
Earlier this week, I was investigating the possibility of slightly restructuring a queue table to deal with a workflow issue. That's a story for another post; for now, I wanted to share some troubleshooting I performed when a simple query returned a quite unexpected error.
I created a copy of the queue table on a development database, and went to populate it from catalog views like sys.all_columns, as I often do:
CREATE TABLE dbo.QueueTable(col1 int, col2 decimal(4,2)); INSERT dbo.tablename(col1,col2) SELECT ABS(object_id), ABS(column_id) FROM sys.all_columns ORDER BY NEWID();
I was greeted with this error, which wasn't all that strange:
Arithmetic overflow error converting int to data type numeric.
The statement has been terminated.
I thought, "what possible value for column_id could be overflowing a decimal(4,2)?" So I ran this query against sys.all_columns:
SELECT * FROM sys.all_columns;
As I scanned down the column_id values in the output, I spotted a high value was 142, which won't fit in decimal(4,2). I didn't realize that there were system tables with more than 99 columns, so, yep, my bad. But then it got interesting: The results pane suddenly switched over to the messages pane, presenting this error:
A severe error occurred on the current command. The results, if any, should be discarded.
Certainly not something I expected from a simple query against a catalog view, and my initial thought process was that I had inadvertently done something really, really bad to my instance.
When I looked back at the results grid, there were 6,553 rows there, even though there are almost 10,000 rows in sys.all_columns. So I thought something must be corrupt in that view, in row 6,554. To see about where this was happening, I added a TOP, and the results were interesting:
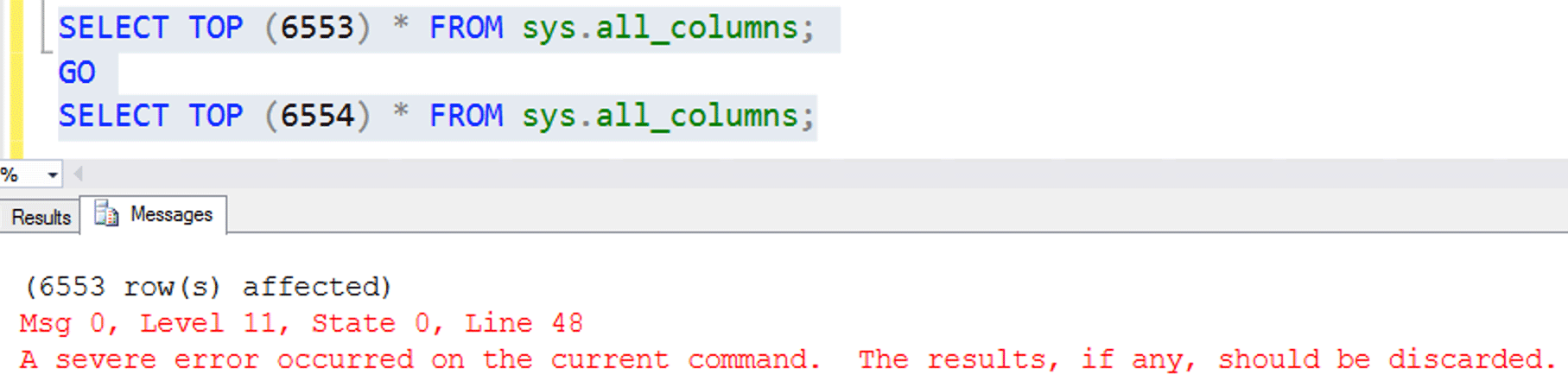 That one row makes some difference!
That one row makes some difference!
When I only selected 6,553 (arbitrary, but not really) rows, no error! I tried some more variations:
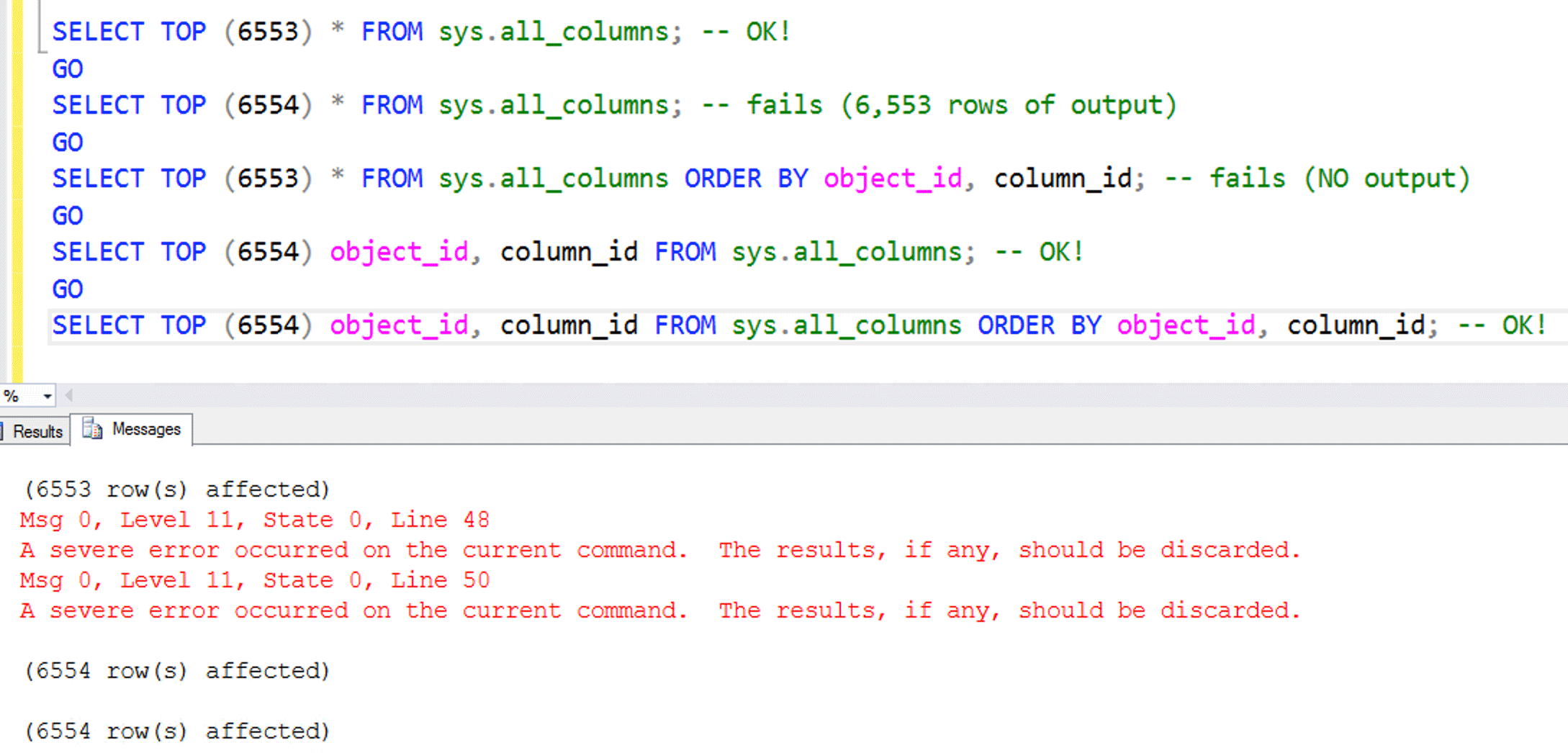 Now we have different failure types
Now we have different failure types
When I added an ORDER BY, the result changed slightly (no output, vs. 6,553 rows). When I eliminated all the other columns and just returned object_id and column_id, no error! But the results came back in a slightly different order because, without all the columns, it used a non-clustered index and a different plan. So I started adding columns back until I got the error again. This was trivial by generating a STRING_AGG() of column names (but I'll be honest, I thought this might fail too):
SELECT STRING_AGG(name, ',') FROM sys.all_columns WHERE object_id = OBJECT_ID('sys.all_columns');
The error returned when I added collation_name, so I separated that out:
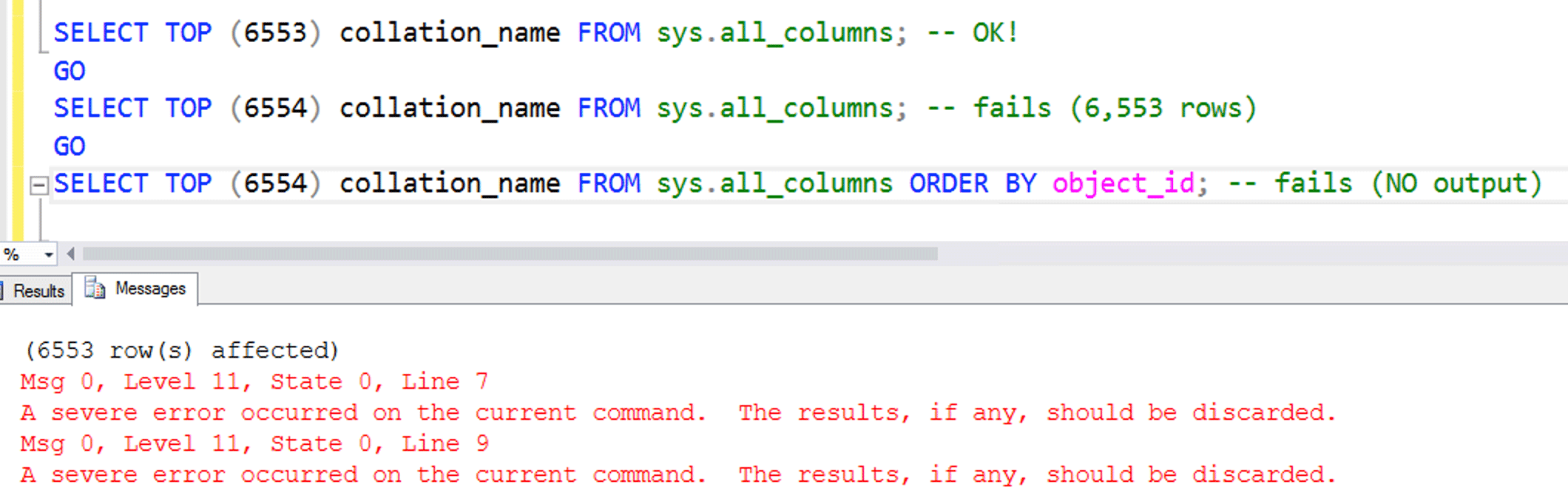 collation_name is our winner
collation_name is our winner
I looked at row 6,554 in a working result a little more closely: the object_id was -593, and the column name was physical_name. What object was this? Could this be the source of the error?
While OBJECT_NAME(-593) does return an object (pdw_table_mappings), that object actually isn't in sys.all_objects. So how it is exposed in sys.all_columns is curious. Selecting that object's object_id and name yields results, but using all columns yields one row and the severe error (examples in the screen shot later). So far, I think we have our culprit.
I looked at sys.all_columns to see what it's doing. Nothing crazy:
CREATE VIEW sys.all_columns AS SELECT * FROM sys.columns UNION ALL SELECT * FROM sys.system_columns
But that led me to review sys.system_columns:
CREATE VIEW sys.system_columns AS SELECT object_id, name collate catalog_default AS name, column_id, system_type_id, user_type_id, max_length, precision, scale, convert(sysname, ColumnPropertyEx(object_id, name, 'collation')) AS collation_name, -- ...bunch of other columns... FROM sys.system_columns$
Now we're getting somewhere. I suspect (and Srutzky posted something similar) that the failure is happening inside ColumnPropertyEx, and tested that in the last statement here:
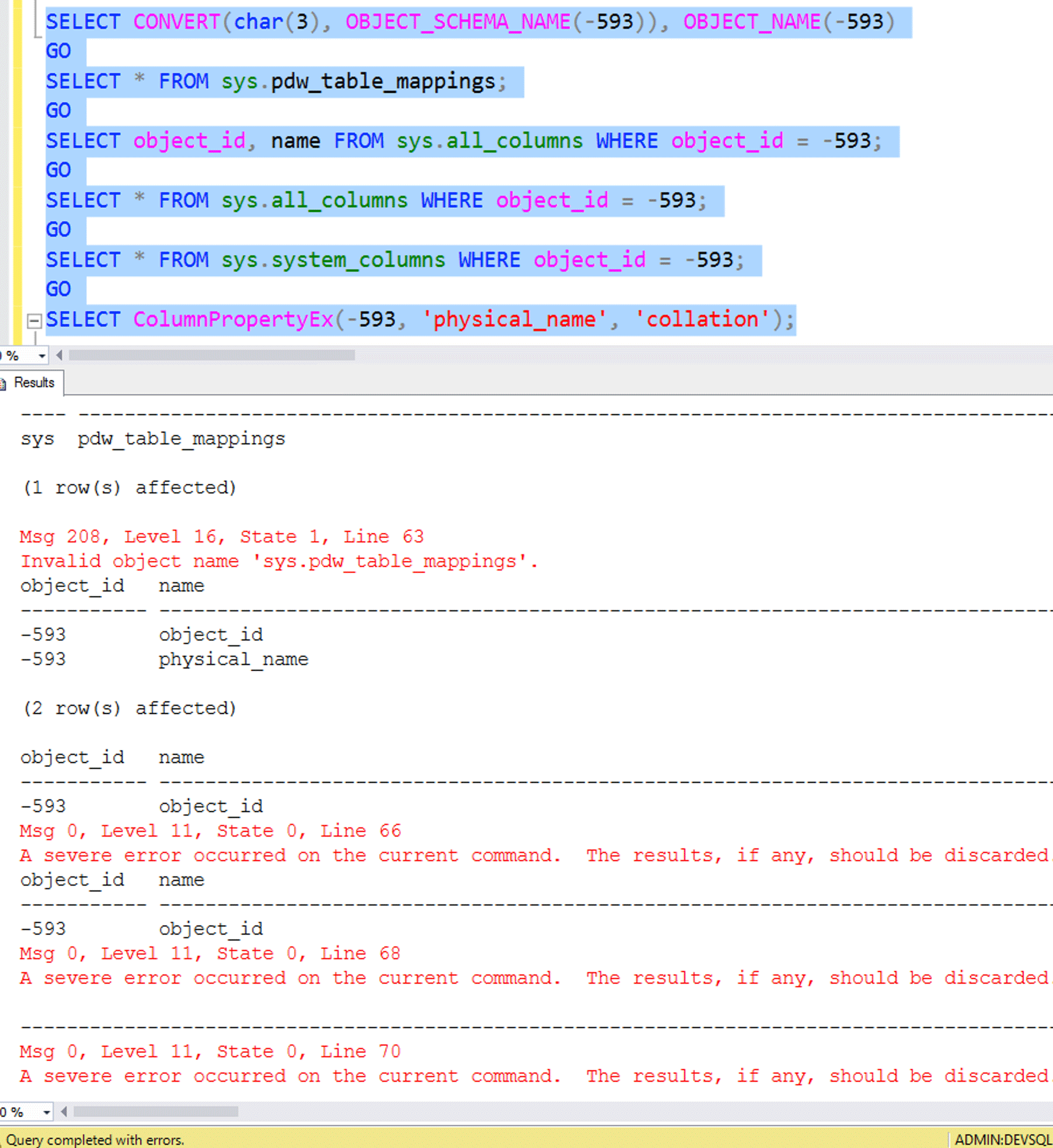 Severe error without any views involved
Severe error without any views involved
Sure enough, we've isolated this to converting the output of this function to sysname, probably because the underlying value is NULL.
But there's not much more we can do to troubleshoot the symptom – both sys.system_columns$ and the source of ColumnPropertyEx are off-limits, secret black boxes. DBCC IND does not work for sys.system_columns or sys.all_columns, so there's little hope of inspecting raw pages unless we really know how to find them and they're not just memory-resident (*cough* hex editor *cough*).
But I was still curious
I couldn't select from sys.pdw_table_mappings (even using the DAC), but I could look at its definition:
SELECT OBJECT_DEFINITION(-593);
Result (slightly prettified):
-- add it create view sys.pdw_table_mappings as select so.objid as object_id, convert(sysname, convert(sysname, so.value) + '_' + pd.name) collate database_default physical_name from sys.sysobjvalues so, sys.pdw_distributions pd where so.valclass = 12 -- SVC_MPP_TABLE and so.valnum = 2 -- MPP Table Physical Name
Ew, that's an old-style join
So we've gotten closer to the source of the problem. All along I've been thinking that the problem is the name of the collation (which is probably NULL). Now I suspect it's actually an unhandled exception somewhere due to the inability to coerce a collation of NULL to a different collation. This is impossible to reproduce because you can't set a NULL collation for your own string columns. This is clearly a metadata problem.
But I can't prove anything here, because I can't select from pdw_distributions, or even view its definition, even (still) under the DAC. So I can't test this query without the collate claudse. I even tried hack-attaching the resource database – I stopped the service, copied mssqlsystemresource.mdf and mssqlsystemresource.ldf from the BINN folder (in my case, C:\Program Files\Microsoft SQL Server\MSSQL14.SQL2017\MSSQL\Binn) to a data folder, renamed them, restarted the service, and ran this:
CREATE DATABASE rsrc ON (FILENAME = 'K:\SQL\Data\rsrc.mdf'), (FILENAME = 'K:\SQL\Data\rsrc.mdf') FOR ATTACH;
But this did not let me get at any rows in (or the source of) any of the views that might be contributing to this issue. This started feeling like a neverending stream of half the distance to the goal penalties. So, after sheepishly confirming that nothing came back from CHECKALLOC, CHECKCATALOG, or a full CHECKDB, I stopped.
What will I ever do?
I mean, this is annoying, but the workaround is trivial; you can just leave this single row out of any queries, and it will work fine:
SELECT collation_name FROM sys.all_columns WHERE object_id <> -593 AND column_id <> 2
Or you can use other views to generate rows from system metadata, if you don't need anything specifically from sys.all_columns – sys.all_parameters, for example, or join/union sys.all_objects against itself.
The quasi-conclusion
While this was an interesting investigation, it ended up being a wild goose chase, with a very unsatisfying conclusion. I found the culprit, but I can't do anything about it, aside from implement a kludgy workaround. I haven't seen much else about this issue, so I'm curious:
- What is special about my environment that makes this happen?
- How many other people would be affected by this, but don't know it because they don't use
sys.all_columnsthe way I do? - Does it also exist in SQL Server 2019?
The real conclusion
The "What is special?" question above actually led me to a new conclusion: This has nothing at all to do with SQL Server or its metadata.
I started using this particular dev server a few weeks ago. Due to security, routing, VPN, and all of that fun hoopla, the easiest way to work with SQL Server in our data centers is to RDP to a dev or jump machine and use what's there. On this particular server, someone had messed with encryption settings to try to get Always Encrypted working, and the end result is that launching SSMS 17 yielded a big ugly error. SSMS 2016 was also installed on the box so, for expediency, I just used that, and thought nothing of it.
Until today. After trying unsuccessfully to reproduce the issue on a couple of other identical instances, I considered what else might be different. I thought maybe client drivers or something, so I connected to the "bad" instance from another jump box (with SSMS 17 and 18 installed), and vice versa. You know where this is going: SSMS 2016 failed every time, and SSMS 17 and 18 worked every time, regardless of instance. Everything worked everywhere except for any instance I connected to from SSMS 2016, and I validated that on yet another jump box with that version installed.
Msg 0 should have clued me in a lot sooner that this problem wasn't coming from SQL Server. I've been running around blaming the engine, trying to be a genius detective, but I was looking in all the wrong places. I actually had this idea in my head that I stumbled upon some massive bug (well, I still think there is a bug here, in that some of these PDW-related views show up anywhere). It was a useful exercise, but what an anticlimactic ending. I'm not certain if the issue is the tool itself or the drivers it uses to connect; I'm so happy it's not a bug in the product, the rest is noise.
Moral of the story: Friends don't let friends use ancient versions of Management Studio. Please use v18, keep it updated with the monthly releases, and don't look back. If you need to use an older version for compatibility reasons, like older SSIS packages, great! Use it just for that, and use a newer version for everything else.
Related resources (added 2020-04-21):
Hey Aaron. Awesome find! So, this was happening on SQL Server 2017 when connecting via SSMS 2016? Interesting that the issue seems to be caused by SSMS since the issue that I was helping with on S.O. (that you linked to in your post) was _not_ happening in SSMS; it was only happening in the very specific scenario of: SQLCLR + using a context connection + SQL Server 2016. Not sure what version of SSMS I was using 2 years ago, but I currently have 18.4 installed and have no access to SSMS 2016 to test with.
I wonder if you would get that error running that same query via SQLCMD on the system with SSMS 2016 installed. HHmmm…
Take care,
Solomon…
No, SQLCMD seems fine. Some other interop / driver / component maybe that .NET and SSMS use (or used then, I guess) but SQLCMD does not? SQLQueryStress also fine.