
The other day, I showed you my approach (but not necessarily the best approach for everyone) to splitting a comma-separated list of integers. Some of the functions I threw up there catered to integers specifically, whereas I am sure many of you are splitting more generic data (e.g. strings). So in this post I wanted to show how I split up lists and add a little more flexibility to the approach as well. Some of the limitations of several approaches out there are as follows:
- they are dedicated to breaking up lists of integers;
- they do not guarantee the order of the results;
- they do not allow a user-defined delimiter (e.g. ';' or '|'); and,
- they may or may not allow duplicates.
So what I wanted to do was show some iterative steps you can take when crafting your splitting function that can get around each of these limitations.
The numbers table : the "Special Sauce"™
First, let's start out with a table of numbers table again, as this is one of those auxiliary tools that I consider indispensable. Since the number value is used not only for determining ordering in the list but also for the length of the list, our numbers table needs to be a lot larger. While the MAX datatypes can hold 2GB worth of data, let's assume you have a practical limit of around 200,000 characters passed in to SQL Server. In which case, we simply change the @UpperLimit parameter, and build our numbers table with ~200,000 rows. You can use a higher number if you think you will need it, just note that the larger your numbers table needs to be, the longer this initial population will take.
SET NOCOUNT ON; DECLARE @UpperLimit INT; SET @UpperLimit = 200000; WITH n AS ( SELECT rn = ROW_NUMBER() OVER (ORDER BY s1.[object_id]) FROM sys.objects AS s1 CROSS JOIN sys.objects AS s2 CROSS JOIN sys.objects AS s3 ) SELECT [Number] = rn - 1 INTO dbo.Numbers FROM n WHERE rn <= @UpperLimit + 1; CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers([Number]);
That could take a little longer than the original we created with 10,000 rows, depending on your hardware. But once it's done, we'll be ready to go.
Switching from integers to strings
Recall that the original function for splitting integers looked like this:
CREATE FUNCTION dbo.SplitInts ( @List VARCHAR(MAX) ) RETURNS TABLE AS RETURN ( SELECT DISTINCT [Value] = CONVERT(INT, LTRIM(RTRIM(CONVERT( VARCHAR(12), SUBSTRING(@List, Number, CHARINDEX(',', @List + ',', Number) - Number))))) FROM dbo.Numbers WHERE Number <= CONVERT(INT, LEN(@List)) AND SUBSTRING(',' + @List, Number, 1) = ',' ); GO
There are a few changes we need to do right off the bat in order to handle strings as opposed to integers. We need to change VARCHAR to NVARCHAR if we need to support Unicode, prefix all of our string literals with N, and get rid of the explicit conversion to INT. So to start with, our function will look like this:
CREATE FUNCTION dbo.SplitStrings_v1 ( @List NVARCHAR(MAX) ) RETURNS TABLE AS RETURN ( SELECT DISTINCT [Value] = LTRIM(RTRIM( SUBSTRING(@List, [Number], CHARINDEX(N',', @List + N',', [Number]) - [Number]))) FROM dbo.Numbers WHERE Number <= LEN(@List) AND SUBSTRING(N',' + @List, [Number], 1) = N',' ); GO
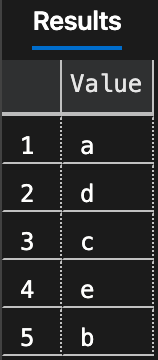
Right now the function does not allow duplicates, by using the DISTINCT keyword. What this also does is forces a sort in the query plan, which means the results will typically come out in alphabetic order, as opposed to in the order they were defined in the list. (We'll deal with that shortly; just as a note, this behavior is relatively predictable, but NOT guaranteed. Kind of like mistakenly using TOP 100 PERCENT … ORDER BY in views.)
SELECT [Value] FROM dbo.SplitStrings_v1(N'e,d,c,a,b');
Allowing a custom delimiter
What if your strings need to embed commas? You don't want to use commas as delimiters if commas are real values that could naturally occur in your data. But you might have a hard time finding another sensible delimiter that isn't part of your data, or that isn't part of ALL of your data. So instead we can allow the delimiter to be specified at runtime, so your exports from Excel which are comma-separated can be handled differently from your exports from SalesForce which are pipe-delimited. We do this by adding an input parameter and removing the hard-coding of the comma and its length:
CREATE FUNCTION dbo.SplitStrings_v2 ( @List NVARCHAR(MAX), @Delimiter NVARCHAR(10) ) RETURNS TABLE AS RETURN ( SELECT DISTINCT [Value] = LTRIM(RTRIM( SUBSTRING(@List, [Number], CHARINDEX ( @Delimiter, @List + @Delimiter, [Number] ) - [Number]))) FROM dbo.Numbers WHERE Number <= LEN(@List) AND SUBSTRING ( @Delimiter + @List, [Number], LEN(@Delimiter) ) = @Delimiter ); GO
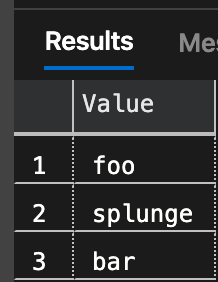
(I assume 10 characters will be enough, so you could pass in a string like 'foo//////////bar//////////splunge' and it will work fine):
SELECT [Value] FROM dbo.SplitStrings_v2(N'foo//////////bar//////////splunge', N'//////////');
Guaranteeing order of results
You'll notice that in both of the above cases, the strings are returned in alphabetical order, as opposed to the order they appear in the input list. Many users' first inclination will be to add ORDER BY [Number] to the SELECT inside the function, but of course you can't have ORDER BY inside a table-valued function:
The ORDER BY clause is invalid in views, inline functions, derived tables, subqueries, and common table expressions, unless TOP or FOR XML is also specified.
And no, you will not catch me pretending that I can force the behavior by adding TOP 100 PERCENT. (We have discussed this at length, and a Google search yields plenty more.)
We could simply add the Number column to the result set, and order by that when calling the function, but that means we will stop preventing duplicates — since DISTINCT applies to the entire set, and each Number will only appear once, this will make every row unique by definition.
CREATE FUNCTION dbo.SplitStrings_v3 ( @List NVARCHAR(MAX), @Delimiter NVARCHAR(10) ) RETURNS TABLE AS RETURN ( SELECT DISTINCT [Number], [Value] = LTRIM(RTRIM( SUBSTRING(@List, [Number], CHARINDEX ( @Delimiter, @List + @Delimiter, [Number] ) - [Number]))) FROM dbo.Numbers WHERE Number <= LEN(@List) AND SUBSTRING ( @Delimiter + @List, [Number], LEN(@Delimiter) ) = @Delimiter ); GO SELECT [Number], [Value] FROM dbo.SplitStrings_v3(N'foo,bar,foo,splunge', N',');
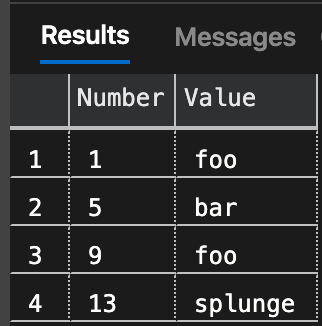
Notice that now the results are returned in the input order, even with DISTINCT. You can now easily override this at the query level by using ORDER BY [Number] or ORDER BY [Value]. But you still have duplicates. You could also use the ROW_NUMBER() function to return the rank as opposed to the actual character position within the string. You can try this with the DISTINCT keyword, but the result will be the same. I am going to drop it for now.
CREATE FUNCTION dbo.SplitStrings_v4 ( @List NVARCHAR(MAX), @Delimiter NVARCHAR(10) ) RETURNS TABLE AS RETURN ( SELECT [Position] = ROW_NUMBER() OVER (ORDER BY [Number]), [Value] = LTRIM(RTRIM( SUBSTRING(@List, [Number], CHARINDEX ( @Delimiter, @List + @Delimiter, [Number] ) - [Number]))) FROM dbo.Numbers WHERE Number <= LEN(@List) AND SUBSTRING ( @Delimiter + @List, [Number], LEN(@Delimiter) ) = @Delimiter ); GO SELECT [Position], [Value] FROM dbo.SplitStrings_v4(N'foo,bar,foo,splunge', N',');
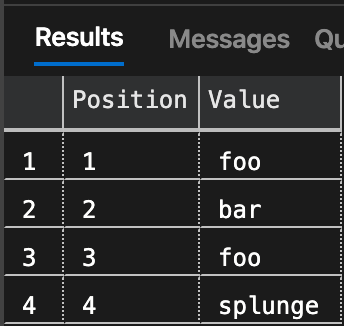
With or without DISTINCT, the rows returned are the same, and foo is always returned twice. The difference between the two options above is that one returns the actual starting character position of each string in the list, and the other just returns the ranking.
So how do we solve the case where we want to return the output in the original order, *and* prevent duplicates?
Preventing or allowing duplicates
This solution is a little more involved. I'm sure some genius out there can come up with a shorter path, but this is what I came up with in the time I was allotted to deliver the feature. (Deadlines can be a bit tight at times.) It looks really ugly, but it works well enough through my testing.
CREATE FUNCTION dbo.SplitStrings_v5 ( @List NVARCHAR(MAX), @Delimiter NVARCHAR(10), @AllowDuplicates BIT ) RETURNS TABLE AS RETURN ( SELECT [Position] = ROW_NUMBER() OVER ( ORDER BY [Position] ), [Original_Position] = [Position], [Value] FROM ( SELECT [Position], [Rank] = ROW_NUMBER() OVER ( PARTITION BY [Value] ORDER BY [Position] ), [Value] FROM ( SELECT [Position] = ROW_NUMBER() OVER ( ORDER BY [Number] ), [Value] = LTRIM(RTRIM( SUBSTRING(@List, [Number], CHARINDEX ( @Delimiter, @List + @Delimiter, [Number] ) - [Number]))) FROM dbo.Numbers WHERE Number <= LEN(@List) AND SUBSTRING ( @Delimiter + @List, [Number], LEN(@Delimiter) ) = @Delimiter ) AS x ) AS y WHERE [Rank] = CASE WHEN @AllowDuplicates = 0 THEN 1 ELSE [Rank] END ); GO -- allow duplicates: SELECT [Position], [Original_Position], [Value] FROM dbo.SplitStrings_v5(N'foo,bar,foo,splunge', N',', 1) ORDER BY [Position]; -- do not allow duplicates: SELECT [Position], [Original_Position], [Value] FROM dbo.SplitStrings_v5(N'foo,bar,foo,splunge', N',', 0) ORDER BY [Position]; -- do not allow duplicates, and order alpha: SELECT [Position], [Original_Position], [Value] FROM dbo.SplitStrings_v5(N'foo,bar,foo,splunge', N',', 0) ORDER BY [Value];

Note that you can't get away from the ORDER BY on the output. But you can change it to support both alphabetical or position-based ordering, whether or not you need to weed out duplicates. Just remember that you'll need to add your own ROW_NUMBER() call to the outer query if you want any sort of ranking to be attached to the results.
A side note : SQL Injection
–CELKO– will try to convince you that, unless you use an individual parameter for each element, you are open to SQL injection. Personally, I don't think this particular approach is any more exposed to SQL injection attacks than his approach. I challenged him to show how this method increased the risk for SQL injection, and he has yet to respond. The truth is that he is simply not familiar enough with T-SQL to appreciate the benefits of NOT having to hard-code hundreds of parameters to a stored procedure, never mind have to deal with the mess required to populate those parameters from application code.
If I were doing some type of dynamic SQL with each element in the string, e.g.:
DECLARE @sql NVARCHAR(MAX); SELECT @sql = COALESCE(@sql, N'') + N'DROP TABLE ' + [Value] + ';' FROM dbo.SplitStrings_v1('dbo.foo,dbo.bar'); EXEC(@sql);
Then why is that any different, never mind more dangerous, than doing some type of dynamic SQL with each individual parameter, e.g:
EXEC('DROP TABLE ' + @param1); EXEC('DROP TABLE ' + @param2); -- etc.
If you're doing this kind of thing then you need to thwart SQL injection no matter how the strings get into the code. I just can't stand it when people throw around scary buzzwords to make you believe that something is inherently unsafe. If this method of splitting is unsafe, please reply and demonstrate with an explained example, given that I am not just blindly executing the strings that are passed in (there is no dynamic SQL in any version of the function). If you are just paranoid because of Celko's authoritative stance, then by all means, use his bazillion parameters solution, which I commented about in my previous post. But don't let him bully you into unsubstantiated beliefs … make an informed decision.
Conclusion
I hope this was a useful demonstration of how we can tweak an inline table-valued function to split up strings and return the results with different behaviors. Of course if performance is a primary concern, I still urge you to check out other solutions, including those that use CLR (again see my previous post).
So, what kind of input/output problems do you think I've been working on lately? I'll give you three guesses, and two of them don't count. I'll pick which two.
Agreed 100%, Linchi. About the SQLCLR solutions, too. With the amount of time and effort people put into this, and the number of questions on forums, etc, on an almost daily basis, this stuff should really be built in. And TVPs are not enough. I'm on a 100% 2008 project right now, with full control, and I still need a numbers table to play some games with both string manipulation and other tasks. It's truly a sad state of affairs.
I agree that it is a problem that some basic pieces of functionality are still missing from this language after so many years.
That said, even if they add something like this in 2008 R2, which we know they won't – heck, even if it were available in 2008 – many people in the community are still literally years away from seeing these versions in production. So even if it were added to the engine, a large portion of the audience would not be able to take advantage. This is the kind of thing that takes several "generations" if you will to become common usage. It was only after SQL Server 2008 was well underway before I started really advocating CTEs, ROW_NUMBER() etc., because I knew a large portion of the audience was still on 2000.
So what do we do in the meantime? We need to code things that work on SQL Server 2005 (and some of us even 2000, though I'll admit much of the above doesn't work there). Some of us have the luxury of using SQLCLR, but not all of us. Some of us can even use table-valued parameters on SQL Server 2008, but that percentage is even lower. So for now the lowest common denominator is how we're going to solve a lot of these problems.
Personally, I'm appalled by all these efforts to split a list in T-SQL. This is not directed towards you, Aaron, but towards the general state of things in this regard in the SQL Server community. The root cause of all these torturous efforts in splitting lists in T-SQL–that's right, it's a torture–is the lack of proper supporting constructs, such as direct access to regular expressions, in T-SQL to perform this task. It's further exacerbated by the desire of many to stick to the so-called set-based solutions when the problem itself is not very set based.
If some of the .NET regular expression methods are simply exposed through a very thin wrapper to T-SQL, it can save the community tons of time and enormous wasted efforts in coming up with various clever, but nevertheless, painful solutions. But until then, I guess the torture will continue.