

For T-SQL Tuesday this month, Andy Yun (@SQLBek) asks us to talk about times where we've overcome preconceived notions. Having been in this industry for 25 years, and still learning every single day, let me tell you, I have plenty to choose from. But something happened just last week that I thought was perfect timing and fit right in with the theme.
Filtered Indexes
Confession time. For filtered indexes, I have long held the following impressions:
- That the definition of the filter had to exactly match the predicate in the query.
- That
col IN (1, 2)was not supported in a filter definition, since it's the same ascol = 1 OR col = 2, which is definitely not supported.
Now, our Posts table has too many indexes, many of which can likely be consolidated. And in a lot of cases, the queries that use these indexes are only after specific values of PostTypeId. Our application code injects values into inline queries like this:
... WHERE PostTypeId IN ( {=Question}, {=Answer} );
… which means SQL Server sees hard-coded values …
... WHERE PostTypeId IN ( 1, 2 );
I thought that filtered indexes WHERE PostTypeId IN (1, 2) would be beneficial and make some of the index consolidation I've started working on even more effective. However, because of preconceived notion #1, I suggested an index like:
... WHERE PostTypeId >= 1 AND PostTypeId <= 2;
I immediately discounted that as impractical – since I also had preconceived notion #2, my thinking was that we would have to change all of the queries to match the filter definition.
Andy (@AMtwo) was quick to point out that my memory was flawed, and that both of my preconceived notions were rubbish. A quick search reminded me of this post by Kendra Little:
This immediately corrected both of my preconceived notions. Filtered index matching has certainly improved over time, I had just been so careful since the original implementation all those years ago that I didn't notice. I ran some tests and confirmed that, yes, I could create an index using IN (), and I could get index matching even for predicates that didn't match the filter expression exactly (as long as I didn't try to use variables or parameters – see this post from Jeremiah for more details).
It is interesting to note, though, that a query asking for WHERE PostTypeId >= 1 AND PostTypeId <= 2 will not match an index on WHERE PostTypeId IN (1,2) BUT a query asking for WHERE PostTypeId IN (1,2) will match an index on WHERE PostTypeId >= 1 AND PostTypeId <= 2. At least if PostTypeId is the leading key; if not, that falls apart. Not confusing or inconsistent at all.
Anyway, it was all for naught. For a filtered index to be worthwhile, it has to be relatively narrow and it has to eliminate a lot of rows. Unfortunately, the data skew in the Posts table is almost 100% Questions and Answers:
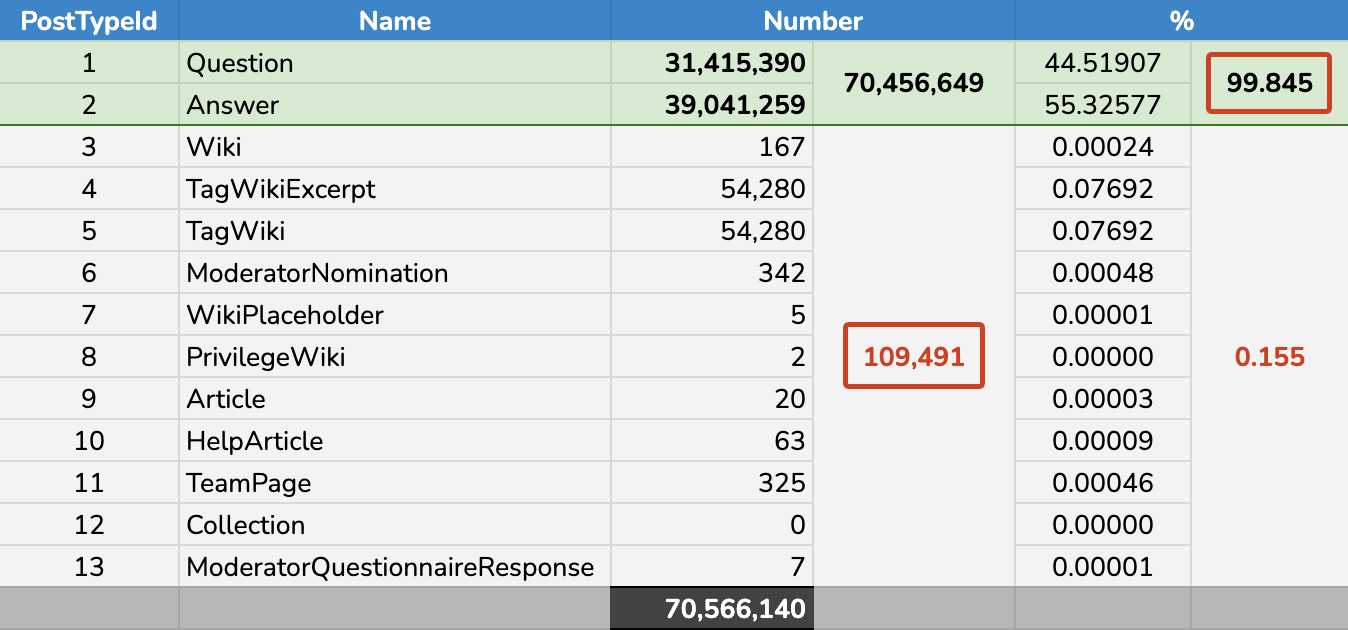 PostType distribution in StackOverflow.dbo.Posts
PostType distribution in StackOverflow.dbo.Posts
Since most queries ask for both types, and that's practically the whole table, any index with a filter would not really be any better than the same index without one. So, in this case, they're out. Just not for the original reasons I thought they wouldn't be an option at all.
Filtered Indexes : The Ugly
This discussion ultimately came about because, just the week before, we did solve a couple of other nagging internal problems with filtered indexes. They can definitely be a great solution in the right use case, but many of us have talked about some of their known and lesser-known weaknesses:
- How filtered indexes could be a more powerful feature
- Optimizer Limitations with Filtered Indexes
- What You Can (and Can't) Do With Filtered Indexes
- Filtered Indexes and INCLUDEd Columns
- Filtered Indexes: Just Add Includes
- An Unexpected Side-Effect of Adding a Filtered Index
- How Forced Parameterization Affects Filtered Indexes
- How to Overcome the Filtered Index UnMatchedIndexes Issue
A filtered index isn't always possible. And sometimes just moves problems. And even for filtered indexes you can create, you probably shouldn't bother, if:
- The filter doesn't eliminate a substantial number of rows. The whole point of the filter is to both improve read performance and also to reduce storage and maintenance costs. Unless the index is really narrow (and can't then satisfy all that many queries), scanning 99% of the table is not much better than scanning 100% of the table, and hardly worth the maintenance costs on virtually all writes.
- Using the filter requires changes to consuming queries; especially if those queries are generated in application code, or the changes involve forcing an index hint.
- The presence of the filtered index introduces additional burdens - for example, a job started failing when we added a filtered index to a certain table, because that darned SQL Server Agent inexplicably sets
QUOTED_IDENTIFIERtoOFF.
I've known about filtered indexes for a long, however, I have never used one and found myself wondering if I wasn't "smart enough" to know I should be. Given the reasons you've given to use one, I now know better. Thank you for the post, Aaron.
A filtered index on
X IN (1, 2)can't be matched with a predicate ofX BETWEEN 1 AND 2because the optimizer only reasons about the range of values.A value of X of say 1.5 would match the predicate but not be contained within the filtered index.
That's not a problem when X is a whole-number type like
integer, but the optimizer doesn't currently factor that logic in.Anyway, that's the why.
Derp, of course, thanks Paul! I need to think beyond integers, but really the only filtered indexes I ever consider are
=/IN <integer>orIS [NOT] NULL.Nice post. Filtered indexes are one of my favorite "so close, but yet so far" features.