
 For this month's T-SQL Tuesday, Steve Jones asks us to talk about problems we've solved using window functions.
For this month's T-SQL Tuesday, Steve Jones asks us to talk about problems we've solved using window functions.
When I first used window functions back in SQL Server 2005, I was in awe. I had always used inefficient self-joins to calculate things like running totals, and these really didn't scale well with size-of-data. I quickly realized you could also use them for ranks and moving averages without those cumbersome self-joins, elaborate sub-queries, or #temp tables. Those all have their place, but window functions can make them feel old-school and dirty.
If you're brand new to window functions, I recommend spending some time with this tutorial from Koen Verbeeck. If you're already familiar, read on.
Using mostly Stack Exchange Data Explorer, I'll show a few examples of problems I've solved in the past using window functions.
Ranking rows
RANK() is a pretty simple one. In this example, let's say we want the top 5 Stack Overflow users by reputation:
SELECT TOP (5) Id, DisplayName, Reputation, rk = RANK() OVER (ORDER BY Reputation DESC) FROM dbo.Users ORDER BY Reputation DESC;
The results of this query:
![]()
The scores are all unique, but RANK() would have shown the same value if there happened to be ties. Which may or may be intended or expected.
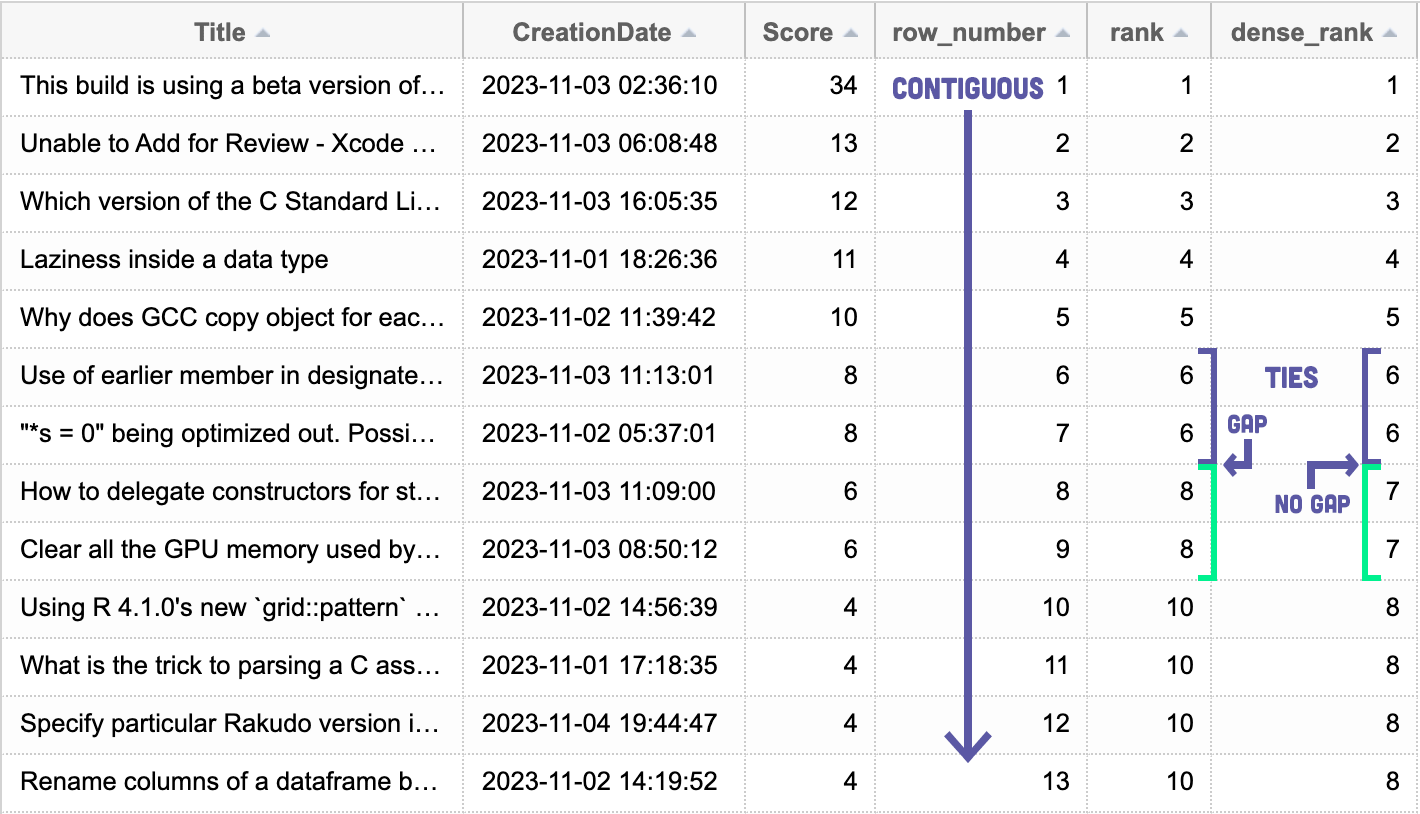
Let's do something a little more interesting to show how RANK(), DENSE_RANK(), and ROW_NUMBER() work: we'll ask for the top 20 questions, this month, by score:
SELECT TOP (20) Title, CreationDate, Score, [row_number] = ROW_NUMBER() OVER (ORDER BY Score DESC), [rank] = RANK() OVER (ORDER BY Score DESC), [dense_rank] = DENSE_RANK() OVER (ORDER BY Score DESC) FROM Posts WHERE PostTypeId = 1 -- Question AND CreationDate >= DATEFROMPARTS(YEAR(GETDATE()),MONTH(GETDATE()),1) ORDER BY Score DESC;
The results of this query show that ROW_NUMBER() produces contiguous results, while RANK() and DENSE_RANK() produce slightly different results: the former leaves gaps when there are ties, and the latter leaves no gaps:
Top N per group
When grouping or joining it can be tedious to get just the first or just the newest row for anything. Let's take a simple example where I want to know the date and title of the last question posted to Stack Overflow by me or by Jon Skeet:
WITH src AS ( SELECT Id, Title, CreationDate, OwnerUserId, rn = ROW_NUMBER() OVER ( PARTITION BY OwnerUserId ORDER BY CreationDate DESC ) FROM Posts WHERE PostTypeId = 1 -- Question AND OwnerUserId IN (61305, 22656) -- me, Jon Skeet ) SELECT Id, Title, CreationDate, OwnerUserId FROM src WHERE rn = 1;
The window function lets me find the newest question grouped ("partitioned") by OwnerUserId. Here are the results:

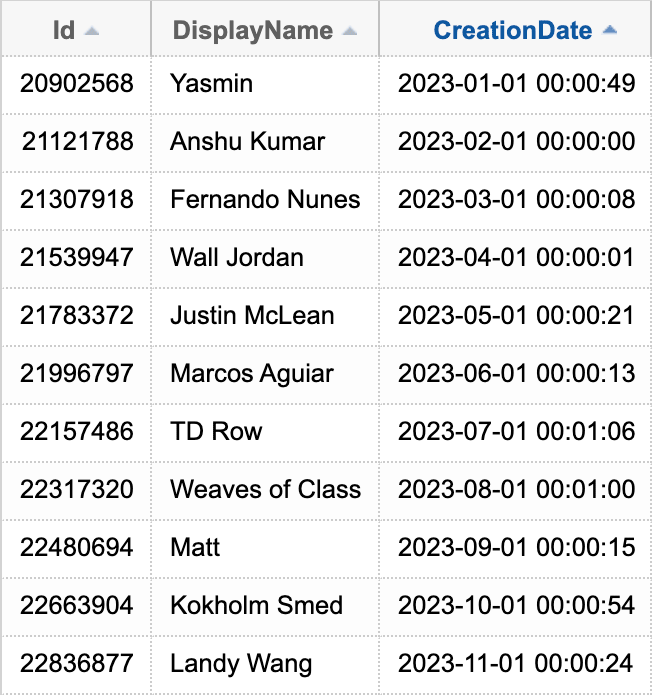
You can put more complex expressions in the OVER() clause, too. For example, if I wanted to find the first user created in each month this year, I could write this query:
WITH UsersThisYear AS ( SELECT Id, DisplayName, CreationDate, rn = ROW_NUMBER() OVER ( PARTITION BY DATEFROMPARTS (YEAR(CreationDate), MONTH(CreationDate), 1) ORDER BY CreationDate ) FROM Users WHERE CreationDate >= DATEFROMPARTS(YEAR(GETDATE()),1,1) ) SELECT Id, DisplayName, CreationDate FROM UsersThisYear WHERE rn = 1 ORDER BY CreationDate;
Results:
I've solved a lot of other people's problems with ROW_NUMBER(), too. Here are 197 answers by me that, for one reason or another, contain WHERE rn = 1.
Running totals
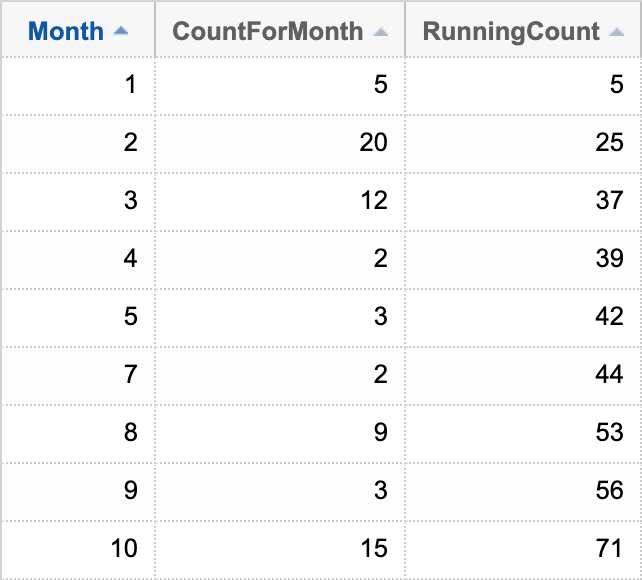
Another luxury of modern versions is the ability to use window frames in the OVER() clause. We can use this technique to calculate aggregates over a large number of rows while still only reading those rows once. For example, if I wanted to see how many answers I've posted for each month in 2023, with a running total, I can write this query:
WITH AaronPosts AS ( SELECT [Month] = MONTH(CreationDate), PostCount = COUNT(*) FROM Posts WHERE CreationDate >= '20230101' AND CreationDate < '20240101' AND OwnerUserId = 61305 AND PostTypeId = 2 -- answer GROUP BY MONTH(CreationDate) ) SELECT [Month], CountForMonth = PostCount, RunningCount = SUM(PostCount) OVER ( ORDER BY [Month] ROWS UNBOUNDED PRECEDING ) FROM AaronPosts ORDER BY [Month];
Results:
You can see a few of the cumbersome ways we used to have to do this in this answer (along with some links to posts about performing grouped running totals, and why you want to avoid the RANGE keyword).
SQL Server 2022 enhancements
There is one window function enhancement that I am really looking forward to using: named windows. Itzik gave this a much thorough treatment in T-SQL Windowing Improvements in SQL Server 2022, but here's a quick example of how it can simplify a query.
Let's change the second query above so that it has a slightly more complex OVER() clause:
SELECT TOP (20) Id, PostTypeId, Score, rn = ROW_NUMBER() OVER (PARTITION BY PostTypeID ORDER BY Score DESC), rk = RANK() OVER (PARTITION BY PostTypeID ORDER BY Score DESC), dr = DENSE_RANK() OVER (PARTITION BY PostTypeID ORDER BY Score DESC) FROM Posts WHERE CreationDate >= DATEADD(DAY, -14, GETDATE()) ORDER BY Score DESC;
Note that the same over clause is repeated multiple times, which makes the query harder to maintain, particularly if there may be changes later. In SQL Server 2022, you can alias a defined window, e.g.:
SELECT TOP (20) Id, PostTypeId, Score, rn = ROW_NUMBER() OVER PScore, rk = RANK() OVER PScore, dr = DENSE_RANK() OVER PScore FROM Posts WHERE CreationDate >= DATEADD(DAY, -14, GETDATE()) WINDOW PScore AS (PARTITION BY PostTypeID ORDER BY Score DESC) ORDER BY Score DESC;
You can also consolidate just part of the OVER() clause, for example a common use case is to take the row number ascending and descending over the same partition. You can simplify this:
SELECT ...cols..., rnA = ROW_NUMBER() OVER (PARTITION BY PostTypeID ORDER BY Score), rnB = ROW_NUMBER() OVER (PARTITION BY PostTypeID ORDER BY Score DESC) FROM Posts WHERE ...
To this:
SELECT ...cols..., rnA = ROW_NUMBER() OVER (PScore ORDER BY Score), rnB = ROW_NUMBER() OVER (PScore ORDER BY Score DESC) FROM Posts WHERE ... WINDOW PScore AS (PARTITION BY PostTypeID) ...
Which can be really helpful with more elaborate partition clauses.
I can't demonstrate these on Stack Exchange Data Explorer directly, since its underlying version is still SQL Server 2019. But you can try them out on your own systems or using db<>fiddle. These enhancements are also available in Azure SQL Database / Azure SQL Managed Instance.
Conclusion
Window functions can solve all kinds of problems in SQL Server, and this post just barely scratches the surface. They can also be used for gaps and islands, grouped medians, and even more elaborate things. I am interested in reading all of the other T-SQL Tuesday #168 contributions.
1 Response
[…] Aaron Bertrand build a list: […]