
See the full index.
UPDATE February 13, 2015: Webucator, a provider of SQL Server training, has produced a video based on this post.
It's very easy to say, "Hey, don't do the wrong thing!" Not so easy to actually accomplish, right? In general, yes, I agree. But I see such frequent abuse of DATETIME columns in range queries that I felt it deserved some treatment.
The long, long, long laundry list
The most frequent faux pas I see is when someone uses regional date formats. For example, they want all the rows from a particular day. First they try:
SELECT COUNT(*) FROM dbo.SomeLogTable WHERE DateColumn = '10/11/2009';
The first problem there is, what if the system has British regional settings or the user's language is set to French? Is that October 11th or November 10th? I wrote the query, and I don't even know! It would be a shame to pull data from the wrong month, and not even notice. Much better to use an unambiguous date format; in spite of what –CELKO– will try to force you to believe, the only truly safe formats for date/time literals in SQL Server, at least for DATETIME and SMALLDATETIME, are:
YYYYMMDD hh:mm:ss[.nnn…]
YYYY-MM-DDThh:mm:ss[.nnn…]
(If you are using the newer types introduced in SQL Server 2008, there is more precision allowed (.nnnnnnn) and also, if you are using DATETIMEOFFSET, you can say +/-hh:mm or Z.)
As an example, even if you try to use the seemingly unambiguous YYYY-MM-DD, this can break under certain scenarios — such as when the user's language settings are set to French:
SET LANGUAGE FRENCH; GO SELECT CONVERT(DATETIME, '2009-10-13');
Msg 242, Level 16, State 3, Line 1
La conversion d'un type de données varchar en type de données datetime a créé une valeur hors limites.
For those of you not fluent in Français, that essentially says (in my best Quebec accent), "There is no month 13, dummy!" This is because in French that date format is interpreted as YYYY-DD-MM. (For some background on the attempts we've made to deprecate this interpretation, see Connect #290971.)
As opposed to YYYY-MM-DD, YYYYMMDD will never break. If you decide to use any other format for your date string literals, at least for DATETIME and SMALLDATETIME types, you are leaving yourself open to errors or incorrect data should a user have different session settings, or should the application be moved to servers with different settings. In SQL Server 2008, the new types are a little more insulated from user or machine settings; still, I use YYYYMMDD for consistency and to be safe.
When the user fixes that and passes in a proper string literal format, there is a problem with this query in most situations, since DATETIME and SMALLDATETIME columns have a time component. Unless you always strip out the time when entering data (or use a computed column that does this for you), this query should yield few, if any, rows:
SELECT COUNT(*) FROM dbo.SomeLogTable WHERE DateColumn = '20091011';
This is because the data looks like this:
DateColumn ----------------------- 2009-10-11 00:14:32.577 2009-10-11 04:31:16.465 2009-10-11 08:45:57.714
What the query above is actually asking is:
SELECT COUNT(*) FROM dbo.SomeLogTable WHERE DateColumn = '2009-10-11T00:00:00.000';
So there should be no surprise that no results are returned, since none of the values match that criteria.
What does the user do next? The same thing I did the first time I came across this problem. Convert the left side of the equation to a string, stripping off the time component:
SELECT COUNT(*) FROM dbo.SomeLogTable WHERE CONVERT(char(8), DateColumn, 112) = '20091011';
NOW I can get my data, right? Well, yes, you can get your data all right. But now you've effectively eliminated the possibility of SQL Server taking advantage of an index. Since you've forced it to build a nonsargable condition, this means it will have to convert every single value in the table to compare it to the string you've presented on the right hand side. Another approach users take is:
SELECT COUNT(*) FROM dbo.SomeLogTable WHERE DateColumn BETWEEN '20091011' AND '20091012';
Well, this approach is okay, as long as you don't have any rows that fall on midnight at the upper bound – which can be much more common if parts of your application strip time from date/time values. In that case, this query will include data from the next day; not exactly what was intended. In some cases, that *is* what is intended: some people think the above query should return all the rows from October 11th, and also all the rows from October 12th. Remember that this query can be translated to one of the following, without changing the meaning:
SELECT COUNT(*) FROM dbo.SomeLogTable WHERE DateColumn BETWEEN '2009-10-11T00:00:00.000' AND '2009-10-12T00:00:00.000'; -- or SELECT COUNT(*) FROM dbo.SomeLogTable WHERE DateColumn >= '2009-10-11T00:00:00.000' AND DateColumn <= '2009-10-12T00:00:00.000';
(Note that in the second example, that is greater than or equal to the first variable and less than or equal to the second variable.) This means that you will return rows from October 12th at exactly midnight, but not at 1:00 AM, or 4:00 PM, or 11:59 PM.
Then the user tries this, so they can still use BETWEEN and save a few keystrokes:
SELECT COUNT(*) FROM dbo.SomeLogTable WHERE DateColumn BETWEEN '20091011' AND '2009-10-11T23:59:59.997'; -- or SELECT COUNT(*) FROM dbo.SomeLogTable WHERE DateColumn BETWEEN '20091011' AND DATEADD(MILLISECOND, -3, '20091012');
These are no good either. If the data type of the column is SMALLDATETIME, the comparison is going to round up, and you *still* might include data from the next day. For the second version, if the data type of the column is DATETIME, there is still the possibility that you are going to miss rows that have a time stamp between 11:59:59 PM and 11:59:59.997 PM. Probably not many, but if there is even one, your data is no longer accurate.
(Note that if you are using the DATE data type in SQL Server 2008, or can guarantee that you always remove the time component from the column, BETWEEN is okay. But for consistency, I still stay away from BETWEEN.)
Another thing I see a lot is when people want a range like a month or a year. Can you believe that people write code like this:
SELECT COUNT(*) FROM dbo.SomeLogTable WHERE DateColumn LIKE '200910%';
The problem with this is that, even while SQL Server will implicitly convert DateColumn to a string for you, it does *not* convert it to CHAR(8) with style 112, which would be required for this wildcard search to work. (You can see what it will do "for you" when you try PRINT CURRENT_TIMESTAMP;.) So maybe they meant to do it this way:
SELECT COUNT(*) FROM dbo.SomeLogTable WHERE CONVERT(CHAR(8), DateColumn, 112) LIKE '200910%';
But this is still a bad idea because, like above, this creates a nonsargable condition, and prevents an index on DateColumn from being utilized. And finally, how about this one:
SELECT COUNT(*) FROM dbo.SomeLogTable WHERE DATEPART(YEAR, DateColumn) = 2009 AND DATEPART(MONTH, DateColumn) = 10;
This looks more like something you would see in OLAP, where you actually have measures and dimensions that will allow you to query the data this way – efficiently. In the OLTP world, this type of nonsargable query is not going to perform any better than any of the others above, and it makes parameter passing and validation more complex as well (imagine the leap year validation you'd require for a date passed in as year, month, day when the date is February 29th).
I'm not making *ANY* of these up; I have seen them all out there in the wild, either in code I've reviewed, systems I've inherited, or questions I've seen on the newsgroups or forums.
The best approach, IMHO
In order to make best possible use of indexes, and to avoid capturing too few or too many rows, the best possible way to achieve the above query is:
SELECT COUNT(*) FROM dbo.SomeLogTable WHERE DateColumn >= '20091011' AND DateColumn < '20091012';
Hopefully the queries are not being written this way, and the data is actually passed to the statement as a properly typed variable. When you can help SQL Server avoid implicit conversions, you should do so. If you are intending to allow just one day at a time in your query, you could write a stored procedure like this:
CREATE PROCEDURE dbo.GetLogCountByDay @date smalldatetime AS BEGIN SET NOCOUNT ON; SELECT COUNT(*) FROM dbo.SomeLogTable WHERE DateColumn >= @date AND DateColumn < DATEADD(DAY, 1, @date); END GO EXEC dbo.GetLogCountByDay @date = '20091011';
Why don't I use < (@date + 1) there? To enforce a best practice. I'll admit, I've used the lazy DATEADD shorthand for years. However, I now consider that a bad habit too, as it breaks with the new date/time types in SQL Server 2008:
DECLARE @d datetime2(7) = SYSDATETIME(); SELECT @d + 1;
Result:
Operand type clash: datetime2 is incompatible with int
If you want to support a range of dates, then the change is minor:
CREATE PROCEDURE dbo.GetLogCountByDateRange @StartDate smalldatetime, @EndDate smalldatetime AS BEGIN SET NOCOUNT ON; SELECT COUNT(*) FROM dbo.SomeLogTable WHERE DateColumn >= @StartDate AND DateColumn < DATEADD(DAY, 1, @EndDate); END GO EXEC dbo.GetLogCountByDateRange @StartDate = '20091011', @EndDate = '20091015';
Performance comparison
Let's compare a couple of these approaches. First, we need to build a table and some procedures (this looks like a LOT of code, but it took about 6 seconds to create on my VM):
CREATE DATABASE DateTesting; GO USE DateTesting; SET NOCOUNT ON; GO CREATE TABLE dbo.SomeLogTable ( DateColumn datetime ); GO CREATE CLUSTERED INDEX x ON dbo.SomeLogTable(DateColumn); GO -- populate a numbers table with 500K rows: DECLARE @UpperLimit int = 500000; ;WITH n AS ( SELECT x = ROW_NUMBER() OVER (ORDER BY s1.[object_id]) FROM sys.objects AS s1 CROSS JOIN sys.objects AS s2 CROSS JOIN sys.objects AS s3 CROSS JOIN sys.objects AS s4 ) SELECT [Number] = x INTO dbo.Numbers FROM n WHERE x BETWEEN 1 AND @UpperLimit; GO CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers([Number]); GO -- get 500K pretty evenly distributed rows into the log table: INSERT dbo.SomeLogTable(DateColumn) SELECT DATEADD(SECOND, -[Number], DATEADD(MINUTE, ([Number]), '20090901')) FROM dbo.Numbers; GO -- create a procedure for getting a given day's log count -- good way: GO CREATE PROCEDURE dbo.Good_LogCountByDay @date date AS BEGIN SET NOCOUNT ON; DECLARE @c INT; SELECT @c = COUNT(*) FROM dbo.SomeLogTable WHERE DateColumn >= @date AND DateColumn < DATEADD(DAY, 1, @date); END GO -- bad way #1: GO CREATE PROCEDURE dbo.Bad_LogCountByDay_1 @date smalldatetime AS BEGIN SET NOCOUNT ON; DECLARE @c INT; SELECT @c = COUNT(*) FROM dbo.SomeLogTable WHERE CONVERT(CHAR(8), DateColumn, 112) = @date; END GO -- bad way #2: GO CREATE PROCEDURE dbo.Bad_LogCountByDay_2 @year int, @month int, @day int AS BEGIN SET NOCOUNT ON; DECLARE @c INT; SELECT @c = COUNT(*) FROM dbo.SomeLogTable WHERE DATEPART(YEAR, DateColumn) = @year AND DATEPART(MONTH, DateColumn) = @month AND DATEPART(DAY, DateColumn) = @day; END GO -- create procedures for getting a month's log count -- good way: GO CREATE PROCEDURE dbo.Good_LogCountByMonth @Month date AS BEGIN SET NOCOUNT ON; DECLARE @c int; SELECT @c = COUNT(*) FROM dbo.SomeLogTable WHERE DateColumn >= @Month AND DateColumn < DATEADD(MONTH, 1, @Month); END GO -- bad way #1: GO CREATE PROCEDURE dbo.Bad_LogCountByMonth_1 @Month smalldatetime AS BEGIN SET NOCOUNT ON; DECLARE @c int; SELECT @c = COUNT(*) FROM dbo.SomeLogTable WHERE CONVERT(CHAR(8), DateColumn, 112) LIKE CONVERT(CHAR(6), @Month, 112) + '%'; END GO -- bad way #2: GO CREATE PROCEDURE dbo.Bad_LogCountByMonth_2 @year int, @month int AS BEGIN SET NOCOUNT ON; DECLARE @c int; SELECT @c = COUNT(*) FROM dbo.SomeLogTable WHERE DATEPART(YEAR, DateColumn) = @year AND DATEPART(MONTH, DateColumn) = @month; END GO
Just by looking at it, you probably have a good idea how this going to end. All the same, we can test each set of stored procedures in two different ways:
(a) Getting the data for a single day
- First, let's just do a one-to-one-to-one comparison of the execution plan, just to see what we get:
EXEC dbo.Good_LogCountByDay @date = '20091005'; EXEC dbo.Bad_LogCountByDay_1 @date = '20091005'; EXEC dbo.Bad_LogCountByDay_2 @year = 2009, @month = 10, @day = 5;
As expected, the "Good" version of the procedure has a far more favorable plan, using a clustered index seek as opposed to a clustered index scan. Here is how the plans compare (click to enlarge):

- In case the differences in the plan do not highlight the performance implications, let's run each procedure 1000 times, to see how long it takes. Remember to turn off the "Include Actual Execution Plan" option!
SELECT CURRENT_TIMESTAMP; GO EXEC dbo.Good_LogCountByDay @date = '20091005'; GO 1000 SELECT CURRENT_TIMESTAMP; GO EXEC dbo.Bad_LogCountByDay_1 @date = '20091005'; GO 1000 SELECT CURRENT_TIMESTAMP; GO EXEC dbo.Bad_LogCountByDay_2 @year = 2009, @month = 10, @day = 5; GO 1000 SELECT CURRENT_TIMESTAMP; GO
Results:
2009-10-16 12:05:06.123 2009-10-16 12:05:07.063 (~1 second) 2009-10-16 12:11:09.650 (~6 minutes, 2 seconds) 2009-10-16 12:12:46.197 (~1 minute, 46 seconds)
So, clearly the date range query is far superior to the other two. And while the execution plans for the two "bad" versions of the procedure showed that their costs should be roughly equivalent, in reality it turns out that the procedure that handles the CONVERT() on the left-hand side is far more costly, at least in terms of duration, than the version that uses DATEPART() to extract the year, month and day.
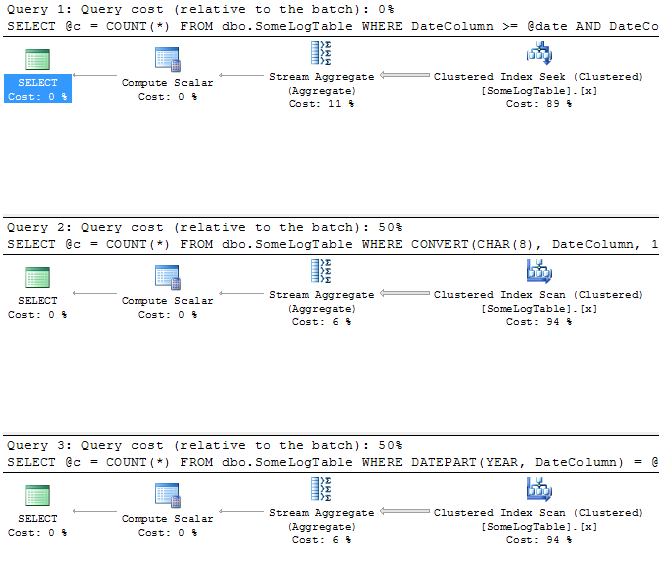
(b) Getting the data for a month
- Let's turn "Include Actual Execution Plan" back on, and compare the plans for the next set of procedures:
EXEC dbo.Good_LogCountByMonth @month = '20091001'; EXEC dbo.Bad_LogCountByMonth_1 @month = '20091001'; EXEC dbo.Bad_LogCountByMonth_2 @year = 2009, @month = 10;
We see a very similar result to the above, where the "good" procedure uses a clustered index seek, and the "bad" procedures use a scan (click to enlarge):
- Now, let's try these procedures 1000 times each, and measure how long they take (again, you don't want to run these loops with execution plan enabled):
SELECT CURRENT_TIMESTAMP; GO EXEC dbo.Good_LogCountByMonth @month = '20091001'; GO 1000 SELECT CURRENT_TIMESTAMP; GO EXEC dbo.Bad_LogCountByMonth_1 @month = '20091001'; GO 1000 SELECT CURRENT_TIMESTAMP; GO EXEC dbo.Bad_LogCountByMonth_2 @year = 2009, @month = 10; GO 1000 SELECT CURRENT_TIMESTAMP; GO
Results:
2009-10-16 12:16:59.727 2009-10-16 12:17:04.383 (~5 seconds) 2009-10-16 12:21:40.640 (~4 minutes, 36 seconds) 2009-10-16 12:23:13.950 (~1 minute, 33 seconds)
Again we see that the date range query performs quite well compared to the other two, and that the CONVERT() version takes far longer to complete than the DATEPART() version. I guess if you are going to continue to use a "bad" approach, you can at least easily determine which is the lesser of two evils. 🙂
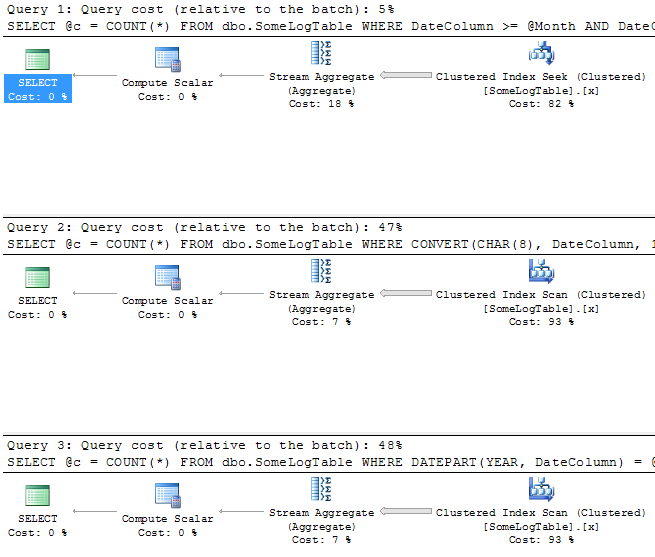
It is not surprising that the performance aspect of the "good" approach shows significant improvement over the nonsargable versions. I could probably also demonstrate cases where you accidentally retrieve too few rows, or too many rows — but this article seems to be getting a little long already, so I'll leave the data correctness discussion for another day.
Don't forget to clean up:
USE [master]; GO DROP DATABASE DateTesting;
A few other tidbits
As an aside, if you only want whole dates, make sure your input validation is functional and that users know what format to enter. Nothing can go right if you let users enter freeform dates and some of them enter d/m/y and others enter m/d/y. Safest to use a calendar control / date picker, then you can dictate exactly what the format is. And to be safe, sanitize the input by converting it to midnight, e.g.:
SET @DateInput = CONVERT(date, @DateInput);
Finally, I have seen stored procedures where DATETIME values are passed in as CHAR(8) or CHAR(10) (and even INT). Don't pass a date into a stored procedure using a string-based or numeric parameter: always use properly typed parameters. If your client-side validation is broken or being bypassed, this can cause problems you can stomp further up the chain by using the correct data type in the first place.
Summary
The main take-away points I was trying to get across in this post are:
- avoid ambiguous formats for date-only literals;
- avoid BETWEEN for range queries;
- avoid calculations on the left-hand side of the WHERE clause; and,
- avoid treating dates like strings.
For a lot more helpful information on date and time, see Tibor Karazsi's article, "The ultimate guide to the datetime datatypes." You can also check out all the other places "date" appears in the index below:
See the full index.
@MPag that seems like an awful lot of additional, unintuitive work just to keep BETWEEN there. What have you gained aside from making the code harder to read?
I don't know if this was already pointed out (perhaps years ago), one way of getting values from only 2009 October 11th would be to just add an additional conditional. May not be hyper-intuitive, and doesn't have any advantage over dropping the BETWEEN and splitting it into a >= and a < component, but changing the WHERE in
SELECT COUNT(*)
FROM dbo.SomeLogTable
WHERE DateColumn BETWEEN '20091011' AND '20091012';
to
WHERE DateColumn BETWEEN '20091011' AND '20091012'
AND DateColumn NOT '20091012' –or <
Hi Darek, I think you're getting into quite subjective territory. Not everyone prefers reading this:
+ CHAR(39) + CHAR(39) + CHAR(39) + CHAR(39)
Over this:
""
Hi there. I'd like to point out that when creating dynamic SQL one should refrain from using quotes-on-quotes-on-quotes but instead use CHAR(39) (which equals ') to mean the single quote. This way code becomes more legible and easier to understand/maintain. So, instead of having 'select t.value from dbo.MyTable as t where t.field = "something";', you should write 'select t.value from dbo.MyTable as t where t.field = ' + char(39) + 'something' + char(39) + ';'. This way you'll never need to have more than 1 single quote in a row. Optionally, you could define a constant (variable) declare @quote char(1) = char(39) and use it in your code instead. I have seen dynamic SQL that had about 8 or 9 quotes in a row… I probably don't have to explain to anyone how hard it was to understand the code, not to mention to debug it… Please try to live by the one simple rule: Code in a way that will make it easy for OTHERS to understand the code itself and what you meant by it. Don't be selfish. Thanks.
I know this is an old thread, but thank you so much for setting me in the right direction. I am finally able to pull my information from SQL after hours of failure…
@Daniel, thanks for the corrections.
Minor correction:
YYYY-MM-DDThh:nn[:ss[:mmm]]
should be
YYYY-MM-DDThh:nn:ss[.mmm]
In other words, seconds are required; ommiting them results in a "Conversion failed when converting date and/or time from character string." error. Also, a period -not a colon- must be used to separate between whole and fractional seconds.
Actually, the supported formats for ISO 8601 dates are as follows:
– YYYY-MM-DDThh:mm:ss[.nnnnnnn][{+|-}hh:mm]
– YYYY-MM-DDThh:mm:ss[.nnnnnnn]Z (UTC, Coordinated Universal Time)
Source: https://msdn.microsoft.com/en-us/library/ms180878.aspx#ISO8601Format
Great article and advice.
@Toofgib: DECLARE @x TABLE(d DATE); INSERT @x(d) SELECT GETDATE(); SELECT d FROM @x;
So If I want to insert only the Date portion into a date datatype for right now I need to do some version of convert/datepart on getdate() b/c it always get time when you call the function or get the current date and put that string into the date datatype field. Right?
@Toofgib if the column is DATE you can just insert GETDATE() and it will strip the time automatically. If the column is DATETIME / SMALLDATETIME / DATETIME2 etc. and you want the date without the time portion, you'll need to insert CONVERT(DATE, GETDATE()).
So If I want to insert only the Date portion into a date datatype for right now I need to do some version of convert/datepart on getdate() b/c it always get time when you call the function or get the current date and put that string into the date datatype field. Right?
good work
Thank You for the assist. I tried the following :
WHERE CHAR(DATE(""1971-12-31"")+G2HIDT days, iso) BETWEEN ""' + @DateStart + ""' AND ""' + @DateEnd + ""'
WITH UR ")'
Works like a charm now.
@Yolande then just use this simpler convert (and don't forget to surround it in quotes, otherwise it will be an integer like 2013 MINUS 8 MINUS 23 = 1992):
BETWEEN "' + CONVERT(CHAR(10), @DateStart, 120) + "' AND "' + CONVERT(CHAR(10), @DateEnd, 120) + "' WITH UR';
Hi,
We are working with a link server to a DB2 database, hence the dynamic sql and doing the CHAR(DATE('1971-12-31')) is the only way we can get the date which is a julian date (17388) converted to a date field (2001-09-01)
Thanks for the blogg.
@Yolande why are you converting a date to a date, and then to a string? Why not use proper parameters? And why is this dynamic SQL? What does CHAR(DATE('1971-12-31')) mean? This does not seem to be valid for SQL Server.
You should have:
SET @sql = 'SELECT … WHERE G2HIDT BETWEEN @DateStart AND @DateEnd';
EXEC sp_executesql @sql, N'@DateStart DATE, @DateEnd DATE', @DateStart, @DateEnd;
Also don't ever declare varchar without length:
/blogs/aaron_bertrand/archive/2009/10/09/bad-habits-to-kick-declaring-varchar-without-length.aspx
Hi, I am new to Db2 and sql. Currently I have a problem using variables in the where clause which have to be converted to Date fields for my between date ranges.
DECLARE @DateStart DATE, @DateEnd DATE, @Sql VARCHAR(8000)
SELECT @DateStart = '2009-07-01'
SELECT @DateEnd = '2009-08-30'
SELECT @Sql = 'Select
UZDMLIB.SDCUHSPD.G2CYCD AS CURR,
UZDMLIB.SDCUHSPD.G2HIDT DATE,
CHAR(DATE("1971-12-31")G2HIDT days, iso) as DATE2,
PFDATE.GRGDAT,
UZDMLIB.SDCUHSPD.G2SPRT,
UZDMLIB.SDCUHSPD.G2MDIN,
UZDMLIB.SDCUHSPD.G2ZONE
FROM UZDMLIB.SDCUHSPD
LEFT JOIN PFDATE ON UZDMLIB.SDCUHSPD.G2HIDT = PFDATE.JULDAT
WHERE CHAR(DATE("1971-12-31")G2HIDT days, iso) BETWEEN '+ CAST(CONVERT (DATE, @DateStart, 102) AS VARCHAR)+'
AND '+ CAST(CONVERT (DATE, @DateEnd, 102) AS VARCHAR) +' WITH UR '
SELECT @SQL
Any assistance will be highly appreciated.
Thanx a lot!!! Saved my time!!
Actually I made a slight error in my previous post. The calculations work throughout the range of the datetime datatype. It was an older version of the calculation which failed on the ultimate date.
DECLARE @FirstDate datetime, @LastDate datetime, @MinDatetime datetime, @MaxDatetime datetime;
SET @FirstDate = '1753.01.01 23:59:59';
SET @LastDate = '9999.12.31 23:59:59';
SET @MinDatetime = DATEDIFF(day, 0, @FirstDate);
SET @MaxDatetime = DATEADD(ms, 86399998, DATEDIFF(day, 0, @LastDate));
PRINT CONVERT(varchar(50), @FirstDate, 121);
PRINT CONVERT(varchar(50), @MinDatetime, 121);
PRINT CONVERT(varchar(50), @LastDate, 121);
PRINT CONVERT(varchar(50), @MaxDatetime, 121);
By the way, @MinDatetime and @MaxDatetime are useful values which should really exist as system constants.
Since you have shown how to calculate the beginning of the day for a datetime, I thought that you might want to see how to calculate the end of the day for a datetime. It only works for datetimes that are less than the ultimate day (12/31/9999). It relies on the fact that the granularity of a datetime is 3 milliseconds and therefore the last possible datetime for a given date is (yyyy.mm.dd 23:59:59.997). This may be helpful for those of you still using SQL Server versions prior to 2008.
DECLARE @StartDate datetime, @EndDate datetime, @BegOfDay datetime, @EndOfDay datetime;
SET @StartDate = '2009.07.01 23:59:59';
SET @EndDate = '2010.07.01 23:59:59';
SET @BegOfDay = DATEDIFF(day, 0, @StartDate);
SET @EndOfDay = DATEADD(ms, 86399998, DATEDIFF(day, 0, @EndDate));
PRINT CONVERT(varchar(50), @StartDate, 121);
PRINT CONVERT(varchar(50), @BegOfDay, 121);
PRINT CONVERT(varchar(50), @EndDate, 121);
PRINT CONVERT(varchar(50), @EndOfDay, 121);
This is just what i was looking for, you answered all the problems i encountered in queying SQL Server with date interval,
Congratulations and cheers from Portugal
John, you're right that it looks messy and seems like an extraneous function call, but you'll note that in the query plan SQL Server is pretty smart about evaluating the DATEADD() only once even when it is on the RHS of the WHERE clause. That's just an observation I made long ago and that has been my habit; I should have explained that better. Of course there is nothing wrong with doing as you suggest, but it can be clutter that is unnecessary, so you can decide what is more important for you.
For the majority of people who use CONVERT(CHAR(8) because it saves a few characters, I think I'd rather they do it this way than keep doing what they're doing. These people are unlikely to add variable declarations and new calculations to their currently single-statement procedures. Baby steps. 🙂
Wouldn't it be even better if you declared another variable, @enddate and did the DATEADD to it BEFORE including it in the WHERE clause? It seems to me that the other way is just another extraneous function call….
I'm confused, SQL has gotten smarter in newer editions? In SQL 2000 "AND DateColumn < DATEADD(MONTH, 1, @Month)" is a bad query because SQL doesn't know that DATEADD(MONTH, 1, @Month) is a constant result and it will make this query over and over again for the complete set of data in the table. Does it know that the function returns a constant result in 2008? How about user defined functions that return constants? Over and over again, I have proven that performance improves by replacing functions in where clauses with a pre-defined variable value. Is my knee-jerk reaction no longer true?
Looking at the execution plans, using a constant and the function take up exactly the same amount of computing. When I built a comparison using SELECT @var=GETUTCDATE()-1 as the smalldatetime comparison, the first, using the constant took 0.4 seconds and the second took 0.2 seconds on my SQL 2005 Express version. I think that benefited from my execution because they both take 0 milliseconds to run now. I also modified my version to take out hours and minutes because I usually want to run this in a script where I use getdate() to find out today's date and I want the same results no matter if I run it in a timed job or a few hours later because the job blew up and I'm called in the middle of the night to re-run it.
Well, "better" is a subjective thing in and of itself, no? In terms of ease of typing, I prefer 2), however in terms of utmost clarity and explicit intent, I prefer 1). And I'm assuming you meant < and not <=. 🙂
Aaron, nice writeup, as usual.
One comment, one question.
Comment:
SELECT COUNT(*)
FROM dbo.SomeLogTable
WHERE DateColumn >= '20091011 00:00:00.000' AND DateColumn <= '20091012 00:00:00.000';
I didn't see the final = in the <= right away. Perhaps you can make it more prominent, either with bolding or in the explanation (or both).
Question: What do you think is better in a non-variable format
1) WHERE DateColumn >= '20091011 00:00:00.000' AND DateColumn <= '20091012 00:00:00.000';
2) WHERE DateColumn >= '20091011' AND DateColumn <= '20091012';
Dave Ballantyne, yes, that's true, SQL Server 2008 is a little smarter about conversions on the left hand side. However since those opportunities are rare (they don't work for almost all of the other data types), I will probably still favor >= and < over a "left hand side" convert.
One thing you have missed, using CAST (column as date) with 2008 uses an index seek
http://sqlblogcasts.com/blogs/sqlandthelike/archive/2009/09/11/datetime-lookups.aspx
Aaron,Brad
>DateColumn LIKE '200910%'… you're kidding, right? You really >came across that!? Incredible.
Have you ever experienced getting the data from AS400:-))
Thats's common to create VARCHAR(n)and fix their garbage in SQL Server
I've got tons on proper DATETIME magic at http://musingmarc.blogspot.com/2006/07/more-on-dates-and-sql.html
Another awesome post.
Speaking of Quebec accents, there's an awesome Text-To-Speech demo by AT&T here:
http://www.research.att.com/~ttsweb/tts/demo.php
(It also entertains kids for a good 1/2 hour)
Select the voice of Arnaud for Quebec French.
Excellent post. I think I've encountered almost every example you list at one time or another.
That same thing happens in T-SQL; people forget the quotes around their date literals. So they become amazed when this returns *every row* from the table:
WHERE DateColumn >= 9/10/2009;
Or when this returns *NO rows* from the table:
WHERE DateColumn >= 20090910;
LIKE '%9/18/2008%'
Love it!
Over 30 years ago I was a tutor at USC's Computer Science center, and a student came up to me and asked why his Fortran program wasn't working. It was some kind of "How many days old are you?" assignment given in class. The instructions for the assignment had step-by-step instructions for converting today's date into some kind of integer. And the last step in the instructions were to "subtract your birthdate from that" to get the number of days from your birthdate to the present date.
The student's code had this line in it:
NUMDAYSOLD = TODAYASINTEGER – 10/8/1959
I had to explain that the compiler had no idea what "10/8/1959" meant. And we was astounded… "It's a computer… it knows everything doesn't it?"
Ahhh… I see your point. The DATEADD part is not really necessary because, even though DATEDIFF by itself is an integer, by SETting @DateInput to that integer value, it just gets implicitly converted back into a datetime value. Got it.
But I guess that goes along with the "0 as base date" bad habit argument.
Yes, there are a truckloads of bad habits/practices… ESPECIALLY with datetimes…one could probably write an entire book on datetime bad practices alone!
Oh and Brad, I found this as hit #1 on a quick search for "datetime like" at groups.google.com: http://is.gd/4mOuD
To save you the trouble, the poster asks why this WHERE clause eliminates all rows:
where isnull(cfgwell.ID,") like '%9/18/2008%'
or isnull(dhs.DateTime,") like '%9/18/2008%'
Thanks Brad, while it's true that you don't explicitly *need* to perform the DATEADD if @DateInput is already a DATETIME or SMALLDATETIME type, you're right that I should be more explicit in that case. You're also right that using 0 as the base date is a bad habit. There are so many to kick, I can't get rid of them all at once!
Another great post in the series…
DateColumn LIKE '200910%'… you're kidding, right? You really came across that!? Incredible.
BTW, in your "Few Other Tidbits" section, the first line of code where you convert to midnight says:
DATEDIFF(day,0,@DateInput)
You forgot the rest:
DATEADD(day,DATEDIFF(day,0,@DateInput),0)
One might argue that another "best practice" is to not use integers (like 0 above), or even decimals (like 0.50 to represent 12 hours), to represent dates in date math, and instead use an actual date:
DATEADD(day,DATEDIFF(day,'20000101',@DateInput),'20000101')
Looking forward to more in the series…
PS thanks to Jonathan Kehayias who prompted this post.