
 For this month's T-SQL Tuesday, Brent Ozar asks us to describe the last ticket we closed. Well, I have one I sort of closed, and it's been a while.
For this month's T-SQL Tuesday, Brent Ozar asks us to describe the last ticket we closed. Well, I have one I sort of closed, and it's been a while.
An engineer reported that deleting a user through the application was slow.
My initial reaction
Before looking at the code path, the query, or the execution plan, I didn't even believe the application would regularly perform a hard delete. Teams typically soft delete "expensive" things that are ever-growing (e.g., change an IsActive column from 1 to 0). Deleting a user is bound to be expensive, because there are usually many inbound foreign keys that have to be validated for the delete to succeed. Also, every index has to be updated as part of the operation. On top of that, there are often triggers that fire on delete.
While I know that we do sometimes soft delete users, the engineer assured me that the application does, in some cases, hard delete users.
Okay, fair enough.
But my response was still that there's no way for the delete to not be expensive. Between the foreign keys, many indexes, and triggers, it's a lot of work.
To emphasize my point, I checked exactly how many foreign keys point at the Users primary key (Id):
SELECT COUNT(*) FROM sys.foreign_key_columns AS fkc INNER JOIN sys.objects AS o ON fkc.referenced_object_id = o.[object_id] INNER JOIN sys.columns AS c ON fkc.referenced_column_id = c.column_id AND o.[object_id] = c.[object_id] WHERE o.name = N'Users' AND c.name = N'Id';
The number was high enough that I'm not even going to tell you.
Let's say there are x: When a row is deleted, all x foreign keys have to be checked (even if you just manually deleted all the referencing rows). Now, imagine there are a lot more than x. And don't forget the indexes and the triggers!
So, I looked at the plan
I had some lunch, cleared my head, and revisited by generating an execution plan. The query was simple:
/* verified: not a real user */ DELETE dbo.Users WHERE ID = 12345678;
The plan quickly illustrated both the scope of the foreign keys, and also that 11 non-clustered indexes have to be updated. (And it doesn't even reflect anything about the triggers.)
To fit on screen, I carved out many seeks and scans in the middle:

That looks like some work
On closer look, in the middle of all those seeks, I spotted a newer-ish table with a foreign key to Users.Id… and this column wasn't indexed, as evidenced by a clustered index scan. This stood out pretty clearly – even without zooming in – as it wasn't just a scan, but a very expensive scan:
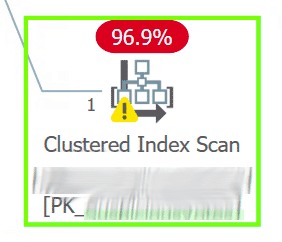
Houston, we found the problem.
The engineer came to the same conclusion, at about the same time. They deployed the index, performance returned to "normal," and the issue was closed. It would have been closed a lot faster if I had started with the plan.
Takeaway
Sometimes you just need to solve the problem in front of you, instead of abstracting it away. I was guilty here of coming up with excuses for poor performance because (a) I made assumptions about application behavior, and (b) I didn't just look at the plan.
There was a time in my career where I would have been super embarrassed to describe this scenario to anyone, never mind in a T-SQL Tuesday post with Brent Ozar-level traffic. These days, though, I'm a firm believer that no matter how senior, we're all always learning and improving. Admitting and talking through mistakes or stumbles can help other people, too; not just me.
2 Responses
[…] Aaron Bertrand has an admission: […]
[…] Slow Deletes Due to Foreign Keys – Aaron Bertrand couldn't believe a simple delete could be so slow – until he checked out the query plan. […]