
Almost three years ago now, I blogged about my early experiences with this new Docker thing. As a long-time Mac user, this solution offers a lot of upside – not that there's anything wrong with Windows, it's just very resource-intensive to constantly run virtual machines. Combining a SQL Server engine running natively on my Mac and a native query editor in Azure Data Studio (and now with proper execution plans too), I could finally present a session without having to yell over my fan. Which was a problem even when booting into Windows natively using Boot Camp.
Earlier this year, at SQLSaturday Chattanooga, my container disappeared from under me. I had tested all of my demos, and went from the speaker room (where it was working) to the classroom, and by the time I got to the first demo, the container was gone. I didn't want to force everyone to sit through my troubleshooting, so I went on without demos, but it took all of 4 seconds between sessions to bring it all back. What I should have done was just run docker run again to bring my container back, but that's a mistake I'll only make once.
I now keep multiple docker run scripts handy, so I can fire up specific containers with varying configurations – including different volumes, different databases out of the gate, and different versions of SQL Server. Since I often run multiple containers at once, one of the configuration parameters that becomes important is the port number. I would struggle to keep port numbers straight or, when connecting using my recents list, remember which container represented which version. I'd have to connect and then run SELECT @@VERSION;, only to discover that wasn't the container I was looking for.
You might suggest, "Well, Aaron, you know you can name your containers, right?" Yes, that's a good point, but unless you start messing with DNS or polluting your hosts file manually, you can't connect to containers by their name (and you'll still need the port number in a lot of contexts anyway).
While I have others, my main containers today run either the latest version of SQL Server 2017 or the latest release candidate of SQL Server 2019. What I do to keep them straight, instead of trying to remember which port number was which, is I actually configure the port number to match the version number.
So my script for creating a 2017 container:
And for 2019:
Now it's pretty easy to identify which instance is which in my recent connections list:
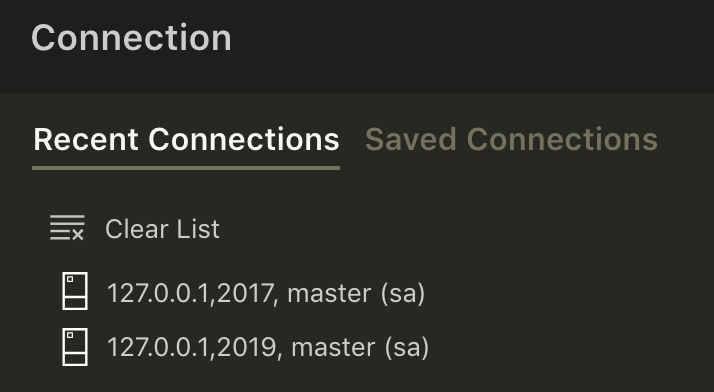 No more guesswork here
No more guesswork here
Of course, if you have multiple containers using the same version, this falls apart pretty quickly. But it's useful in my scenario, so I thought it might be useful for at least one other person out there.
In another post, I'll talk a little about using notebooks in Azure Data Studio to present, which I did for the first time at Music City Data.