
Last August, I wrote a lengthy post about how I handle splitting up a list of integers that are passed into a procedure as a comma-separated list.
I am still using this method in 2010. But since almost a year has passed, and because there have been plenty of articles written about splitting in the meantime, I've decided to try out a couple of other methods — to make sure I was still "doing the right thing." First I wanted to test out Adam Machanic's CLR approach. I also took a great interest to the XML splitting methods publicized via a T-SQL tennis match between MVPs Brad Schulz and Adam Haines (part I and part II). And I wanted to test Peter Larsson's derived table approach. I also thought it only fair to compare a few of the methods I've used in the past before coming across these faster and/or more scalable solutions, if for nothing else, to illustrate how far we've come.
I'm not going to revisit why you may want to process a list of integers instead of handling each integer individually. I'm going to assume that, like me, you have cases where you simply don't know how many values might be passed in a parameter list… causing you to ditch the approach by Celko where he has n individual parameters so he can enjoy type safety at the cost of code that is long and horribly hard to maintain (see one of his illogical rants on this).
The Functions
First, I will outline the 9 methods I'm going to compare, in no particular order:
#1: RBAR 1
This is the solution I see most often out in the wild. What does RBAR mean? "Row by agonizing row." I'm not sure where I first picked up that term, but because it sounds so much like "FUBAR," I really like it. While most solutions do use loops of some sort, this is the worst kind… take a chunk off the list, do some stuff with it, insert it into the table, assign a new value to the list, then move on to the next part of the list. Here is the function:
CREATE FUNCTION dbo.SplitInts_RBAR_1 ( @List VARCHAR(MAX), @Delimiter CHAR(1) ) RETURNS @Items TABLE ( Item INT ) AS BEGIN DECLARE @Item VARCHAR(12), @Pos INT; WHILE LEN(@List) > 0 BEGIN SET @Pos = CHARINDEX(@Delimiter, @List); IF @Pos = 0 SET @Pos = LEN(@List)+1; SET @Item = LEFT(@List, @Pos-1); INSERT @Items SELECT CONVERT(INT, LTRIM(RTRIM(@Item))); SET @List = SUBSTRING(@List, @Pos + LEN(@Delimiter), LEN(@List)); IF LEN(@List) = 0 BREAK; END RETURN; END
#2: RBAR 2
This is a very slight variation on RBAR1 (can you spot the differences?), but results in about twice as many reads when just outputting the data (the reads are roughly the same when using the data for more practical purposes, like joining with existing tables). For those wishing to stick with RBAR for whatever reason (remember what it sounds like), you may want to compare RBAR 1 and RBAR 2 and see if you can ensure that your functions are not suffering from performance problems you might not know about.
CREATE FUNCTION dbo.SplitInts_RBAR_2 ( @List VARCHAR(MAX), @Delimiter CHAR(1) ) RETURNS @Items TABLE ( Item INT ) AS BEGIN DECLARE @Item VARCHAR(12), @Pos INT; SELECT @Pos = 1; WHILE @Pos > 0 BEGIN SELECT @Pos = CHARINDEX(@Delimiter, @List); IF @Pos > 0 SELECT @Item = LEFT(@List, @Pos - 1); ELSE SELECT @Item = @List; INSERT @Items SELECT CONVERT(INT, LTRIM(RTRIM(@Item))); SELECT @List = RIGHT(@List, LEN(@List) - @Pos); IF LEN(@List) = 0 BREAK; END RETURN; END
#3: CTE 1
This function uses a recursive CTE, with the first element and the remainder functioning as the anchor query, whittling down each element in turn. It inserts into the @table variable until you reach the last element.
CREATE FUNCTION dbo.SplitInts_CTE_1 ( @List VARCHAR(MAX), @Delimiter CHAR(1) ) RETURNS @Items TABLE ( Item INT ) AS BEGIN WITH ints(item, remainder) AS ( SELECT item = SUBSTRING(@List, 1, CHARINDEX(@Delimiter, @List)-1), remainder = LTRIM(RTRIM(SUBSTRING(@List, CHARINDEX(@Delimiter, @List) + 1, LEN(@List)))) UNION ALL SELECT item = SUBSTRING(remainder, 1, CHARINDEX(@Delimiter, remainder)-1), remainder = LTRIM(RTRIM(SUBSTRING(remainder, CHARINDEX(@Delimiter, remainder) + 1, LEN(remainder)))) FROM ints WHERE CHARINDEX(@Delimiter, remainder) > 0 ) INSERT @Items SELECT item FROM ints OPTION (MAXRECURSION 0); RETURN; END
#4: CTE 2
This function is similar to the above recursive query, however it uses the positions in the string and fewer LEN() calls to extract each value.
CREATE FUNCTION dbo.SplitInts_CTE_2 ( @List VARCHAR(MAX), @Delimiter CHAR(1) ) RETURNS @Items TABLE (Item INT) AS BEGIN DECLARE @Len INT = LEN(@List) + 1; WITH a AS ( SELECT [start] = 1, [end] = COALESCE(NULLIF(CHARINDEX(@Delimiter, @List, 1), 0), @Len), [value] = LTRIM(RTRIM(SUBSTRING(@List, 1, COALESCE(NULLIF(CHARINDEX(@Delimiter, @List, 1), 0), @Len)-1))) UNION ALL SELECT [start] = CONVERT(INT, [end]) + 1, [end] = COALESCE(NULLIF(CHARINDEX(@Delimiter, @List, [end] + 1), 0), @Len), [value] = LTRIM(RTRIM(SUBSTRING(@List, [end] + 1, COALESCE(NULLIF(CHARINDEX(@Delimiter, @List, [end] + 1), 0), @Len)-[end]-1))) FROM a WHERE [end] < @len ) INSERT @Items SELECT [value] FROM a WHERE LEN([value]) > 0 OPTION (MAXRECURSION 0); RETURN; END
#5: Numbers table
This is the solution I am currently using in my production instances of SQL Server 2005 and SQL Server 2008. It uses a numbers table and, up until this week, was the fastest method I had tested to date.
CREATE FUNCTION dbo.SplitInts_Numbers ( @List VARCHAR(MAX), @Delimiter CHAR(1) ) RETURNS TABLE AS RETURN ( SELECT Item = CONVERT(INT, LTRIM(RTRIM( SUBSTRING(@List, Number, CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number)))) FROM dbo.Numbers WITH (NOLOCK) WHERE Number <= CONVERT(INT, LEN(@List)) AND SUBSTRING(@Delimiter + @List, Number, 1) = @Delimiter );
#6: Inline 1
This is a similar approach to the numbers table solution (first spotted as written by Peso but with some minor adjustments), without requiring access to a numbers table. This does populate a local table variable in the body of the function, in order to make use of a less complex CTE to generate a sufficient set of integers.
CREATE FUNCTION dbo.SplitInts_Inline_1 ( @List VARCHAR(MAX), @Delimiter CHAR(1) ) RETURNS @Items TABLE ( Item INT ) AS BEGIN WITH v0 AS ( SELECT n = 0 UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9 UNION ALL SELECT 10 UNION ALL SELECT 11 UNION ALL SELECT 12 UNION ALL SELECT 13 UNION ALL SELECT 14 UNION ALL SELECT 15 ), v1 AS ( SELECT 16 * v0.n AS n FROM v0 ), v2 AS ( SELECT 256 * v0.n AS n FROM v0 ), v3 AS ( SELECT 4096 * v0.n AS n FROM v0 ), v4 AS ( SELECT 65536 * v0.n AS n FROM v0 WHERE n < 2 ) INSERT @Items SELECT Item = CONVERT(INT, (SUBSTRING(@Delimiter + @List + @Delimiter, w.n + 1, CHARINDEX(@Delimiter, @Delimiter + @List + @Delimiter, w.n + 1) - w.n - 1))) FROM ( SELECT n = v0.n + v1.n + v2.n + v3.n + v4.n FROM v0, v1, v2, v3, v4 ) AS w WHERE w.n = CHARINDEX(@Delimiter, @Delimiter + @List + @Delimiter, w.n) AND w.n < LEN(@Delimiter + @List); RETURN; END
#7: Inline 2
Similar to the one above, but this time without the local table variable. You'll see that a lot more numbers had to be hard-coded into the function definition, but this will potentially pay off in terms of reads (stay tuned).
CREATE FUNCTION dbo.SplitInts_Inline_2 ( @List VARCHAR(MAX), @Delimiter CHAR(1) ) RETURNS TABLE AS RETURN ( SELECT Item = CONVERT(INT, (SUBSTRING( @Delimiter + @List + @Delimiter, w.n + 1, CHARINDEX(@Delimiter, @Delimiter + @List + @Delimiter, w.n + 1) - w.n - 1 ))) FROM ( SELECT n = v0.n + v1.n + v2.n + v3.n FROM ( SELECT n = 0 UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9 UNION ALL SELECT 10 UNION ALL SELECT 11 UNION ALL SELECT 12 UNION ALL SELECT 13 UNION ALL SELECT 14 UNION ALL SELECT 15 ) AS v0, ( SELECT n = 0 UNION ALL SELECT 16 UNION ALL SELECT 32 UNION ALL SELECT 48 UNION ALL SELECT 64 UNION ALL SELECT 80 UNION ALL SELECT 96 UNION ALL SELECT 112 UNION ALL SELECT 128 UNION ALL SELECT 144 UNION ALL SELECT 160 UNION ALL SELECT 176 UNION ALL SELECT 192 UNION ALL SELECT 208 UNION ALL SELECT 224 UNION ALL SELECT 240 ) AS v1, ( SELECT n = 0 UNION ALL SELECT 256 UNION ALL SELECT 512 UNION ALL SELECT 768 UNION ALL SELECT 1024 UNION ALL SELECT 1280 UNION ALL SELECT 1536 UNION ALL SELECT 1792 UNION ALL SELECT 2048 UNION ALL SELECT 2304 UNION ALL SELECT 2560 UNION ALL SELECT 2816 UNION ALL SELECT 3072 UNION ALL SELECT 3328 UNION ALL SELECT 3584 UNION ALL SELECT 3840 ) AS v2, ( SELECT n = 0 UNION ALL SELECT 4096 UNION ALL SELECT 8192 UNION ALL SELECT 12288 UNION ALL SELECT 16384 UNION ALL SELECT 20480 UNION ALL SELECT 24576 UNION ALL SELECT 28672 UNION ALL SELECT 32768 UNION ALL SELECT 36864 UNION ALL SELECT 40960 UNION ALL SELECT 45056 UNION ALL SELECT 49152 UNION ALL SELECT 53248 UNION ALL SELECT 57344 UNION ALL SELECT 61440 UNION ALL SELECT 65536 UNION ALL SELECT 69632 UNION ALL SELECT 73728 UNION ALL SELECT 77824 UNION ALL SELECT 81920 UNION ALL SELECT 86016 UNION ALL SELECT 90112 UNION ALL SELECT 94208 UNION ALL SELECT 98304 UNION ALL SELECT 102400 UNION ALL SELECT 106496 UNION ALL SELECT 110592 UNION ALL SELECT 114688 UNION ALL SELECT 118784 UNION ALL SELECT 122880 UNION ALL SELECT 126976 UNION ALL SELECT 131072 UNION ALL SELECT 135168 UNION ALL SELECT 139264 UNION ALL SELECT 143360 UNION ALL SELECT 147456 ) v3 ) w WHERE w.n = CHARINDEX(@Delimiter, @Delimiter + @List + @Delimiter, w.n) AND w.n < LEN(@Delimiter + @List) );
#8: CLR
This was an adaptation of Adam Machanic's CLR approach (as mentioned above), with very minor modifications to return a table of integers instead of strings. I won't re-list his CLR function but will gladly share my modifications. You may want to play with Erland's CLR version as well, which is a lot more straightforward and will potentially scale equally well, at least to moderately-sized strings. Here is the wrapper to the function (I created a StringHelper.dll with several user-defined functions, including SplitInts()):
CREATE FUNCTION dbo.SplitInts_CLR ( @List NVARCHAR(MAX), @Delimiter CHAR(1) ) RETURNS TABLE ( Item INT ) EXTERNAL NAME [StringHelper].[UserDefinedFunctions].[SplitInts]; GO
#9: XML
Again, this solution was thrown into the mix due to some heavy touting and promise indicated by Brad Schulz. I've always been wary of XML solutions for splitting / concatenating because of the overhead of constructing and deconstructing the XML around the data. Soon we'll see if my concerns are justified.
CREATE FUNCTION dbo.SplitInts_XML ( @List VARCHAR(MAX), @Delimiter CHAR(1) ) RETURNS TABLE AS RETURN ( SELECT Item = CONVERT(INT, Item) FROM ( SELECT Item = x.i.value('(./text())[1]', 'INT') FROM ( SELECT [XML] = CONVERT(XML, '<i>' + REPLACE(@List, @Delimiter, '</i><i>') + '</i>').query('.') ) AS a CROSS APPLY [XML].nodes('i') AS x(i) ) AS y WHERE Item IS NOT NULL );
Some details
I'm leaving out error handling for brevity, and I'm also leaving out any validation that the list consists of only integers — I'm going to assume that you can perform that kind of checking much more efficiently in your application code, and can add it to the T-SQL side if you see fit. I'm also not worrying at this stage about removing duplicates or about preserving the order that the values were originally defined in the list.
Finally, I wanted to ensure that each solution could handle 50,000 entries in the list; since your needs may be a lot more modest than this, you may want to pare down your entries to improve performance (for example, you don't need as many entries in "Inline 2", and your Numbers table can contain fewer rows – for some solutions, you'll need a numbers table covering 14 * <max number of elements> since an INT can be up to 12 digits and the comma and perhaps a space). In this situation, since I knew all of my values would be <= 2 characters and I didn't have any embedded spaces, I didn't really need a Numbers table quite so large, and I didn't really need to define so many permutations in the "Inline 2" function.
The Testing Process
First, since a few of the solutions require a numbers or tally table, I prepared the following table:
SET NOCOUNT ON; DECLARE @UpperLimit int = 256000; ;WITH n AS ( SELECT x = 1 UNION ALL SELECT x = x + 1 FROM n WHERE x < @UpperLimit ) SELECT [Number] = x INTO dbo.Numbers FROM n WHERE x <= 256000 OPTION (MAXRECURSION 0); GO CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers([Number]);
Then I started a trace with a filter of TextData LIKE '%dbo.SplitInts%' and with the following columns: TextData, Reads, Writes, CPU, Duration. Once the trace was running, I ran the following code block three times, giving me a good sample of how each solution performs:
DECLARE @List VARCHAR(MAX) = '1,2,3,4,5,6,7,8,9,10,', @Delimiter CHAR(1) = ','; DECLARE c CURSOR LOCAL STATIC READ_ONLY FORWARD_ONLY FOR SELECT List FROM ( SELECT r = 1, List = REPLICATE(@List, 10) UNION ALL SELECT r = 2, List = REPLICATE(@List, 50) UNION ALL SELECT r = 3, List = REPLICATE(@List, 100) UNION ALL SELECT r = 4, List = REPLICATE(@List, 500) UNION ALL SELECT r = 5, List = REPLICATE(@List, 1000) UNION ALL SELECT r = 6, List = REPLICATE(@List, 2500) UNION ALL SELECT r = 7, List = REPLICATE(@List, 5000) ) AS x ORDER BY r; OPEN c; FETCH NEXT FROM c INTO @List; WHILE @@FETCH_STATUS = 0 BEGIN SELECT Item FROM dbo.SplitInts_CLR (@List, @Delimiter); SELECT Item FROM dbo.SplitInts_RBAR_1 (@List, @Delimiter); SELECT Item FROM dbo.SplitInts_RBAR_2 (@List, @Delimiter); SELECT Item FROM dbo.SplitInts_Numbers (@List, @Delimiter); SELECT Item FROM dbo.SplitInts_XML (@List, @Delimiter); SELECT Item FROM dbo.SplitInts_CTE_1 (@List, @Delimiter); SELECT Item FROM dbo.SplitInts_CTE_2 (@List, @Delimiter); SELECT Item FROM dbo.SplitInts_Numbers_1(@List, @Delimiter); SELECT Item FROM dbo.SplitInts_Numbers_2(@List, @Delimiter); FETCH NEXT FROM c INTO @List; END DEALLOCATE c;
I ran the test 10 times, then pulled averages from the trace tables for each function and element count.
Results
In terms of duration, CLR won every time. Heck, CLR won every time in every category. (This might not come as a big surprise to you. After all, just yesterday, I let the cat out of the bag by declaring that I'd finally given in and am letting the CLR into my life.)
But if you are one of many who are not able to implement CLR functions in your production environments, you may want to pay attention to some of the other methods. In the chart below I've highlighted the winners and losers as follows: longest duration at each interval (red), shortest duration at each interval (light green), and the shortest duration other than CLR (even lighter green). Note that "CTE 1" for 50,000 elements, at over 26,000ms total duration, is way off the chart.
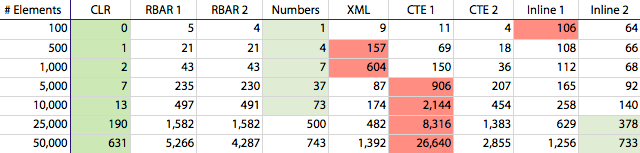
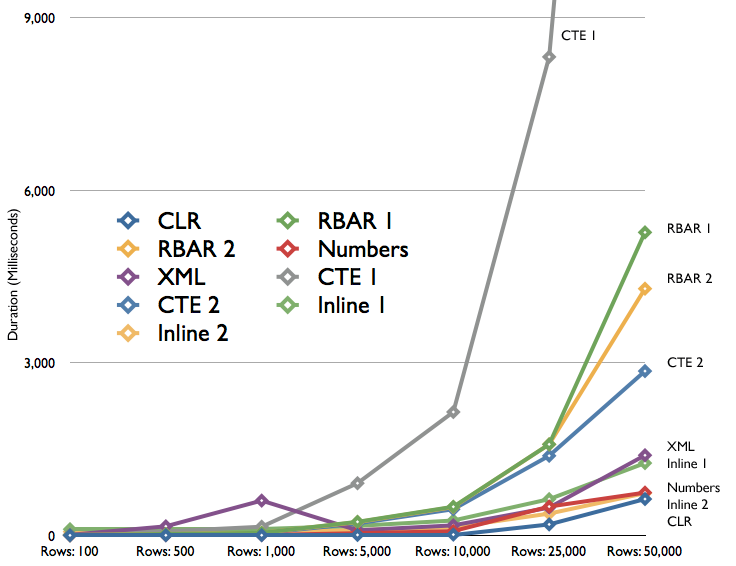 Duration, in milliseconds, for splitting delimited strings of varying numbers of elements
Duration, in milliseconds, for splitting delimited strings of varying numbers of elements
We can see that duration for the CLR method and a few others creep up very slowly, while several of the remaining methods increase at a much more rapid pace. There is also an inexplicable bump for the XML method at 500 and 1,000 elements, where duration is longer than found with 25,000 elements. I thought this may be an anomaly or due to other pressure on the box, but this was repeatable time and time again. We can also see that the "CTE 1" method is the absolute worst performer at 5,000 rows and above, and that aside from the CLR method, the numbers table was the winner up to 10,000 elements; beyond that, the "Inline 2" method took over — but granted, not by much.
As mentioned before, I examined reads, writes, CPU and duration to compare these different splitting techniques. CPU correlated almost identically to duration, so I'm not going to bother repeating a similar chart as above. Writes did not seem to factor in; the only method that performed any writes to speak of was the "CTE 1" function, and based on duration alone we are discarding that as an alternative in any case. Here are the reads (again I've highlighted the winners in green and the losers in red):
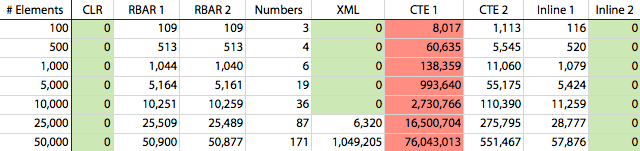 Logical reads, in 8K pages, for splitting delimited strings of varying numbers of elements
Logical reads, in 8K pages, for splitting delimited strings of varying numbers of elements
I didn't graph the reads because, due to the range of values involved, I'd have to do it logarithmically to even present it on your screen, and that would take away some of the "punch" you get with these numbers. 🙂
What I've Learned
If you are going to be mainly dealing with < 100 items in your lists, then the difference between the various methods was so minuscule, it was not even worth mentioning the actual figures. Even at 1000 items, the only real loser was the XML method (even though the reads on the CTE methods might make you think otherwise). Once you get over 10,000 items in the list, you start to see a greater separation between the men and the boys; there is clearly a set of options that yield unacceptable performance, and a set of options that aren't all that different. To a large degree, the duration figures correlate almost directly to the reads, but even though several methods provide the same 0-level of reads, the CLR always wins in duration. You may nit-pick and find little things that will make various methods a little bit faster, but I don't think there is anything ground-breaking that will change any function's performance by an order of magnitude.
The major lessons to learn here are as follows:
- You should test all available solutions both with varying numbers of parameters. In this case if I had tested only against a smaller list, I might have ended up with a solution that would have been a real performance problem should I need to deal with thousands of elements — and without proper testing scenarios in place, this would most likely happen at an inconvenient time.
- While this stands true for any type of performance test, I couldn't leave it out: If you are running tests on a local machine or a test server, you should test on the destination hardware as well, since there are many factors that could change performance in that environment. Without belaboring the point too much, I had slightly different results on a local machine with less RAM and fewer processors that might have led me in a different direction if I had been less thorough.
- The usage of LEN() or DATALENGTH(), combined with using a @table variable inside the function to hold intermediate results, can increase the reads and overall duration in a major way; it is clear that certain functions above are not optimized for this type of implementation.
Conclusion
Based on these tests, I will be proceeding with introducing CLR functions to my primary systems to help with certain string functionality. For now, I will be limiting this to splitting, concatenation, parsing, and RegEx matching. For splitting specifically, as time goes on, we are introducing more and more bits of functionality that require accepting application data in a list (permissions, network associations, etc.), and I am looking only slightly ahead to a day where we will need to process thousands of items in some of these lists. While the overall duration and read savings compared to a numbers table was quite modest, centralizing this functionality for further extensibility and without the limitations of T-SQL UDFs seems to be a worthwhile investment to me.
Soon I hope to perform some tests revolving around file system access, since we have several C# command-line apps, as well as inline T-SQL using xp_cmdshell, all for the purpose of processing files. These files are almost always processed in the same type of way; the biggest difference is either the location or the purpose of the file.
Aaron thanks for the great article.
I am testing it with a lots of data to a certain limit all is good everything working as expected, but beyond a certain limit in my case it is length of numbers is 18 and there are 32,000 numbers like this everything working fine reads scans everything is in limit as soon as i increase amount of number say 32,050 suddenly whole scenario is different there are reads in millions writes in thousands. Why this is happening. I believe it has some connection with system cache or something like this. But i like to understand what exactly is happening in background could you please help me with that?
Thanks
I have long descriptive varchar(max) column
declare @str varchar(max)
set @str = 'Guidelines and recommendations for lubricating the required components of your Adventure Works Cycles bicycle. Component lubrication is vital to ensuring a smooth and safe ride and should be part of your standard maintenance routine. Details instructions are provided for each bicycle component requiring regular lubrication including the frequency at which oil or grease should be applied'
I want to split the long string into multiple rows at the first space after 50 characters so the word is not split between with the sequence no. i also dont want to trim any spaces in the string while splitting which is caused by len function.
so the out put required should be like as follows
'Guidelines and recommendations for lubricating the' 1
' required components of your Adventure Works Cycles ' 2
' bicycle. Component lubrication is vital to ensuring' 3
and so on…
Would appreciate any help.
Some of the functions are proprietary, and not of much use for general consumption. But I will consider a blog post with the others. Will take some time to sort out, so I won't promise anything too short-term.
Any chance of you sharing your CLR library of tools? (It sounds like a great starter utility package.)
Hi Aaron…
I wrote a (tongue-in-cheek) follow-up to this Integer List Splitting Roundup:
http://bradsruminations.blogspot.com/2010/08/integer-list-splitting-sql-fable.html
Hope you enjoy it…
–Brad
Yes, I tested just a few I liked the most. For my purposes I needed to support a variable delimiter, so I've adjusted the Numbers function to work with a variable delimiter.
I've changed the parameter to CHAR(1). Hope that meets your approval.PS I don't think you've tested all of the functions. A few of them worked fine with the VARCHAR(10), but others assume single character, and as I indicated before, I don't think it's worth making them all support > 1 character.
BTW, I needed this function to split strings, not integers, but I assumed I can use your code and just adjust slightly to return string. I agree that for splitting integers 1 character delimiter will make more sense. But in this case the parameter declaration needs to be corrected (to not give false hope). 🙂
Hi Aaron,
If the @Delimiter is varchar(10), I assume that I can pass any delimiter up to 10 characters and it is supposed to work. Otherwise you need to declare the @Delimiter as char(1). I tested a few functions today and none worked correctly when I passed '],' as a delimiter.
Sorry NaomiN, but I disagree. For splitting strings, you might have an argument – you may need to pick an obscure sequence of characters that won't naturally occur in the data. For splitting integers, I really doubt that you have production code that concatenates integers with anything other than a comma or pipe or similar characters. Can you explain some kind of use case that explains why I "need" to do anything?
Several function listed here don't work with the delimiters with 2 or more characters. You need to adjust the code in these functions.
I would be interested in your sharing of your CLR string library as it sounds like it has a number of very useful functions in one place.
Joe Celko has written quite a bit on tally/number/sequence tables as well. Of course he's not too thrilled with MS SQL Server. 🙂
Scott: Jeff did not introduce tables of numbers to the world of SQL Server; he has actually credited me with introducing him to the topic, and I certainly did not invent it. I believe Steve Kass or Anith Sen originally developed the technique.
Another Modenism is the "Tally" table (a.k.a. a "numbers" table). Check it out on SQL Server Central as Jeff also brought the Tally table to the land of TSQL.
Howdy Aaron, I just wanted to let you know that the term RBAR (pronounced "ree-bar") was coined by Jeff Moden. Jeff is the best TSQL Ninja that I have ever met and I had the good fortune to have worked with him at my last job. He has many posts on the SQLServerCentral.Com site if you want to see more of his work.
I am missing one "RBAR3" version where there is no string cutting at all, just moving pointers.. Do you have the time to test "RBAR3" too?
CREATE FUNCTION dbo.fnParseList
(
@Delimiter CHAR,
@Text TEXT
)
RETURNS @Result TABLE (RowID SMALLINT IDENTITY(1, 1) PRIMARY KEY, Data VARCHAR(8000))
AS
BEGIN
DECLARE @NextPos INT,
@LastPos INT
SELECT @NextPos = CHARINDEX(@Delimiter, @Text, 1),
@LastPos = 0
WHILE @NextPos > 0
BEGIN
INSERT @Result
(
Data
)
SELECT SUBSTRING(@Text, @LastPos + 1, @NextPos – @LastPos – 1)
SELECT @LastPos = @NextPos,
@NextPos = CHARINDEX(@Delimiter, @Text, @NextPos + 1)
END
IF @NextPos <= @LastPos
INSERT @Result
(
Data
)
SELECT SUBSTRING(@Text, @LastPos + 1, DATALENGTH(@Text) – @LastPos)
RETURN
END
Hi Matija, thought about TVP but it's the only solution where I couldn't just swap out the function. There are many pages in the app and methods in the UI where comma-separated strings are passed into the procedures that then call these functions to break apart the list. Converting to TVP is a bit prohibitive for this exercise because I don't want to change the interface or behavior of any of those procedures.
Have you considered adding the TVP method just for comparison?
Thanks for an excellent roundup, Aaron! I'm glad we have a definitive "go-to" destination for this entire issue.
Strange, that bump in the XML figures… I'll have to look further into that one. Thanks for including it in your tests.
–Brad
You're right AMB, my tests do assume some level of sanitized input (also why I do not deal with error handling, duplicate elimination, order preservation, etc).
Aaron,
Thank you for sharing this test with us. No doubt that the CLR method is the way to go if you can not use table-valued parameters.
One thing to notice, is that some of the functions do not return same resultset, using same parameters. For example, the methods inline 1 / 2, and Numbers will return zero for an empty element, so we can not know if the element was zero or empty, whilts the XML will exclude the empty elements. Fixing this will not change the results, but it will be fair to program each function to have same behavior, at least for this comparison.
Cheers,
AMB