
I start a series looking at using clustered columnstore indexes and page compression to address storage footprint for a 1TB table.

I start a series looking at using clustered columnstore indexes and page compression to address storage footprint for a 1TB table.

I show how I tried to chase down a very unexpected issue with SQL Server metadata. Spoiler: it didn't end the way I thought it would.

For this month's T-SQL Tuesday, I talk about an opportunity earlier this year to significantly change my career trajectory.

Discover a simple way to keep your filtered indexes effective – even under forced parameterization.

Conventional wisdom has suggested that deletes should be batched, but in some cases this can actually take a lot longer.

Let's talk a bit about the launch of SQL Server 2019 and the flagship, bet-the-farm feature: Big Data Clusters.

I talk a little bit about two big enhancements for SQL Server 2019: installation options for setting MAXDOP and Max Server Memory.

Get a quick overview of a powerful new feature in SQL Server 2019 that will drastically improve certain tempdb-heavy workloads.
I share some thoughts about the upcoming SQL Server 2019 release and edition-specific features.

See how to generate a set of scripts that will delete rows from dependent tables and show you how many rows will be deleted from each.

I take a quick look at the performance and storage impact of the new UTF-8 collations in SQL Server 2019.

For this month's T-SQL Tuesday, I talk about an incident where I've changed my mind about something I was previously pretty stubborn about.

Find out how to use dynamic SQL to quickly generate metadata queries to pull attributes for all columns across a database or even a set of databases.

Forced Parameterization can be a useful setting to tune workloads, but this can work against you if you're also using filtered indexes.

Give your Docker containers meaningful port numbers to avoid confusion, especially when presenting or giving demos.

Originally published in 2009, I updated this in 2019 with an example showing an effect on the plan cache.

Did you know that not all characters can be used as the separator for STRING_SPLIT?

Read about an approach to partitioning a result set without the performance impact of NTILE.

See how to work around the lack of an ALTER TYPE command.

Discover some of the new information SQL Server keeps adding to help us troubleshoot query plans.

One of the biggest downsides of using SQL Server Management Studio as an interactive query tool is the limit on text/grid output. SSMS 18.2 fixes that!

In this tip, you'll see the metadata queries that will make it possible to discover which integer-based columns could be made smaller (without any loss of data).

I explain four conventions I always follow when writing T-SQL queries.
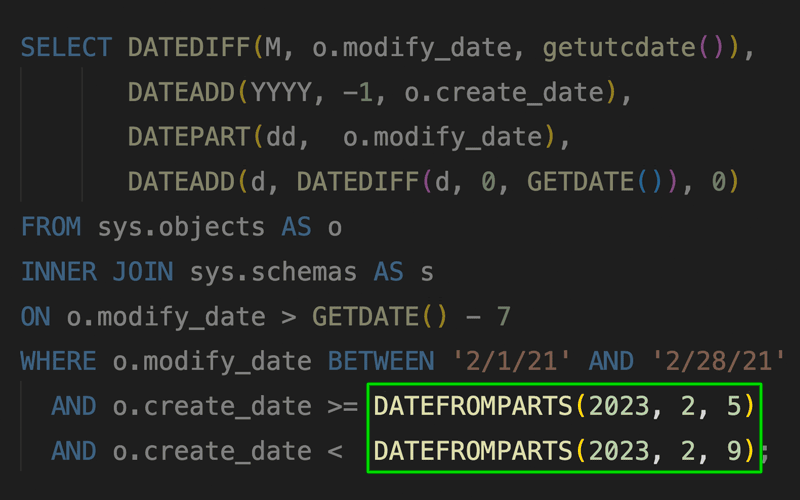
See how you can use new functions like DATEFROMPARTS to simplify otherwise really cryptic methods to obtain key dates (like the first day of the current month).

Get a first-hand look at some of the ways NOLOCK can produce incorrect data.

Aaron Bertrand talks about a few of the things that he wished he had learned earlier on.

This tip shows how powerful the CASE expression is, and some of the nuances in its behavior.

See one approach to collecting extended properties information across all of the databases on a server.
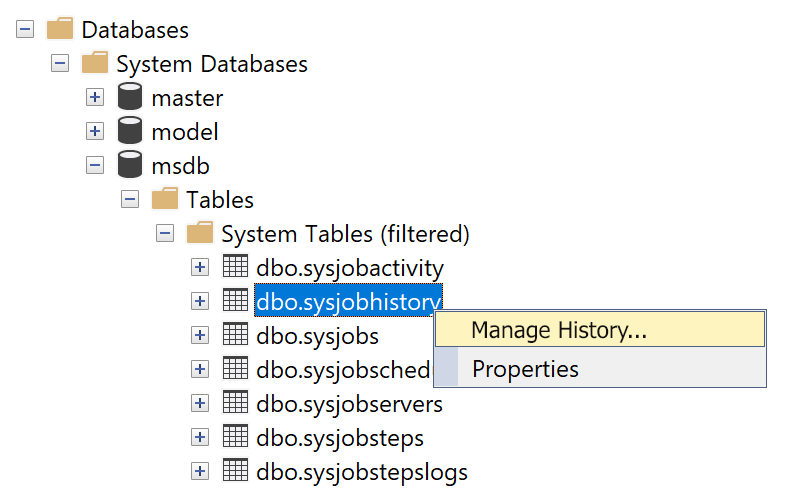
Break free from the limitations of history retention and take control at the job or even step level.

Get a quick overview of one of the most important features in SQL Server 2019.

I share my slide deck from a recent presentation at the Charlotte SQL Server User Group.

In part 2 of this series, we add another way to further isolate multiple threads of a bulk import process.

In the first of a 2-part series, see how you can easily reduce contention between multiple bulk import threads.

This tip shows a neat trick with CROSS APPLY that lets your metadata queries ignore columns that don't exist yet.

Read a quick overview Scalar UDF Inlining, a long-awaited feature in SQL Server 2019 that will improve the performance of some workloads.
If you use scalar user-defined functions, and can't take advantage of new handling in SQL Server 2019, see some other ways to reduce the impact on performance.