
I talk about making a minor schema improvement to large log-type tables containing repeated strings.

I talk about making a minor schema improvement to large log-type tables containing repeated strings.

I talk about how I use dynamic SQL to handle many databases with not-quite-identical schema.

I discuss my roller coaster of emotions since learning that SQL Server 2022 would support instant file initialization for log files.

In this tip, I take a quick look at some changes to Always Encrypted that make it easier to use.

I've long been pro-schema-prefix, but in this post I talk about an exception to the rule at Stack Overflow, and why it works well.

I show how GENERATE_SERIES makes for easier set building, and decent alternatives while you're still stuck on older versions.

While it might promote less than ideal practices, I show how to use a DDL trigger to keep views in sync with a volatile schema.

In the final part of this series, I convert my T-SQL code to MySQL, so you can build a fancy archives page in WordPress.

I show that a new experimental feature in Docker 4.16+ lets you run "real" SQL Server on Apple M1+ chips.

For my first post on Simple Talk, I rip apart a made-up stored procedure as if I had encountered it during a code review.
In the second part of this series, I show how to use a calendar table to simplify rendering an archives page.

A good round of updates for most modern versions of SQL Server, including the first cumulative update for SQL Server 2022.
I started a short series on building visual calendars, like those seen in the monthly archives page here.

I discuss an organization’s responsibility for protecting personal information.

I talk about some of the pivotal criteria guiding how Stack Overflow will migrate to Azure.

In part 3, I show how to automate creating new tables, dropping old tables, and adjusting the view.

In part 2, I look at general strategies for partitioning an archive table (even without Enterprise!) to reduce long-term data movement.

In this series, I look at strategies for archiving data and how it can impact your entire infrastructure.

For October's T-SQL Tuesday, Steve Jones asks us to talk about ways we've used dynamic SQL to solve problems.

In this tip, I show how to simplify calculations involving nth weekday or non-weekday, with and without a calendar table.

For this month's T-SQL Tuesday, I talk about a not-quite-yet-announced feature in SQL Server 2022 that has the potential to function as a low-effort bad habit logger.

I talk about ways to use wrapper functions to work around tedious syntax required by the new function, GENERATE_SERIES.

On the 10th anniversary of SQLPerformance.com, I look back on my favorite posts – one from each year.

For this month's T-SQL Tuesday, Deb Melkin asks us get up on our favorite soapbox. I have so many, but this time I picked a new one…

Logging tables get huge, and date range queries get more if they don't use the clustered index. Here's one way I've addressed the issue.
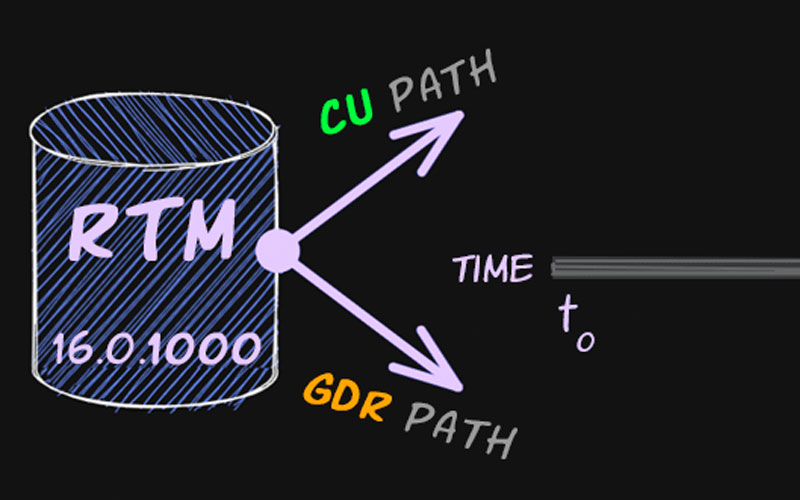
Using a fictitious future timeline, I explain how CUs and GDRs differ and why build number alone might not tell the whole story.
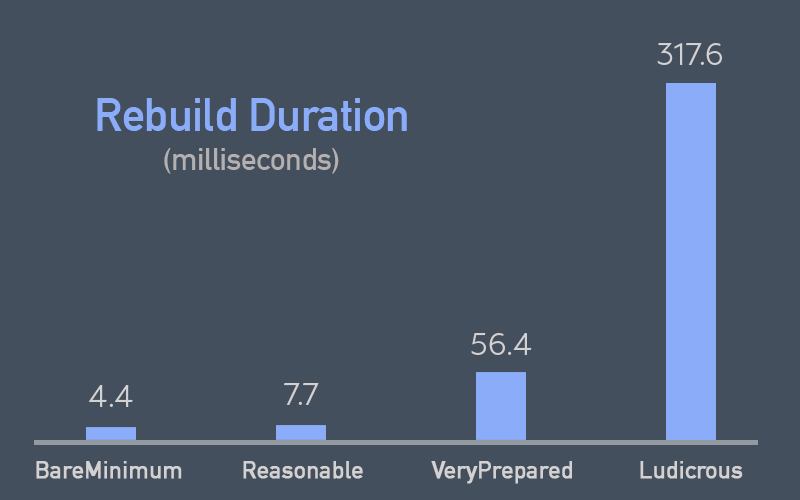
In this tip, I show some real-life reasons why you may not want to create all the partitions you'll ever need up front.

I talk about why I prefer CONVERT over CAST to be consistent. Basically, if you sometimes HAVE to use only one, why not just ALWAYS use that one?

There are often multiple ways to express a query and get the same results, often without any change in performance. Learn about one example.
In this tip, I talk about the compatibility between major versions and SQL Server's internal database version.

I continue looking at some of the changes in SQL Server 2022 that aren't on the marketing slides.
I warn about a cumbersome change to setup, where something is checked by default when it shouldn't be.
The first public preview of SQL Server 2022 is here! Read about my favorite T-SQL enhancements.

Today I received a mind-blowing award for my 200th tip at MSSQLTips.com.
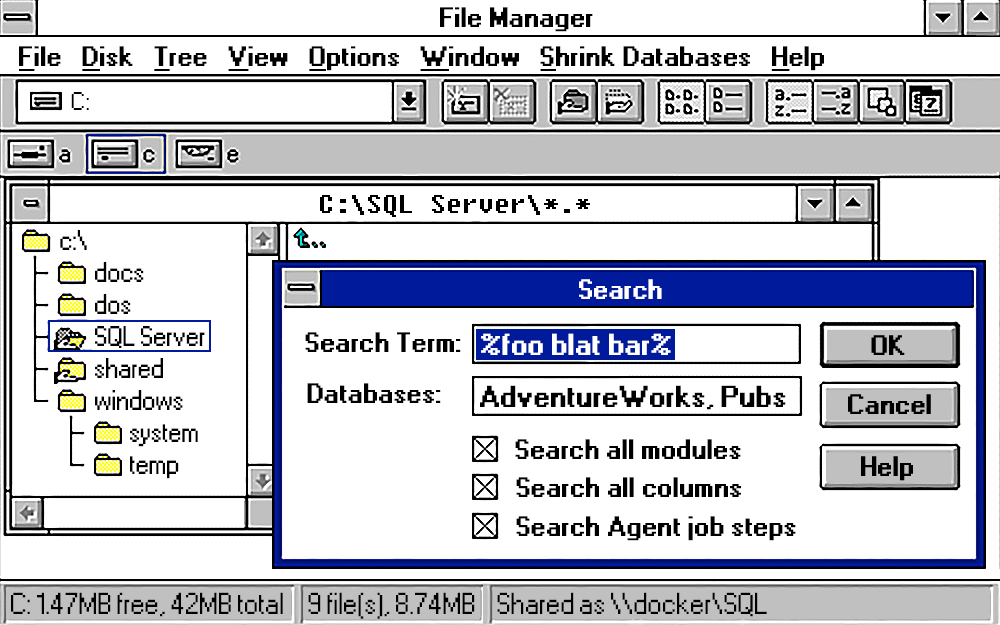
In 2015, I wrote about a stored procedure to find strings within all tables across all user databases. In this follow-up tip, I enhance the procedure to optionally include views and search within specific databases.

I show how to piece together portions of SQL Server metadata to generate DBML (which is more useful than it sounds).
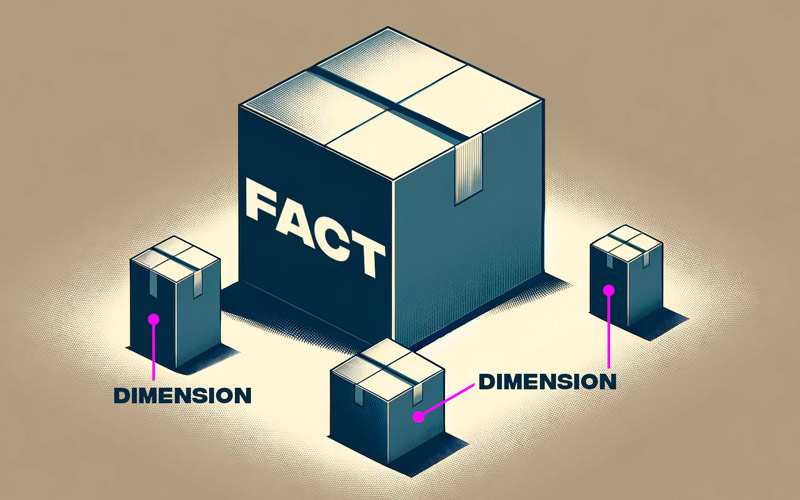
I wrote two tips around what you can do when a table that stores the same strings over and over again has grown to an unmanageable size: create a dimension table!

I talk about why every CTE I write starts with a semi-colon, and why you won't change my mind about it.

A recent documentation update raises questions about the love-it-or-hate-it READ UNCOMMITTED isolation level.

In this tip, I show how I combine GROUPING SETS and PIVOT to get crosstab-style reports without Excel.

In the second part of this series, I show two ways to shift expensive computations to write time.
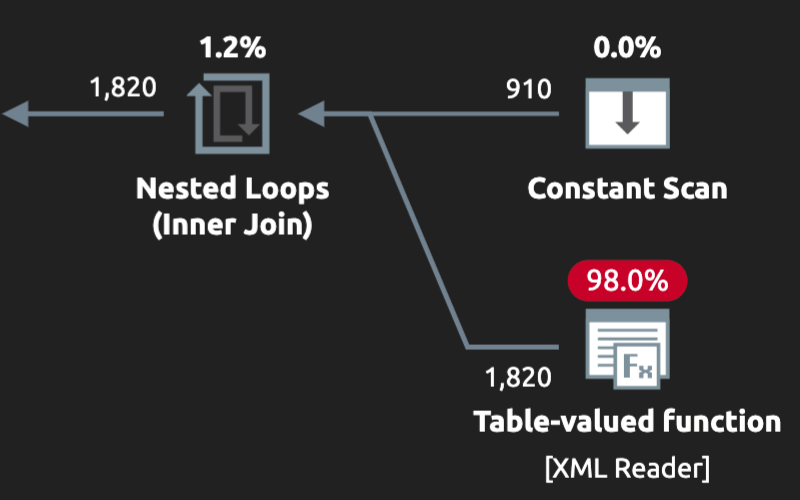
I talk about progress in aggregating strings – both in the functionality offered by SQL Server and the quality of my own code samples.

In this tip I confirm that FORMAT is still a dog compared to even very complex expressions using CONCAT_WS, DATENAME, DATEPART, and CONVERT.

I was honored to be a guest on the most recent Mixed Extents podcast, along with my friend and colleague Andy Mallon, where we talked about patching SQL Server.
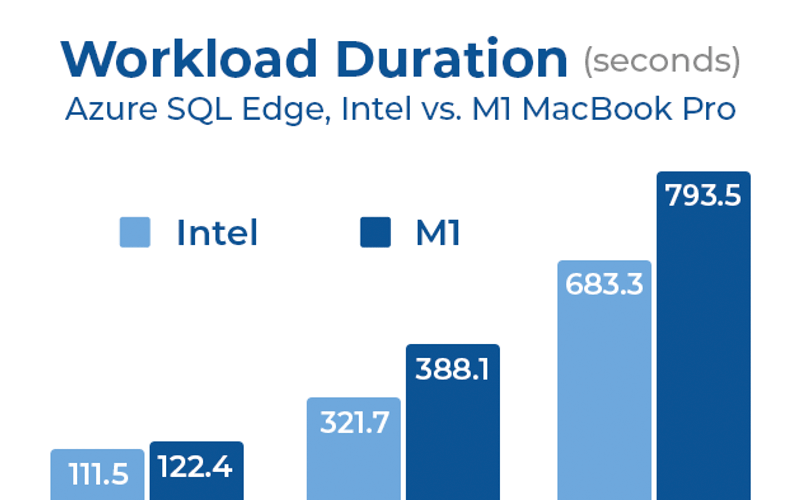
I harassed Erik Ejlskov Jensen enough to make a universal command-line version of SqlQueryStress. See how I set up a performance test between Intel and M1 MacBooks.
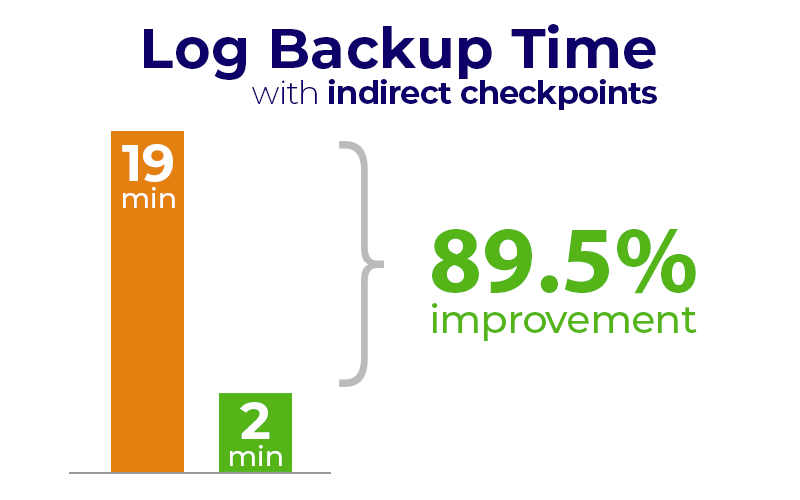
In this tip, I show how indirect checkpoints can help improve performance and stability, and conclude that you should proactively change this setting everywhere.
I show how I set up Azure SQL Edge in a Docker container on the new M1 MacBook.

See one way to use a queue table to spread out spiky, ad hoc deletes from a clustered columnstore index.