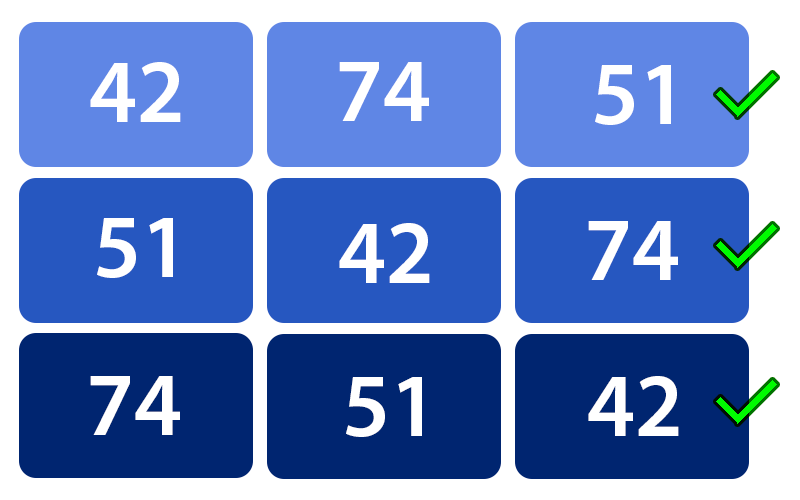
After seeing this question pop up on forums multiple times, I wrote a quick tip about enforcing unique constraints where order doesn't matter.

After a question on #sqlhelp, I dug into what could be making sys.partitions slow, and how they might get the required information in a more efficient way.
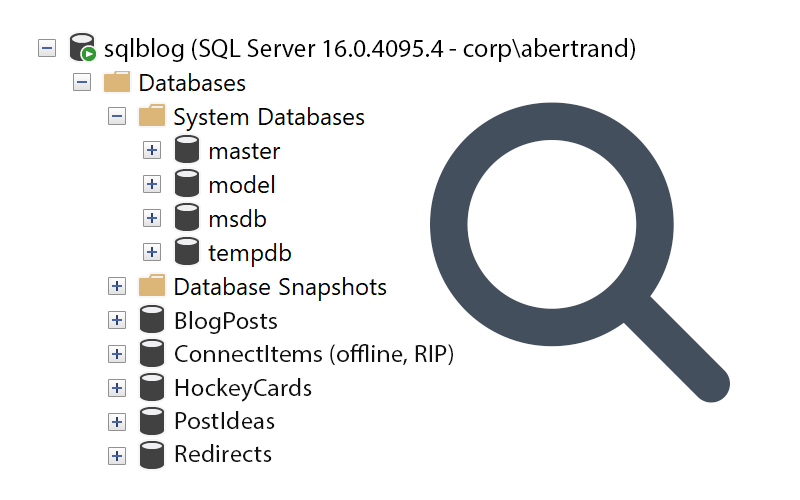
While I previously promoted a way to stop storing database name in your Extended Events sessions, there's an upside to collecting it: the ability to filter. Read on for more info.

For this month's T-SQL Tuesday I talk about a few distractions I enjoy when not slinging T-SQL.
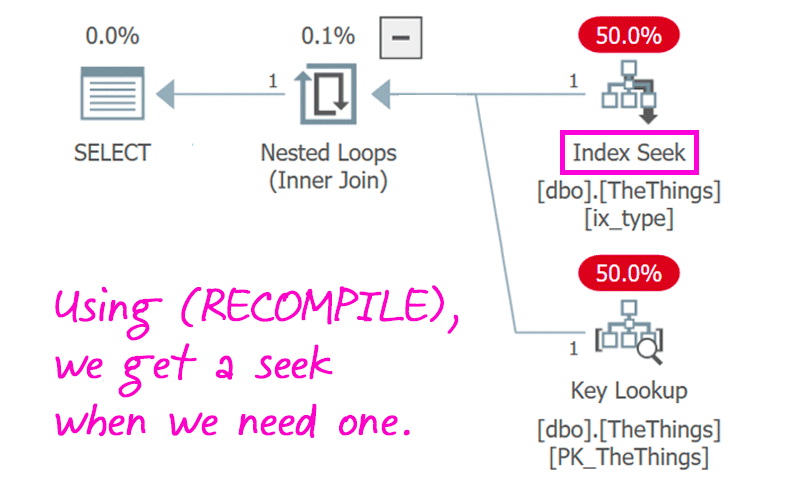
I explain a recent case where sp_prepare came in handy: trying to validate a plan guide's impact.
I talk about a trade-off when using collect_database_name for DDL events captured by Extended Events.

I recognize this year's recipient of my Community Influence of the Year award.

This month's T-SQL Tuesday is about what we've learned from presenting. I give an embarrassing account about how I learned to be prepared and not go off script.

This month's T-SQL Tuesday is about how we are dealing with the madness that is 2020.

I recently came across an interesting issue with CHECKDB snapshots, as well as a bit of information missing from the documentation.

More background on ParamParser, some recent changes, and several syntax examples.
Rob Volk asks us to share our favorite analogies that help explain database-related concepts to less technical folk.
I've made the GitHub repository for ParamParser public; here is some more background behind this project.

I've started a new project to parse default values from stored procedures and functions.

If you ever use sys.sp_columns as shorthand for catalog views, please don't, and I'll tell you why.

Whether you love or fear new PC builds, it's not every day a Mac person builds a Windows PC. See the parts I chose and how much more economical this option can be.
This month, Elizabeth Noble asks us to talk about things we have automated (or want to automate). I talk about a project I just started, called GetAllTheErrorLogs.
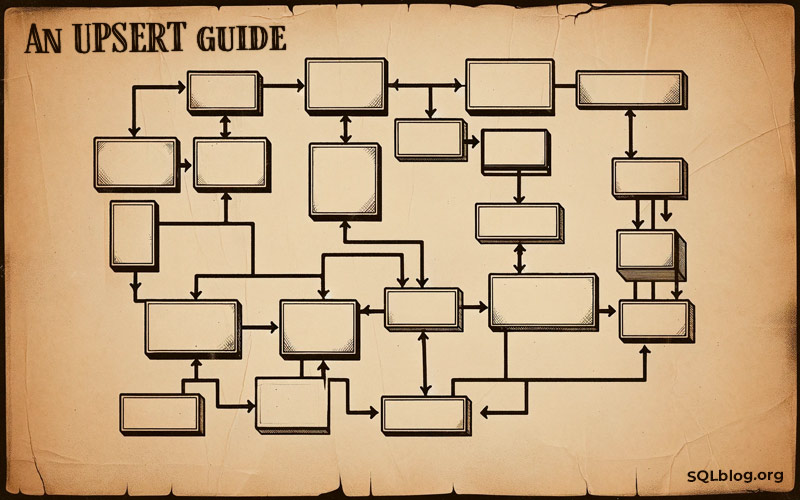
There is a very common anti-pattern you should avoid, involving updating a row if it exists and inserting it if it doesn't. See how to avoid race conditions and deadlocks.

Altering a fixed-width column on a large table can often mean either a lot of planning or a lot of downtime, but in some scenarios there may be an easy out.

We had a case where we increased a varchar column's size, ONLINE, but it caused significant downstream effects. See why.

There are some limitations with STRING_SPLIT that could be overcome, but the cleanest solution might be to add a new function altogether.

My daughter surprised me with a question about work last week, and I answered her by invoking Taylor Swift.

Find out about the replacement I wrote for the undocumented, unsupported, and ill-advised system procedure, sp_MSforeachdb.

A quick update on some maintenance I performed on the site over the weekend.

Updated in 2020 with a few new entries, this is a fairly comprehensive list of the reasons behind various 18456 error messages.

For this month's T-SQL Tuesday, Kerry Tyler asks us to talk about something that went wrong. I had plenty to choose from, and went way back to ~2002 for this short story.

Encourage PASS to show they are a diverse and inclusive community.

See two ways you can make the relevant data in the system_health session last longer and not get drowned out by noise.

For this month's T-SQL Tuesday, let's talk about something you're more likely to hear from a carpenter: Measure twice, cut once.
See how to work around some of the blockers for replacing legacy UDFs with STRING_SPLIT.

Access the system_health file target without tedious string parsing gymnastics.

This series shows how I determine the amount of data distributed across indexes, files, filegroups, and partitions.

Dig into an intermittent stack dump involving an aggregate query against a heap with a LOB column.

Discover some undocumented or unsupported behavior you might not even realize you're relying on.

See a quick T-SQL script for determining how often Cinco de Mayo falls on Taco Tuesday.

I continue a series where I dig into how data is distributed across indexes, files, and filegroups.

I talk about a recent change where I started turning on indirect checkpoints across all user databases.

I finish up my series on replacing the default trace with views to simplify consumption and a caveat about reports in SSMS.

See the stored procedure I wrote to help me put all file, filegroup, and index information in one place.

I continue my series on replacing the default trace with a more efficient and more complete Extended Events session.