While this article is specifically geared to SQL Server, the concepts apply to any relational database platform.
The Stack Exchange network logs a lot of web traffic – even compressed, we average well over a terabyte per month. And that is just a summarized cross-section of our overall raw log data, which we load into a database for downstream security and analytical purposes. Every month has its own table, allowing for partitioning-like sliding windows and selective indexes without the additional restrictions and management overhead. (Taryn Pratt talks about these tables in great detail in her post, Migrating a 40TB SQL Server Database.)
It’s no surprise that our log data is massive, but could it be smaller? Let’s take a look at a few typical rows. While these are not all of the columns or the exact column names, they should give an idea why 50 million visitors a month on Stack Overflow alone can add up quickly and punish our storage:
|
1 2 3 4 5 6 7 8 |
HostName Uri QueryString CreationDate ... nvarchar(250) nvarchar(2048) nvarchar(2048) datetime --------------------------- ---------------- -------------- -------------- math.stackexchange.com /questions/show/ 2023-01-01 ... math.stackexchange.com /users/56789/ ?tab=active 2023-01-01 ... meta.math.stackexchange.com /q/98765/ ?x=124.54 2023-01-01 ... |
Now, imagine analysts searching against that data – let’s say, looking for patterns on January 1st for Mathematics and Mathematics Meta. They will most likely write a WHERE clause like this:
|
1 2 3 4 5 |
WHERE CreationDate >= '20230101' AND CreationDate < '20230102' AND HostName LIKE N'%math.stackexchange.com'; |
These quite expectedly lead to awful execution plans with a residual predicate for the string match on every row in the date range – even if only three rows match. We can demonstrate this with a table and some data:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
CREATE TABLE dbo.GinormaLog_OldWay ( Id int IDENTITY(1,1), HostName nvarchar(250), Uri nvarchar(2048), QueryString nvarchar(2048), CreationDate datetime, /* other columns */ CONSTRAINT PK_GinormaLog_OldWay PRIMARY KEY(Id) ); /* populate a few rows to search for (the needles) */ DECLARE @math nvarchar(250) = N'math.stackexchange.com'; DECLARE @meta nvarchar(250) = N'meta.' + @math; INSERT dbo.GinormaLog_OldWay(HostName, Uri, QueryString, CreationDate) VALUES (@math, N'/questions/show/', N'', '20230101 01:24'), (@math, N'/users/56789/', N'?tab=active', '20230101 01:25'), (@meta, N'/q/98765/', N'?x=124.54', '20230101 01:26'); GO /* put some realistic other traffic (the haystack) */ INSERT dbo.GinormaLog_OldWay(HostName, Uri, QueryString, CreationDate) SELECT TOP (1000) N'stackoverflow.com', CONCAT(N'/q/', ABS(object_id % 10000)), CONCAT(N'?x=', name), DATEADD(minute, column_id, '20230101') FROM sys.all_columns; GO 10 INSERT dbo.GinormaLog_OldWay(HostName, Uri, QueryString, CreationDate) SELECT TOP (1000) N'stackoverflow.com', CONCAT(N'/q/', ABS(object_id % 10000)), CONCAT(N'?x=', name), DATEADD(minute, -column_id, '20230125') FROM sys.all_columns; GO /* create an index to cater to many searches */ CREATE INDEX DateRange ON dbo.GinormaLog_OldWay(CreationDate) INCLUDE(HostName, Uri, QueryString); |
Now, we run the following query (SELECT * for brevity):
|
1 2 3 4 5 6 7 |
SELECT * FROM dbo.GinormaLog_OldWay WHERE CreationDate >= '20230101' AND CreationDate < '20230102' AND HostName LIKE N'%math.stackexchange.com'; |
And sure enough, we get a plan that looks okay, especially in Management Studio – it has an index seek and everything! But that is misleading, because that index seek is doing a lot more work than it should. And in the real world, those reads and other costs are much higher, both because there are more rows to ignore, and every row is a lot wider:

So, then, what if we create an index on CreationDate, HostName?
|
1 2 3 4 5 |
CREATE INDEX Date_HostName ON dbo.GinormaLog_OldWay(CreationDate, HostName) INCLUDE(Uri, QueryString); |
This doesn’t help. We still get the same plan, because whether or not the HostName shows up in the key, the bulk of the work is filtering the rows to the date range, and then checking the string is still just residual work against all the rows:
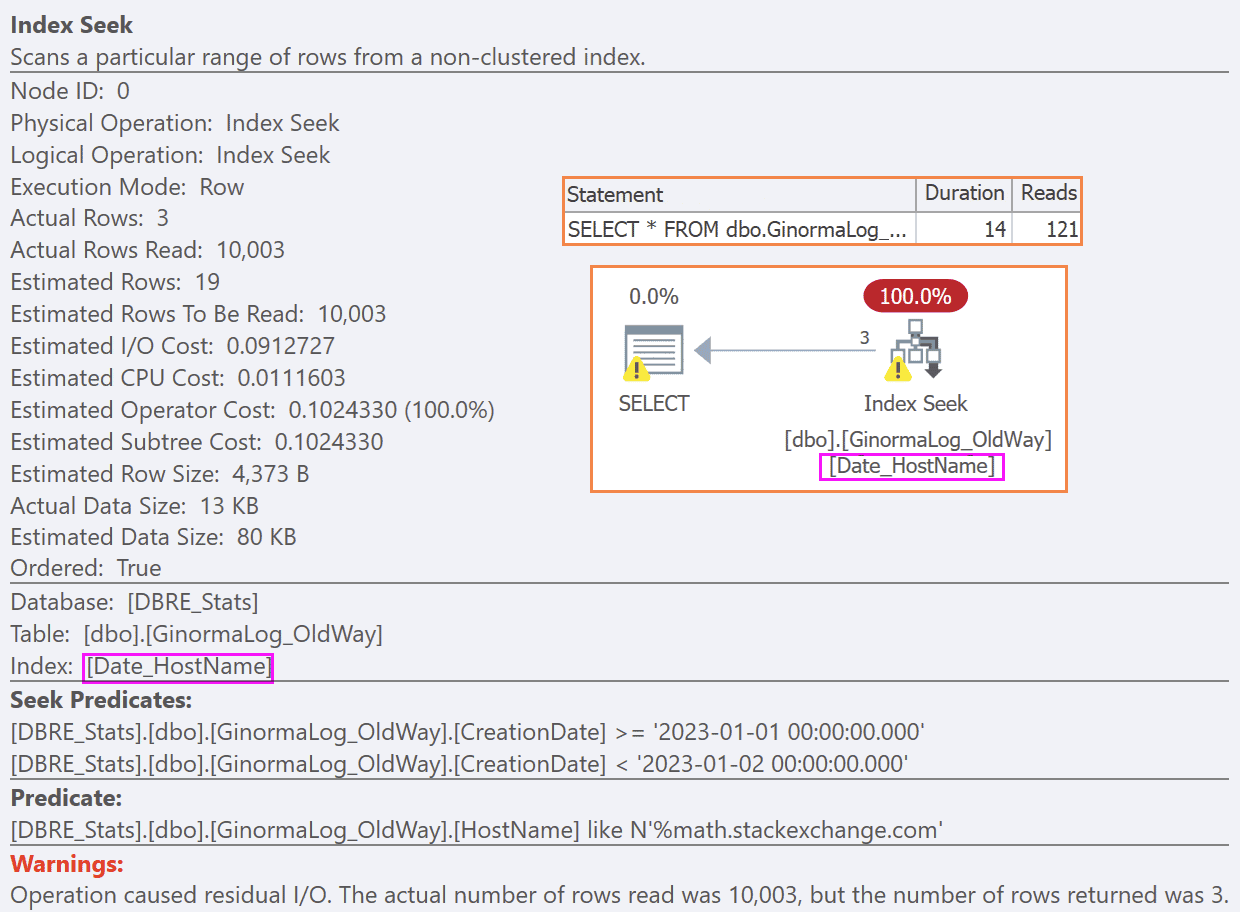
If we could coerce users to use more index-friendly queries without leading wildcards, like this, we may have more options:
|
1 2 3 4 5 6 7 8 9 |
WHERE CreationDate >= '20230101' AND CreationDate < '20230102' AND HostName IN ( N'math.stackexchange.com', N'meta.math.stackexchange.com' ); |
In this case, you can see how an index (at least leading) on HostName might help:
|
1 2 3 4 5 |
CREATE INDEX HostName ON dbo.GinormaLog_OldWay(HostName, CreationDate) INCLUDE(Uri, QueryString); |
But this will only be effective if we can coerce users to change their habits. If they keep using LIKE, the query will still choose the older index (and results aren’t any better even if you force the new index). But with an index leading on HostName and a query that caters to that index, the results are drastically better:
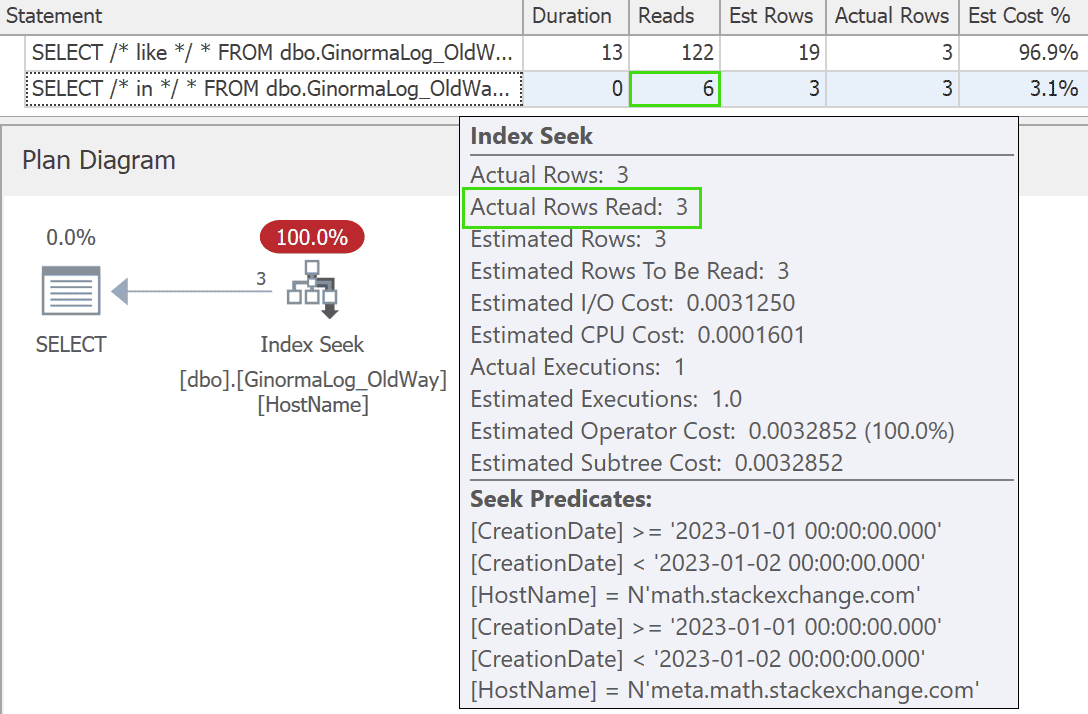
This is not overly surprising, but I do empathize that it can be hard to persuade users to change their query habits and, even when you can, it can also be hard to justify creating additional indexes on already very large tables. This is especially true of log tables, which are write-heavy, append-only, and read-seldom.
When I can, I would rather focus on making those tables smaller in the first place.
Compression can help to an extent, and columnstore indexes, too (though they bring additional considerations). You may even be able to halve the size of this column by convincing your team that your host names don’t need to support Unicode.
For the adventurous, I recommend better normalization!
Think about it: If we log math.stackexchange.com a million times today, does it make sense to store 44 bytes, a million times? I would rather store that value in a lookup table once, the first time we see it, and then use a surrogate identifier that can be much smaller. In our case, since we know we won’t ever have over 32,000 Q&A sites, we can use smallint (2 bytes) – saving 22 bytes per row (or more, for longer host names). Picture this slightly different schema:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
CREATE TABLE dbo.NormalizedHostNames ( HostNameId smallint identity(1,1), HostName nvarchar(250) NOT NULL, CONSTRAINT PK_NormalizedHostNames PRIMARY KEY(HostNameId), CONSTRAINT UQ_NormalizedHostNames UNIQUE(HostName) ); INSERT dbo.NormalizedHostNames(HostName) VALUES(N'math.stackexchange.com'), (N'meta.math.stackexchange.com'), (N'stackoverflow.com'); CREATE TABLE dbo.GinormaLog_NewWay ( Id int identity(1,1) NOT NULL, HostNameId smallint NOT NULL FOREIGN KEY REFERENCES dbo.NormalizedHostNames(HostNameId), Uri nvarchar(2048), QueryString nvarchar(2048), CreationDate datetime, /* other columns */ CONSTRAINT PK_GinormaLog_NewWay PRIMARY KEY(Id) ); CREATE INDEX HostName ON dbo.GinormaLog_NewWay(HostNameId, CreationDate) INCLUDE(Uri, QueryString); |
Then the app maps the host name to its identifier (or inserts a row if it can’t find one), and inserts the id into the log table instead:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
/* populate a few rows to search for (the needles) */ INSERT dbo.GinormaLog_NewWay(HostNameId, Uri, QueryString, CreationDate) VALUES (1, N'/questions/show/', N'', '20230101 01:24'), (1, N'/users/56789/', N'?tab=active', '20230101 01:25'), (2, N'/q/98765/', N'?x=124.54', '20230101 01:26'); GO /* put some realistic other traffic (the haystack) */ INSERT dbo.GinormaLog_NewWay(HostNameId, Uri, QueryString, CreationDate) SELECT TOP (1000) 3, CONCAT(N'/q/', ABS(object_id % 10000)), CONCAT(N'?x=', name), DATEADD(minute, column_id, '20230101') FROM sys.all_columns; GO 10 INSERT dbo.GinormaLog_NewWay(HostNameId, Uri, QueryString, CreationDate) SELECT TOP (1000) 3, CONCAT(N'/q/', ABS(object_id % 10000)), CONCAT(N'?x=', name), DATEADD(minute, -column_id, '20230125') FROM sys.all_columns; |
First, let’s compare the sizes:

That’s a 36% reduction in space. When we’re talking about terabytes of data, this can drastically reduce storage costs and significantly extend the utility and lifetime of existing hardware.
What about our queries?
The queries are slightly more complicated, because now you have to perform a join:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT * FROM dbo.GinormaLog_NewWay AS nw INNER JOIN dbo.NormalizedHostNames AS hn ON nw.HostNameId = hn.HostNameId WHERE nw.CreationDate >= '20230101' AND nw.CreationDate < '20230102' AND hn.HostName LIKE N'%math.stackexchange.com'; /* -- or AND (hn.HostName IN (N'math.stackexchange.com', N'meta.math.stackexchange.com')); */ |
In this case, using LIKE isn’t a disadvantage unless the host names table becomes massive. The plans are almost identical, except that the LIKE variation can’t perform a seek. (Both are a little more horrible at estimates, but I don’t see how being any worse off the mark here will ever pick any other plan.)
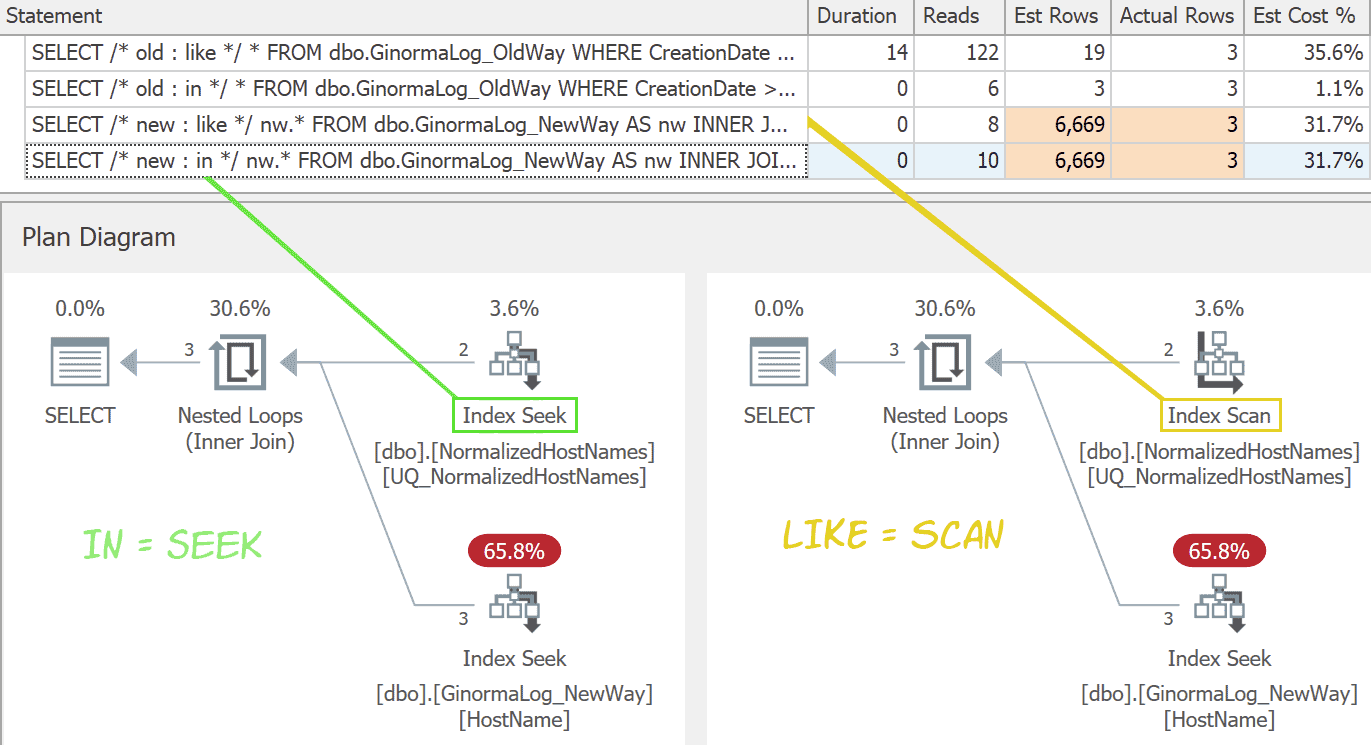
This is one scenario where the difference between a seek and a scan is such a small part of the plan it is unlikely to be significant.
This strategy still requires analysts and other end users to change their query habits a little, since they need to add the join compared to when all of the information was in a single table. But you can make this change relatively transparent to them by offering views that simplify the joins away:
|
1 2 3 4 5 6 7 8 |
CREATE VIEW dbo.vGinormaLog AS SELECT nw.*, hn.HostName FROM dbo.GinormaLog_NewWay AS nw INNER JOIN dbo.NormalizedHostNames AS hn ON nw.HostNameId = hn.HostNameId; |
Never use SELECT * in a view. 🙂
Querying the view, like this, still leads to the same efficient plans, and lets your users use almost exactly the same query they’re used to:
|
1 2 3 4 5 6 |
SELECT * FROM dbo.vGinormaLog WHERE CreationDate >= '20230101' AND CreationDate < '20230102' AND HostName LIKE N'%math.stackexchange.com'; |
Existing infrastructure vs. greenfield
Even scheduling the maintenance to change the way the app writes to the log table – never mind actually making the change – can be a challenge. This is especially difficult if logs are merely bulk inserted or come from multiple sources. It may be sensible to use a new table (perhaps with partitioning) and start adding new data going forward in a slightly different format, and leaving the old data as is, using a view to bridge them.
That could be complex, and I don’t mean to trivialize this change. I wanted to post this more as a “lessons learned” kind of thing – if you are building a system where you will be logging a lot of redundant string information, think about a more normalized design from the start. It’s much easier to build it this way now than to shoehorn it later… when it may well be too big and too late to change. Just be careful to not treat all potentially repeating strings as repeating enough to make normalization pay off. For host names at Stack Overflow, we have a predictably finite number, but I wouldn’t consider this for user agent strings or referrer URLs, for example, since that data is much more volatile and the number of unique values will be a large percentage of the entire set.
Load comments