
There have been many evolutions of how Microsoft accepts feedback about SQL Server.

There have been many evolutions of how Microsoft accepts feedback about SQL Server.
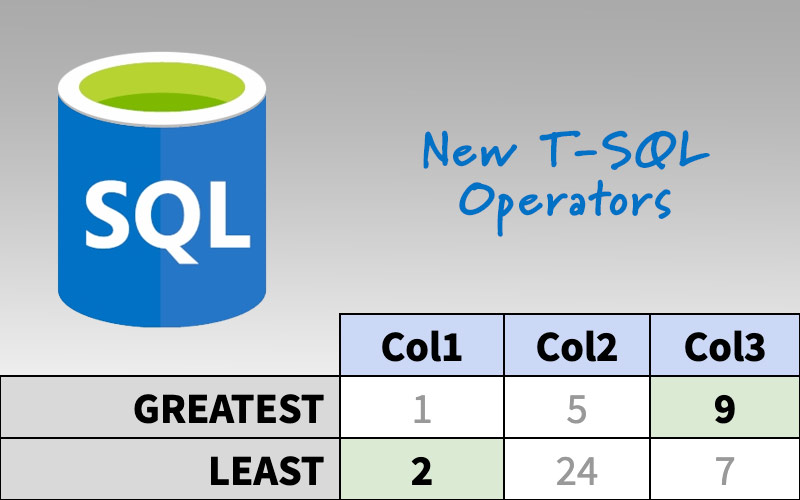
These functions aren't brand new, but they're in Azure SQL Database and Azure SQL Managed Instance, and they're coming to SQL Server 2022 soon.
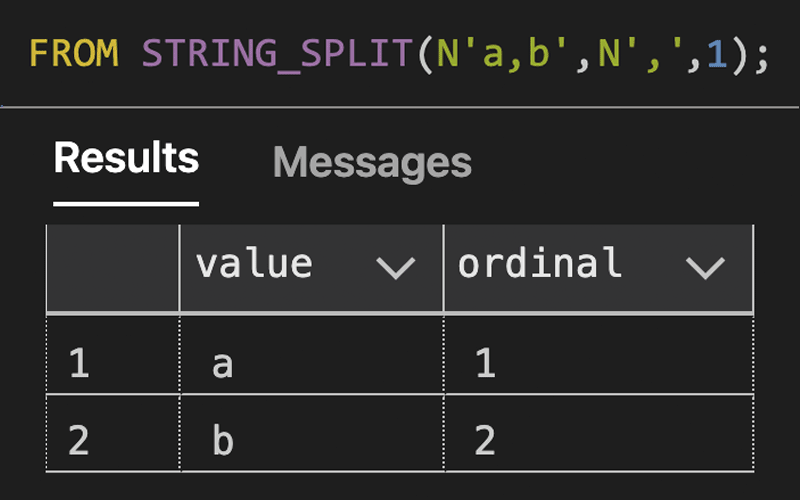
See the new overloaded STRING_SPLIT() function with its enable_ordinal parameter, now available in an Azure SQL Database near you.

In this tip, I show how I compared my previous favorite ordered splitting function to a different technique using OPENJSON().

I show one way to run arbitrary SQL against objects in an arbitrary database – using nested dynamic SQL.
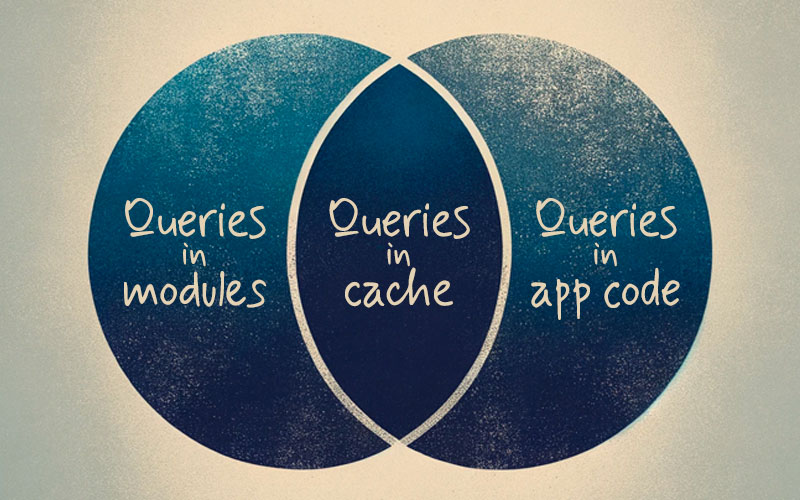
Using PowerShell calling nested dynamic SQL that drives a cursor, I show one way to collect information about queries with index hints both in the plan cache and in stored procedures, views, and other modules.
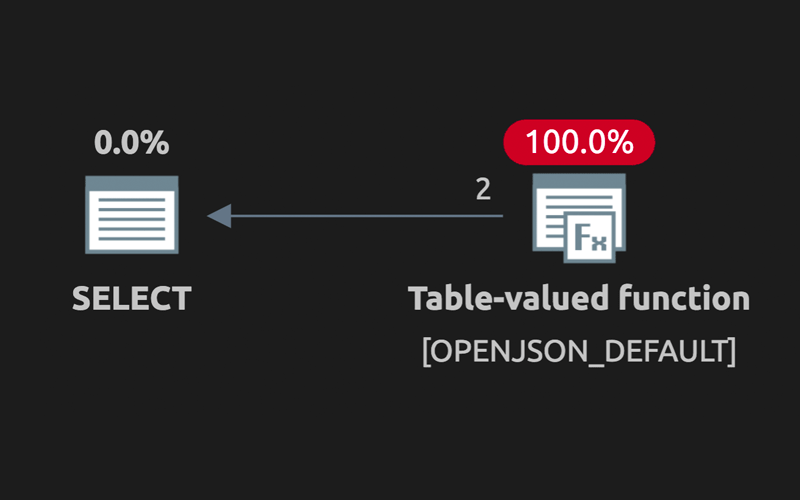
After seeing multiple people switch from STRING_SPLIT() to OPENJSON() to deal with multiple parameters, I decided to explore whether that is a change in the wrong direction.

I talk about NULLs in SQL Server, the logical issues with avoiding them, and potential performance impacts.

Updated this stored procedure I wrote a decade ago to search for a string in procedure bodies, object names, job steps, and more…

I talk a bit about bit columns: names with negative context, allowing NULLs, and using cryptic BITWISE operators instead of readable, self-documenting expressions.

For this month's T-SQL Tuesday, I talk about the scripts I use to keep a local system with all kinds of oddball metadata scenarios.

In this tip, I use specific examples to counter assumptions that data types are always case insensitive.

I talk about using partition switching to load in fresh versions of staging tables with the least impact to users.

I made some landing pages here, with simple and easy-to-remember URLs, presenting sets of links to very frequently-discussed topics around SQL Server.

In this tip, I discuss one way to help avoid infinite loops in common while loop patterns.

In part 4, I show how to include ad hoc DML queries in the analysis.

In part 3, I tie it together and show how to use relational logic to further eliminate false positives.

In part 2, I show how to identify problematic NOLOCK patterns across multiple databases and multiple instances.

I start a new series on identifying and removing problematic NOLOCK hints from update and delete statements.

For T-SQL Tuesday #140, Anthony Nocentino asks us what we have been up to with containers.

I explain why you should eliminate the data types text, ntext, and image from your environment.

After thinking setting up SQL Server 2019 on CentOS 7.5 was going to be a piece of cake, I explain how my team helped resolve a TLS issue preventing remote connections.

For the last part in my series on using a calendar table, and with some help from Itzik Ben-Gan, I describe how you can solve complex scheduling problems.

In this part of my "using a calendar table" series, I talk about filling gaps and identifying gaps and islands.

It seems a lifetime ago I wrote about creating a calendar table; now I've started a new series showing how to use the calendar table. In the first installment, I deal with business day problems.

A not exactly innovative post about using Temporal Tables functionality to automatically update a LastModified column.
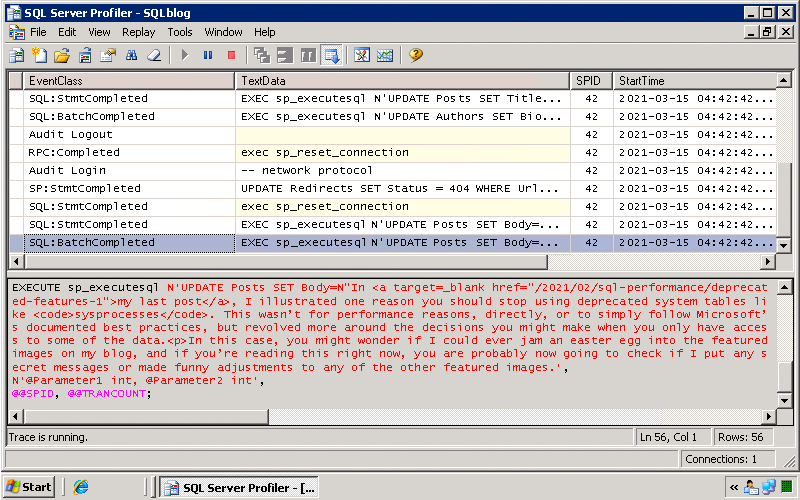
I use a real-world example showing why you shouldn't use deprecated functionality like SQL Server Profiler.

In this tip, I talk about cases where SQL Server will interpret YYYY-MM-DD as YYYY-DD-MM, which is less than optimal.
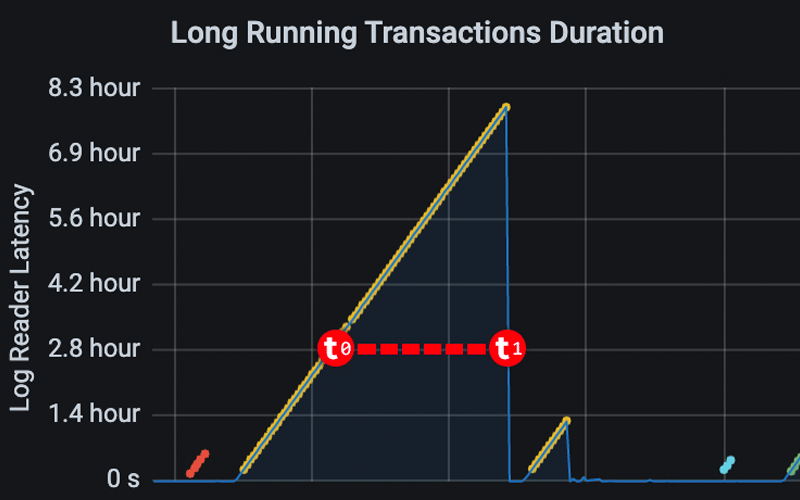
I talk about one scenario where the system table sys.sysprocesses almost led us down the wrong path.
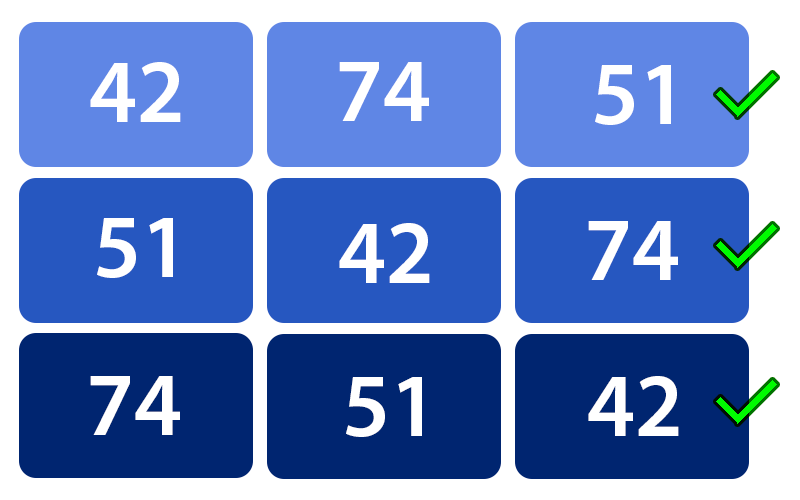
After seeing this question pop up on forums multiple times, I wrote a quick tip about enforcing unique constraints where order doesn't matter.

After a question on #sqlhelp, I dug into what could be making sys.partitions slow, and how they might get the required information in a more efficient way.
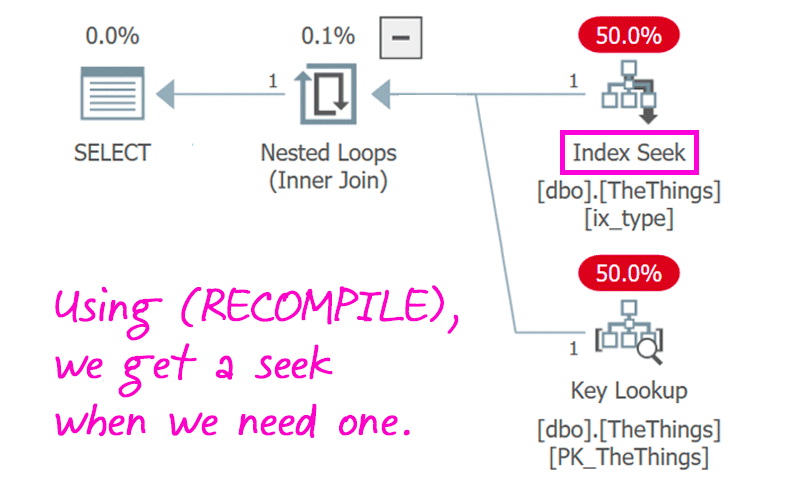
I explain a recent case where sp_prepare came in handy: trying to validate a plan guide's impact.

I recently came across an interesting issue with CHECKDB snapshots, as well as a bit of information missing from the documentation.

More background on ParamParser, some recent changes, and several syntax examples.
Rob Volk asks us to share our favorite analogies that help explain database-related concepts to less technical folk.
I've made the GitHub repository for ParamParser public; here is some more background behind this project.

I've started a new project to parse default values from stored procedures and functions.

If you ever use sys.sp_columns as shorthand for catalog views, please don't, and I'll tell you why.

Whether you love or fear new PC builds, it's not every day a Mac person builds a Windows PC. See the parts I chose and how much more economical this option can be.
There is a very common anti-pattern you should avoid, involving updating a row if it exists and inserting it if it doesn't. See how to avoid race conditions and deadlocks.

Altering a fixed-width column on a large table can often mean either a lot of planning or a lot of downtime, but in some scenarios there may be an easy out.

We had a case where we increased a varchar column's size, ONLINE, but it caused significant downstream effects. See why.
There are some limitations with STRING_SPLIT that could be overcome, but the cleanest solution might be to add a new function altogether.

Find out about the replacement I wrote for the undocumented, unsupported, and ill-advised system procedure, sp_MSforeachdb.

Updated in 2020 with a few new entries, this is a fairly comprehensive list of the reasons behind various 18456 error messages.

See two ways you can make the relevant data in the system_health session last longer and not get drowned out by noise.

Access the system_health file target without tedious string parsing gymnastics.

This series shows how I determine the amount of data distributed across indexes, files, filegroups, and partitions.