
I show the safest and most efficient ways to perform grouped concatenation in SQL Server.

I show the safest and most efficient ways to perform grouped concatenation in SQL Server.

Tip : Why the SQL Server FORCESCAN hint exists

This month's T-SQL Tuesday is about assumptions in SQL Server.

Following a recent update, I take a first look at a new performance enhancement and trace flag (2453) aimed at improving cardinality estimates for table variables and table-valued parameters.

I look at some unexpected behavior with the CASE expression and some of its derivatives.

Tip : Connect to SQL Servers in another domain using Windows Authentication

Tip : Choosing Between SQL Server 2012 and SQL Server 2014

I take a closer look at the overhead of using Extended Events to track the creation of #temp tables.

I show how you can use Extended Events to track temp table creation and identify which session created which #temp table.

Tip : Get more info about failed logins using Extended Events

Tip : Enforce Database Naming Conventions Using DDL Triggers

Tip : Handle conversion between time zones in SQL Server – part 3

I perform some deeper testing on triggers, showing that INSTEAD OF triggers are worth a look.

Tip : Validate the contents of large dynamic SQL strings in SQL Server
Tip : Handle conversion between time zones in SQL Server – part 2
Tip : Handle conversion between time zones in SQL Server – part 1

Tip : Avoid using NOLOCK on SQL Server UPDATE and DELETE statements

I revisit an old post and explores approaches to calculating the median across partitioned sets.
I follow up on a running totals post with an article describing different ways to achieve the same types of results for more complex grouping and aggregation.

I demonstrate how IDENT_CURRENT cannot be relied upon for reporting your new IDENTITY value, even under SERIALIZABLE.

I talk a little more about in-memory table-valued parameters, and explains why some scenarios you test may not demonstrate the power of this technology.

I explained how I justified purchasing a new Mac Pro, and show that it is very tough to order a comparable PC at similar price points.
Tip : Improve Efficiency by Switching to INSTEAD OF Triggers
I highlight a couple of potential problems discovered in various AdventureWorks-based In-Memory OLTP samples out there, and how to work around them.
After an initial look at in-memory TVPs at small scale proved promising, I take a closer look at trying to match more values against a much larger table.

I investigate a deadlock issue with alias types and table-valued parameters, and the Connect items that have sprung up about this issue.

Tip : Script to Set the SQL Server Database Default Schema For All Users

I discuss a common requirement, generating random numbers to serve as surrogate keys, and show how you can avoid the incremental cost of preventing collisions.

Tip : Generating Random Numbers in SQL Server Without Collisions
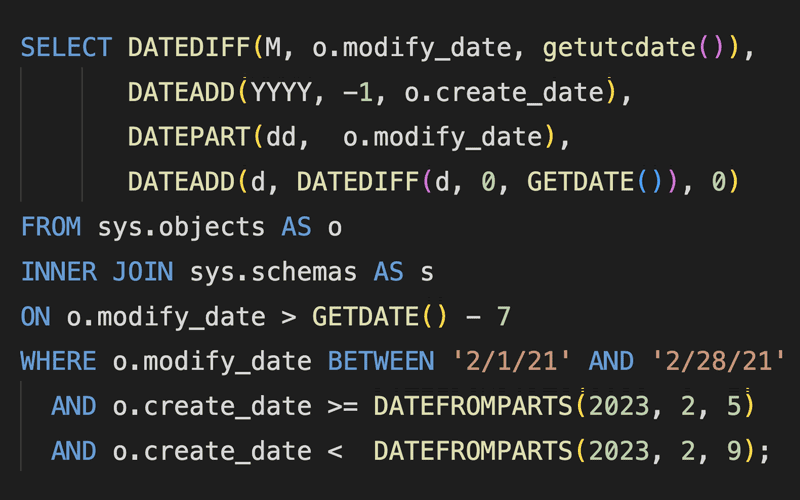
I investigate a case where two different methods of deriving an inline constant can lead to very different cardinality estimates.

I discuss a case where assumptions can lead to a poorly-performing query and where exploring other options can pay off.

I reflect on the presentation I gave during the PASS Performance VC Summer Performance Palooza 2013 on June 27th, including responses to Q & A.

Tip : Use UNPIVOT to dynamically normalize output
Tip : Use UNPIVOT operator to help normalize output

I explore a few additional places to get information useful for decisions about creating new indexes that are suggested as "missing" by various tools.
Tip : Extend DDL Triggers for more functionality: Part 2

I talk about a subtle way that ad hoc queries can interfere with SQL Server performance by taking up more space in the plan cache than they really need.
Tip : Extending SQL Server DDL Triggers for more functionality: Part 1

I go into a little more detail about what happens to metadata when you use schema transfers behind the scenes.

I discuss some obstacles he recently encountered when configuring an Availability Groups lab environment and how some assistance from the community helped me isolate and solve the issues.

I explore a couple of advantages and a hefty list of limitations with filtered indexes in SQL Server 2008 and above, with links to no less than 36 Connect items.

I discuss ways to optimize large delete operations, both to make them faster, and to minimize impact on the transaction log.
See how you can protect your execution plans with a free PowerShell script from Jonathan Kehayias of SQLskills.

I had a great time at the MVP Summit last week. Caught up with a lot of friends, tried some new foods, and took in some great technical sessions.

Tip : Move all SQL Server indexed views to a new filegroup

There is an important MERGE "wrong results" bug, involving indexed views, that could be affecting your queries right now.

In part 3, I shift focus to generating sequences of dates.

In this installment, I talk about the next level of scale: generating sets of 50,000 and 1,000,000 numbers.