
See the full index.
In my last post in this series, I talked about inappropriately using SELECT, OUTPUT and RETURN in stored procedures. Today I wanted to talk about using SELECT * or omitting the column list entirely.
SELECT *
This is a typical operation when developing, debugging, or testing, and I have no qualms about its use in those scenarios. But there are several reasons why you should avoid SELECT * in production code:
- You can be returning unnecessary data that will just be ignored, since you don't usually need every single column. This is wasteful in I/O and network traffic, since you will be reading (and transmitting) all of that data instead of just the columns you need. SQL Server may make the wrong choice for a plan strategy, since it thinks you need all of the columns it may opt for a scan instead of a seek or introduce key lookups that ultimately were not required.
- When you use SELECT * in a join, you can introduce complications when multiple tables have columns with the same name (not only on the joined columns, such as OrderID, which are typically the same, but also peripheral columns like CreatedDate or Status). On a straight query this might be okay, but when you try to order by one of these columns, or use the query in a CTE or derived table, you will need to make adjustments.
- While applications should *not* be relying on ordinal position of columns in the resultset, using SELECT * will ensure that, when you add columns or change column order in the table, the shape of the resultset will change. Ideally, this should only happen intentionally and not as a surprise.
A major roadblock to using the explicit column list is laziness productivity. For those of you using IntelliSense or 3rd party tools like SQL Prompt, this is much less likely to be a good excuse, since the columns can appear for you in a drop down list (and in some cases you can set up keystrokes that will change * to the explicit column list). For those of you that don't use 3rd party tools, or have disabled IntelliSense due to its chattiness, here's another little tip that is seemingly obscure: expand the table or view, click on "Columns," and drag it onto the query window. This works in both Management Studio:
 Gettin' my lazy on in SSMS
Gettin' my lazy on in SSMS
And in Azure Data Studio:
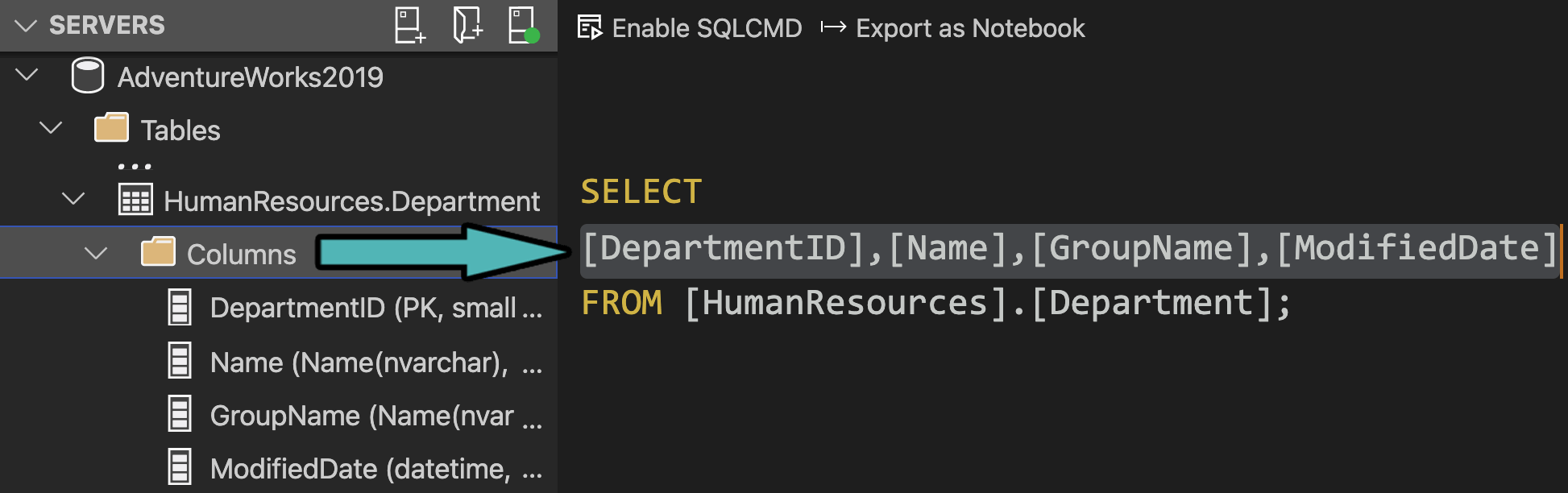 Gettin' my lazy on in ADS
Gettin' my lazy on in ADS
Voila! The column list appears for you… it is probably not in the format you want, since they are just separated by commas and listed out horizontally, and it probably has a lot of square brackets you don't need. But reformatting that list (and removing columns you don't need) can sure beat typing out the columns you do need manually, especially on wider tables. Though being forced to type them out may increase your selectivity and help you decide to leave out the columns you don't need, so maybe the convenience is a toss-up.
SELECT * in a view
Some adopt the misconception that they can avoid maintenance down the road by simply using SELECT * in a view. Then they can change the base table and not worry about updating the view. Let's try this at home, shall we?
USE [tempdb]; GO CREATE TABLE dbo.foo ( a int, b int, c int ); GO INSERT dbo.foo(a, b, c) SELECT 1, 2, 3; GO CREATE VIEW dbo.view_foo AS SELECT * FROM dbo.foo; GO ALTER TABLE dbo.foo ADD d int; GO SELECT d FROM dbo.view_foo; GO -- Error message : Invalid column name 'd'. UPDATE dbo.foo SET d = 4; GO ALTER TABLE dbo.foo DROP COLUMN c; GO SELECT a, b, c FROM dbo.view_foo; GO -- Even though c is no longer in dbo.foo, this works! -- But it returns 4 (the data for d) under column c. EXEC sys.sp_refreshsqlmodule N'dbo.view_foo'; GO SELECT * FROM dbo.view_foo; GO -- Now this returns columns a, b and d as we expect. DROP VIEW dbo.view_foo; DROP TABLE dbo.foo;
This shows it is not a good idea to use SELECT * in a view, because you can't rely on changes to the underlying table(s) to be reflected in the view and its results. The person making the changes to the table has to know and understand that the view must be refreshed in order to ensure correct results (and you can help enforce that by always creating views WITH SCHEMABINDING – now someone can't change the table without being notified about a dependent view). And, in a circular way, WITH SCHEMABINDING prevents you from using SELECT *. Even without SCHEMABINDING, an explicit column list ensures there is no ambiguity caused by metadata changes (but read Itzik's explanation of why it is still a useful option to always use). When you drop a column from the table, for example, the view will break the next time it is queried, instead of potentially returning bogus data in the wrong column.
INSERT … SELECT
A lot of times we build copies of our tables or otherwise populate a table from another table with the same structure. Depending on the columns, it can be tempting to use code like this:
INSERT dbo.foo SELECT a, b, c FROM dbo.bar; -- or even worse: INSERT dbo.foo SELECT * FROM dbo.bar;
If this kind of syntax is used in production code, take care to populate the column lists. This will prevent you from being bitten later when the source table has a column added, or column order is changed in either table. By explicitly defining what you are selecting and where you are putting it, you insulate yourself from these types of metadata changes:
INSERT dbo.foo ( a, b, c ) SELECT a, b, c FROM dbo.bar;
Now, the code will break if you drop or rename a column, but since that is less frequent and because you *should* be notified of that problem immediately, I think that's okay.
SELECT INTO
Similar to the above case, we often build copies of our tables using syntax like this:
SELECT * INTO dbo.foo FROM dbo.bar;
I'm actually okay with this usage, mostly because it is used in an ad hoc fashion, and because it will take into account metadata changes that have happened in the meantime anyway (so if the source table has changed, the destination table will change in the exact same way). Just keep in mind a few things when you use SELECT INTO:
- you *will* get certain table elements such as IDENTITY property (unless you say something like SELECT IdentityColumn = IdentityColumn + 0 INTO…);
- you will *not* get extensions to the table such as indexes and foreign keys; and,
- you cannot dictate which filegroup or partition scheme the destination table will belong to (well, until SQL Server 2017).
Conclusion
As demonstrated above, it is very easy to avoid SELECT *, and there are plenty of good reasons to do so. All of which trump the "efficiency" factor, IMHO.
See the full index.
Ok, firstly I totally agree that in 99.999% of the time SELECT * is evil and should be avoided, but….
I did run into a situation where it wasn't totally awful. At my last company we had a complexish view that was being queried by multiple stored procedures. Now, these procedures were just wrappers on the underlying view, differentiated by their WHERE clause. The view was only used for these stored procedures, so was returning the correct columns back to the procedures. If and when we had to change the columns returned, the view was the only SQL object that needed to be changed. And yes, these columns were required equally by all the procedures as they were ultimately used to populate the same class in the DAL. In this case, I couldn't find a reason not to use SELECT *, as it simply appeared to give us less brittle code. I did trial speed tests using the expanded column list, but SELECT * performed fine. An edge case to be sure, but it still seemed OK to me.
Having said that, this was a VIEW, not a table. EXISTS aside (covered *very* comprehensively above), I still can't think of a single place where it makes sense to SELECT * from an actual table.
There is one other place where I find it okay to use a select *. If I have defined a table in the procedure (temp, table var, CTE, derived table), from there on I don't mind using the select * when referencing that table. You're not going to break anything.
Excellent post. Thanks Aaron!
I'll add my 2 pence (5 cents) worth
I'm sure you will all recognize that if using "Select *" OR "Select <columns I need>"
Both require the SQL server Query processing engine to compile the query (a complex process) and this requires all the relevant metadata for every column specified in the Select Stmt With "Select *" = every column naturally
This invariable means that it would require Stmt will incur a higher memory grant to complete the request and more compile time may also be needed, cached plans are larger in some cases, when say we compare this to a Select query with just those columns needed
@ run time the memory granted to the process may also be higher that is needed, it uses statistical information on the total average row size {all columns requested}.. So I'm sure you can easily see how this can result in committing more memory than was really
We also haven't considered that when requesting columns (you don't need) so of those can be of LOB Data, which may be stored Off-row and those can reduce processing time.
And we haven't even talked about non-clustered or "Covering" indexes that could not only service the request 100% usually with a lower overhead, but the non-clustered indexes you have become less effective as they are used less frequently
So perhaps consider what you are asking the SQL Server do to perform with Select * instead of Select <columns you needed>
A little upfront effort on our part can make the SQL Server perform better in a lot of cases
Not convinced…
Run a few examples .. I know what I'd bet my money being the better performing versions
So is "Select *" OK for quick Adhoc queries (yes I say that’s OK)
? OK for Production quality {And this is my opinion here)
Not something I'd feel comfortable putting my reputation too
I think it's perfectly ok to agree to disagree on this subject. 🙂
Also I am not as much trying to convince you in something as I am interested in hearing your opinion (and maybe your other readers' opinions) on the techniques that our team uses – techniques that happen to take advantage of "select *" clause.
And I really appreciate your time and effort – both to write the original post and to discuss it with strangers.
>> And if you're changing your schema often enough that this is the justification you use for implementing views using SELECT *, I think there is a different problem to solve than reducing maintenance. >>
Well, the changes to the schema happen more often than I'd like to. But it's an "enterprise application", so developers are not the ones to blame for most of those changes.
Unless my memory is failing me, it is "Patterns of Enterprise Application Architecture" by Martin Fowler (http://www.amazon.com/Patterns-Enterprise-Application-Architecture-Martin/dp/0321127420) that contains my favorite definition of "enterprise application". One of the essential traits of such application is higher-than-comfortable rate of requirements changes due to the quirks and fluctuations in business processes.
Speaking of changes…
Example (3). Imagine a view like this one:
create view vProducts as select * from tProducts
i.e. a view that has EXACTLY the same structure as some table. It may seem useless because that's how it looks most of the time (i.e. while the DB schema remains stable). Now, imagine that you have to rename the "Price" column in tProducts to "EndUserPrice" (e.g. because we are about to introduce new column named "DealerPrice"). You'd have to change ALL the code that refers to tProducts.Price and do that all at once. Or you could make MOST of your code use vProducts instead of tProducts (one-time up-front effort) and modify the abovementioned view this way
create view vProducts as
select *, EndUserPrice as Price from tProducts
Now you don't have to eliminate the references to vProducts.Price ALL AT ONCE. You can do it step by step without making operability of the entire system a hostage of one column's name change. Once the "transition" is over.. well, the view would get back to it's original, dull and seemingly useless form. But does it mean that the view is really useless?
I do know that the same trick can be achieved by a computed column, but changes to views seem to be much cheaper and quicker to do – at least in the development environment where I'm working now.
Example #4: A simple view like the one shown in previous example, appears to be a good alternative to computed columns when encapsulating so-called derived attributes – e.g. like this:
create view vProducts as
select
*,
dbo.fPromotionPrice(Price) as PromotionPrice
from tProducts
Especially when the derivation rules are complex and/or change very often (again, please don't blame developers for those changes! :).
Do any of these examples make sense to you?
Sorry, but you haven't convinced me. Now views over views is your defense? Thankfully we do not work in the same environment, because the stuff you're fighting for just wouldn't fly. In the meantime, do what you want of course, I'm not the law. But I still believe I'm entitled to my opinion that SELECT * should never be in production code.
>> Now, if the view is a join between two or more tables, do you still argue that one should just add a column to one of the tables and recompile the view? >>
No. But it was not a goal to enable such simple maintenance adjustments literally everywhere. I'm usually happy with 80/20 rule. 🙂
See my example #2 from the previous post: it's not accidental that the columns' names in the Persons_Ref view are prefixed. This view is "designed" to be used in joins, and prefixes allow to avoid column name clashes in most cases. So when something changes in the set of the person's "essential" attributes, in most cases it'd be enough to make the corresponding change the Persons_Ref view and just recompile the views that use Persons_Ref.* in their select statements.
>> Yarik, what is the point of such a view?
Here is a couple of examples off the top of my head.
(1) Let's say we have Customers and Orders tables, in a 1-to-M relationship. Let's say that when an application needs information about an order, in 80% of cases it also needs some information about the corresponding customer. Instead of repeating the SQL code to join two tables again and again, I create a view that looks like this
create view Orders_Ex as
select Orders.*, Customers.Name from Orders inner join Customers…
and frequently use it instead of the Orders table.
(2) Let's say we have a Persons table with a whole bunch of columns. Information about a person is used all over the system, but in 80% of cases only a few "essential" attributes are important (e.g. name, age and gender only – just to be able to tell the end-user which person is being referred to in a context that is not focused on a given person). Instead of having to remember which corresponding "essential" columns should be specified in most queries involving persons, I create a view like this
create view Persons_Ref as
select
Person_ID,
Person_LastName,
Person_FirstName,
Person_Gender,
Person_BornOn,
dbo.ComputeAgeInYears(BornOn) as Person_AgeInYears
from
Persons
and use it in many other queries (or in other views) like this
select
…
Persons_Ref.*,
…
from
…
inner join Persons_Ref on PersonsRef.Person_ID = …
…
instead of using the Persons table directly and having to repeat the same bunch of columns again and again.
Am I too lazy? Am I necessarily paying some unreasonable performance penalty? Am I committing any other SERIOUS sins here? 😉 Whatever downsides this approach has, I think they are outweighed by the easier maintenance of the views and other code.
Perhaps I could come up with some other examples, but an attempt to modularize SQL code and avoid unnecessary repetition of SQL code might be the most typical reasons to have views that use "select *".
Yarik, what is the point of such a view? If it's just SELECT * FROM table then why not just use the table itself or a synonym in your queries?
I agree with your assessment that a view designed to always return all columns is in the minority. In fact, I don't think I've ever seen it.
Now, if the view is a join between two or more tables, do you still argue that one should just add a column to one of the tables and recompile the view? I think if you are adding columns to the underlying tables, it should be more than just a knee-jerk reaction to recompile the view(s) that reference it with SELECT *. More thought should be put into whether that new column really needs to be returned by that view (and whether the calling application is going to choke when it magically starts appearing).And if you're changing your schema often enough that this is the justification you use for implementing views using SELECT *, I think there is a different problem to solve than reducing maintenance.
A
Aaron,
I don't think you have provided an objective proof that using "select *" in ANY view is a bad habit. If we are talking about views that are designed to ALWAYS return ALL the columns from one or more underlying tables/rowsets, then I believe that using the asterisk is actually a good habit.
Yes, use of "select *" doesn't allow to AVOID further maintenance of a view – alas, contemporary RDBMSes still remain too primitive for that. But I believe this practice does SIMPLIFY further maintenance substantially. Specifically, whenever the underlying schema changes, all you need to do is to recompile the view (as opposed to editing AND recompiling it). In fact, "just recompiling" is so much easier to do that someone, indeed, can write a relatively simple homegrown tool to help with this task.
So the only valid argument that you are making here is that a view with "select *" does have to be recompiled whenever the underlying schema changes. But so does a view with an explicit list of columns, doesn't it? (Remember, we still are talking about views that are designed to ALWAYS return ALL columns! 🙂
Of course, the views designed to ALWAYS return ALL columns are probably a minority among all the views in a typical project. So in the big picture of things, the benefits of using "select *" probably are not that big. But it clearly does provide some maintenance benefits. You just have to know when to use it and when not to use it.
Best regards,
Yarik.
OT, somewhat humorous, an "proof" that SELECT * is faster than SELECT 1 in Oracle: http://asktom.oracle.com/pls/asktom/f?p=100:11:0::::P11_QUESTION_ID:1156151916789#25335122556076
Great discussion! So, it appears (although negligible) that SELECT 1 is faster than SELECT * (Personally, I use SELECT 1). As I think about it, perhaps it was SELECT * is what I read caused the slight overhead (It's the only reason I can think of if I've been using SELECT 1 all these years). I can't remember yesterday, for God's sake. I do remember this being a discussion years ago in the MS forums.
@Aaron:
You have CERTAINLY given sound and objective reasons to avoid SELECT *. If someone comes up with some "proof" or argument as to why one should use SELECT * in production, I think we'll all be shocked. Frankly, I'm surprised there's this much debate/discussion on this blog post about it.
As always, keep up the great work.
Brad:
I agree. I was hoping to demonstrate to Armando that SELECT 1 could be *no worse* than SELECT * in an EXISTS check, in spite of what he vaguely recalled reading or hearing. I was not attempting to state that SELECT 1 is going to be *noticeably* better, but it is slightly faster, regardless of whether or not a human will be able to observe the difference. I'm not sure how many times you ran your tests against the 4,000 column table. But I wonder if a 20- or 40-column table that is getting EXISTS checks performed against it 500 times a second will stand up to the test in the same way. An experiment for another day where I have more free time, perhaps. I'm too busy defending my "non-objective opinions" about why SELECT * is bad news outside of the EXISTS case.
To the others:
I still maintain that I have shown *objective* reasons to broadly avoid SELECT * in column lists (EXISTS issue aside). I have been trying to encourage people to prove to me that SELECT * is *better* in any way than explicitly defining the column lists, other than the typing (and the weak reason that you might misspell a column name, which will be caught at compile time anyway).
Nobody has done that yet. Until then, if you want to avoid the problems I have pointed out, I guess it is just a subjective call.
Technically, SELECT 1 is faster, since Conor verified that SELECT * does an expansion.
However, we're talking a couple of nanoseconds here. As I recall, back when I wrote that blog entry (that Brian mentioned), I did an experiment where I created a table with 4096 columns (and gave them each 128-character names) and used a SELECT * on it within an EXISTS subquery. No matter how hard I tried, I could see no difference in time between doing a SELECT * or a SELECT 1.
I think others have tried similar experiments and have come up with inconclusive results in terms of a time difference as well.
So SQL might expand the * into columns and then throw them out, but the time it takes to do so is so miniscule that it's not worth worrying about.
Heh, i read the replies and thought i got it. Obviously, i need to read it slowly because it is the opposite of what i thought. 🙂
So, technically, SELECT 1 is faster.
Brian,
Conor's post actually seems to confirm the opposite of what Armando suggested, that using SELECT 1 actually creates *less* work for the parser, since it doesn't have to go and bind to the table(s) at compile time. So it seems that SELECT 1 inside EXISTS is actually less overall work for SQL Server, even if at runtime 1 and * are identical. Is there any "evidence" in the two links that I missed, that suggests SELECT * is /better/ than SELECT 1 in an EXISTS / NOT EXISTS?
@Aaron
http://www.sqlskills.com/BLOGS/CONOR/2008/02/default.aspx?page=2
Is that enough evidence? 🙂
Kudos to Brad Schulz for the link:
http://bradsruminations.blogspot.com/2009/09/age-old-select-vs-select-1-debate.html
RJ,
With all the restrictions you now acknowledge, what benefits has your methodology bought you? The only one I can see is less typing on the initial creation – which isn't even typing, because you can generate the list automatically without some custom tool. I don't understand what creating an object with SELECT * instead of SELECT <generated column list> gains, even in the case where you do want every column and it is only one table.
Surely there are cases you can make where SELECT * is right for you. I'm not saying that everyone has to stop using SELECT * tomorrow. The series was aimed at pointing out objective reasons why some of these habits are bad, and attempting to encourage good habits. I think I've done both of those things without swaying from objectivity. In this case, since you admit that you can't use SELECT * all the time, and haven't really pointed out any true benefits to using SELECT * at all, I still think it is a good idea to avoid it. If you use it sometimes, or most of the time, or all of the time, one of the problems I've mentioned is going to bite you at some time. I don't see any problems with always explicitly naming the columns you want, unless you have a very unstable schema, or you are very lazy. 🙂
Armando,
That may have been true at one point, but I can't find any evidence to suggest it is true. When you're selecting a constant there really isn't any validating to do, and the parser has become smart enough to know that within an exists/not exists clause, the select list is completely irrelevant.
Just a quick note on using SELECT * vs SELECT 1 in your EXISTS code. I thought I read somewhere that by using SELECT 1, the query parser had to do extra, negligible work to validate the static value. As a result, SELECT * was theoretically quicker. I'm an old crow so my memory may be failing me.
Aaron, its not "all" our applications do, but some procs do need to return all fields. As I mentioned earlier, the primary use is for RetrieveByID's which we use to load objects, and Reporting Procedures. You are correct, that this becomes a problem with joins, so we are forced to only use * from a single table within any given procedure. Its not a problem for the RetrieveByID's, but it is defintely a problem with Reporting procedures. Hence why i wish there was a feature for * Except like also mentioned above.
Of course in the situtation you provided, when your application can break when you add fields, you want to granularly control what fields are added to each object, * is a bad choice.
RJ,
>> it Eliminates them and allows us to utilize the * to reduce maintenance and bugs.
That might make sense for single-table SELECTs, and where you ALWAYS want EVERY column from the table. If this is all your application does, it is quite frankly not a very complex application at all. What about JOINs? What about cases where you *don't* want to return all 8000+ bytes of every row and only the first two INT columns? How do you tell your tool when to expand * to all columns, and which ones to restrict to otherwise?
As far as adding new columns, what I like about not broadly blasting the new column into every module that references the table is that this can impact the application(s) adversely. When *I* control the SELECT lists, I can add columns to the base tables and views without worrying about how the application will respond to them. Then I can add code for those columns to individual modules gradually and/or as their impact is tested.
Aaron, my comments were not intended to be an attack. I apologize if it came across that way. I haven't bothered to discuss this with other authors on this subject, as I didn't find them to be very objective. I see you as very objective from all your articles I've read, hence I thought it would be worth discussing with you the benefits of * by simply using a tool to do the refreshing for you, in case it was something you hadn't considered.
Btw, such a tool doesn't make the problems more tolerable, it Eliminates them and allows us to utilize the * to reduce maintenance and bugs.
Consider a hierarchy of reporting views\functions several levels deep, and you add\remove columns from base tables. Regardless of if you explicitly list your fields or you use *, you have to manually make your changes or refresh the hierarchy to include\remove the new\removed fields all the way up the hierarchy. With an automated tool, you don’t have find or manually update any of the calling procedures\functions that appropriately use *.
So basically RJ, you're saying that I haven't provided any objective reasons for avoiding SELECT *, regardless of the presence or absence of specialized tools that "repair" these problems/limitations or makes them more tolerable? If those tools were included in the product and worked automatically, I might be inclined to agree. As it stands, I think replacing * with a column list is the right thing to do, and I've already outlined several reasons for that (in other words, it's not just a preference or me saying, "this is what I feel like doing today"). There are important differences that users of all skill levels should be aware of.
I would almost hope COUNT(*) becomes COUNT() making a COLUMN-list optional, and EXISTS subqueries start from the TABLE-list
SELECT moo FROM cow WHERE EXISTS(tab1 WHERE tab1.cow = cow.id);
Then we could ban * completely. 🙂
Hi Aaron,
What I appreciate about your other articles is that you've stayed away from opinion, but I dont think this is the case here. Using * is not bad practice, thats just opinion. Mind you, most of the SQL world agrees with you. I agree with all the downsides you've said about *, but a simple tool that can be written in 2 hours eliminates all of those negatives, and provides the benefit of not having to manually find and update all objects that are affected by your changes. Thus it shouldn't be treated like the plague.
We can agree to disagree, but I fear that with everyone in the SQL world screaming that * is bad form, that eventually it will be deprecated. SSMS 2005 had a bug that still exists in SSMS 2008 in the view designer which replaces * with all the fields in the table, thus modifying your view without the user even knowing.
RJ, you have gone out of your way to make this practice "make sense" for you, and yet I still don't see what "purpose" or "benefit" should be "respected." The fact that you had to build an application to "refresh" columns in modules, explains exactly why SELECT * is not a good idea for the average person, who is not going to have that application standing by to save him/her when he/she adds columns. Too many things can go wrong when you use SELECT *, and given how easy it is to drag a column list into a module, not doing so seems irresponsible to me.
Aaron,
I've read all of your articles on the "Bad Habits" series, and I agree with pretty much everything you said. I especially commend you on staying away from your own opinions. All with the exception for this article. I am constantly seeing people\articles saying that * is bad, and I'm getting tired\annoyed of it.
There is a purpose for it, and it should be respected. I'm not saying that it should always be used, but when you truly need all columns from a table, it's very handy. Instead of finding all objects that need the newly added field, a tool can easily be written (we have written this exact tool) to rip through all sql objects and refresh them to pick up the newly added\dropped fields, and even in the correct order.
The way we have implemented this tool, for production is to automatically run after a database update to the current build and in development whenever it is needed. This saves us boat loads of time in trying figure out where the new columns are needed or where we need to remove the columns.
As a side note, the most common objects were we use * is for RetrieveByID stored procedures to load objects, and reporting procs\views. When a customer wants to utilize one of our views\procs to write their own report and show a field that we don’t, this is greatly appreciated. Also if the customer writes their own proc\view with *, after an update, newly added columns are automatically added, and deleted columns are automatically removed.
What I would love is the ability to do SELECT (* except Field1, Field2, etc). This way, joining two tables could be written SELECT Customer.*, (Order.* EXCEPT CustomerID) FROM Customer inner join order on Customer.CustomerID = Order.CustomerID. But for now, we only ever grab * from the main table that the proc\view is actually written for. Sometimes that table choice is arbitrary.
"When we work on the same project, we can either fight about it"
Now *that* sounds like fun. 🙂
But for bad habits to kick, i would suggest you state what you mean. SELECT * when the intention is to consume the records is a bad idea. No consumption, well, that's a personal choice.
And that's just it; that is my coding style, it's one of the conventions I've always used, and so I am accustomed to it (as are my co-workers). Someone with your coding style is going to have just as much difficulty reading my code, as someone with my coding style is going to have reading yours. So, keep doing what makes sense to you, and I'll keep doing what makes sense to me. When we work on the same project, we can either fight about it, or compromise. This is exactly why I didn't want to get into *actual* conventions, because they always turn into religious battles; there is no way in the world for me to convince you that my convention is better than yours. All I can hope to do is to convince you that I have reasons that make sense to me. If I can't convince you of that, well, maybe I've failed in conveying my reasons, or maybe it doesn't matter whether I've convinced you of anything or not.
And "SELECT 1" is not ambiguous?
Well, maybe not in your coding style…
Obviously I have much more control over the code that I write, than the code that other people write. I can talk as much as I want about bad habits, but I'm not always around to enforce a change. To me, the distinction between 1 and * is clear. And for those to whom it is not clear, I don't see how SELECT * helps, unless they have *your* perspective on the fact that that doesn't mean anything. Since * *does* mean something in a lot of contexts, due to habits I can't directly change, I'd rather lean towards unambiguous. YMMV.
…so, you'll preempt their stupidity by shooting them in the foot for them?
I understand the point about making things work. Even if the next guy is clueless, we are still working toward one goal. Agree or disagree, i understand the point.
But this isn't even that. You want to save a possible future coder wasting a second on "expanded vision" because he might use the bad-practice of "SELECT * " to consume data? IOW, promoting a particular habit because someone else might have a bad habit that might end up using your code?
I understood the personal point. It's not me, but i believe we also wear different color shirts. But the last point about others, seems absurd to me.
… ok, just needed to get that out. 🙂
Brian, I am also concerned about other people who may have to maintain my code. And since a lot of them *do* use SELECT * when they are consuming the results…
Heh, that's so funny. I would find SELECT 1 confusing. To me, SELECT * in code means i don't care about the results, SELECT 1 means i want something. Indeed, it is SELECT 1 that would require "expanded" vision.
We are all so different. Luckily, noone tries standardizing these quirks.
My habit is to use SELECT 1 inside of an EXISTS clause, as opposed to SELECT *. This way I can immediately see that the query does not return data (yes, you can tell that by EXISTS, but you have to expand your vision to see that). I don't see any advantage to using SELECT * ever except in quick, ad hoc queries – never in real code.
IMO, there is only one place where Select * makes sense: an Exists clause. Other than that, it should never appear in production code. If I'm not mistaken, adding SCHEMABINDING would prevent even this use of it.
That can work too Stephen. I don't like the way it jams commas at the beginning of the line, so for my own work, I find the click & drag trick faster as well as easier to reformat. YMMV!
I will many times right click on the table name involved and choose: Script Table as->SELECT to->Clipboard and then past the results to my query window which gives you a fully qualified, decently formatted column listed SELECT query.
Good points Aaron.
I am new to SQL Server and didn't know the tip about click and drag of the Column list – that is going to save me hours – brilliant!
Aaron,
Great blog post! You did a great job explaining the problems with using SELECT *, instead of explicitly specifying your columns names.
Jeff
Thanks Armando, that's a great tip about using SCHEMABINDING, and I didn't really think about it when composing the post. I suspect most people use SCHEMABINDING in views only when they are forced to (e.g. indexed views).
I add WITH SCHEMABINDING to my views to make the views dependent on the table structure
(a) prevents drops of columns to a table that are in the view until you change the view
(b) prevents the creation of a view using SELECT *
(c) forces you to add a schema owner to the tables in the view query