
In my previous job, we had several cases where schema changes or incorrect developer assumptions in the middle tier or application logic would lead to type mismatches. We would have a stored procedure that returns a bit column, but then change the procedure to have something like this:
...CASE WHEN <condition> THEN 1 ELSE 0 END
In this case SQL Server would return an int as a catch-all, and if .NET was expecting a boolean, BOOM. Wouldn't it be nice if the application could check the result set of the stored procedure, and construct its data types using that information?
Another case would be where the schema has changed, but the applications can't all be updated at once. Wouldn't it be great to be able to tell SQL Server what the column name should be, what data type you want, or in what collation, as part of the stored procedure call?
How often have you cursed the bizarre behavior of SET FMTONLY ON?
And finally, how many times have you been frustrated by the output of system procedures like sp_who2, which returns SPID twice – and worse yet, as a char(5) column instead of an int?
Improvements in SQL Server 2012
You can deal with each of these scenarios with some new procedures and dynamic management functions introduced in SQL Server 2012. They offer new functionality to either discover or control the metadata of queries, without actually having to run them, store temporary results elsewhere, or use SET FMTONLY ON. Some examples:
Inspect output of queries without piecing together catalog views
Picture a very simple table like this:
CREATE TABLE dbo.x ( foo int NOT NULL, bar decimal(12, 2), blat varchar(20), mort nvarchar(32), splunge nvarchar(MAX), whence datetime2(4) NOT NULL );
And then a query like this:
SELECT * FROM dbo.x;
Today, if I want the application to understand the data types that are coming back from this query, I would have to create queries against the catalog views sys.columns and sys.types, for example:
SELECT [column] = c.name, [type] = t.name, c.max_length, c.[precision], c.scale, c.is_nullable FROM sys.columns AS c INNER JOIN sys.types AS t ON c.system_type_id = t.system_type_id AND c.user_type_id = t.user_type_id INNER JOIN sys.objects AS o ON c.[object_id] = o.[object_id] INNER JOIN sys.schemas AS s ON o.[schema_id] = s.[schema_id] WHERE s.name = N'dbo' AND o.name = N'x' ORDER BY c.column_id;
Results:

This leaves some serious gaps, since I have to perform all kinds of manipulations to put these outputs into true data type definitions:
- check max_length for -1 and switch it to MAX
- check for nchar/nvarchar and cut max_length in half
- piece together the precision and scale for *some* numeric- and date-based types.
There is a new dynamic management function in SQL Server 2012, sys.dm_exec_describe_first_result_set, which will take a query and produce a much more concise description of the data types coming back in the query. While the function returns other columns, I'll focus on the ones that are most useful for describing resultsets and creating new tables based on them.
DECLARE @sql nvarchar(max) = N'SELECT * FROM dbo.x;'; SELECT name, system_type_name, is_nullable FROM sys.dm_exec_describe_first_result_set(@sql, NULL, 0) AS f ORDER BY column_ordinal;
Results:

Clearly this is a lot less work and manipulation to get the data types consistent – all of the "compound" data types come back exactly as you need to define them. So let's imagine you want to generate CREATE TABLE scripts to store the data from a bunch of DMVs or your own views or other queries; again, you can do this without writing very complex queries against the catalog views or with piecing together the data types manually. Here's a simple example that generates a CREATE TABLE statement to store the data from sys.dm_exec_sessions in your own repository table:
SET NOCOUNT ON; DECLARE @sql nvarchar(max), @create nvarchar(max) = N'CREATE TABLE dbo.SessionsDMV ( CaptureTimestamp datetime2(3) NOT NULL DEFAULT sysdatetime()'; SET @sql = N'SELECT * FROM sys.dm_exec_sessions;'; SELECT @create += ',' + CHAR(13) + CHAR(10) + ' ' + name + ' ' + system_type_name + CASE is_nullable WHEN 0 THEN ' NOT' ELSE ' ' END + ' NULL' FROM sys.dm_exec_describe_first_result_set(@sql, NULL, 0) AS f; SELECT @create += CHAR(13) + CHAR(10) + N');'; PRINT @create; -- EXEC sys.sp_executesql @create;
The results (on a much more modern version of SQL Server, mind you) are not exactly how I would want them formatted, but you can play with the query above so the code conforms better to your standards.
CREATE TABLE dbo.SessionsDMV ( CaptureTimestamp datetime2(3) NOT NULL DEFAULT sysdatetime(), session_id smallint NOT NULL, login_time datetime NOT NULL, host_name nvarchar(128) NULL, program_name nvarchar(128) NULL, host_process_id int NULL, client_version int NULL, client_interface_name nvarchar(32) NULL, security_id varbinary(85) NOT NULL, login_name nvarchar(128) NOT NULL, nt_domain nvarchar(128) NULL, nt_user_name nvarchar(128) NULL, status nvarchar(30) NOT NULL, context_info varbinary(128) NULL, cpu_time int NOT NULL, memory_usage int NOT NULL, total_scheduled_time int NOT NULL, total_elapsed_time int NOT NULL, endpoint_id int NOT NULL, last_request_start_time datetime NOT NULL, last_request_end_time datetime NULL, reads bigint NOT NULL, writes bigint NOT NULL, logical_reads bigint NOT NULL, is_user_process bit NOT NULL, text_size int NOT NULL, language nvarchar(128) NULL, date_format nvarchar(3) NULL, date_first smallint NOT NULL, quoted_identifier bit NOT NULL, arithabort bit NOT NULL, ansi_null_dflt_on bit NOT NULL, ansi_defaults bit NOT NULL, ansi_warnings bit NOT NULL, ansi_padding bit NOT NULL, ansi_nulls bit NOT NULL, concat_null_yields_null bit NOT NULL, transaction_isolation_level smallint NOT NULL, lock_timeout int NOT NULL, deadlock_priority int NOT NULL, row_count bigint NOT NULL, prev_error int NOT NULL, original_security_id varbinary(85) NOT NULL, original_login_name nvarchar(128) NOT NULL, last_successful_logon datetime NULL, last_unsuccessful_logon datetime NULL, unsuccessful_logons bigint NULL, group_id int NOT NULL, database_id smallint NOT NULL, authenticating_database_id int NULL, open_transaction_count int NOT NULL, page_server_reads bigint NOT NULL, contained_availability_group_id uniqueidentifier NULL );
You could use similar logic to build the INSERT query that would be required to take periodic snapshots.
Best guess at undeclared parameters
There is also a new stored procedure, sys.sp_describe_undeclared_parameters, that will allow you to inspect a T-SQL batch and determine the data types of any, well, undeclared parameters. As an example, what are the data types of the variables that will ultimately be passed into this query text? (This is something an application developer will often struggle to determine in order to program around these queries.)
SELECT name FROM sys.objects WHERE [object_id] = @ObjectID -- int? bigint? OR (name LIKE @ObjectName); -- varchar? nvarchar? how long?
On first glance, these types may be obvious to some, but certainly not to all. And people guess wrong all. the. time.
The new procedure can provide answers with more certainty:
EXEC sys.sp_describe_undeclared_parameters @tsql = N'SELECT name FROM sys.objects WHERE [object_id] = @ObjectID OR (name LIKE @ObjectName);';
Partial results:

This returns a lot of other columns as well, but even the above should show how the stored procedure will be able to examine large and complicated T-SQL batches and describe all of the parameters that are used. (Be aware, though, that I said "best guess" because the parameter inspection is imperfect.)
Convert output data types explicitly
In this example, let's say we have a simple table and stored procedure:
CREATE TABLE dbo.Users ( UserID int PRIMARY KEY, Email nvarchar(320) NOT NULL UNIQUE, IsActive bit NOT NULL DEFAULT (1) ); GO INSERT dbo.Users(UserID, Email) VALUES(1, N'[email protected]'); GO CREATE PROCEDURE dbo.Users_GetActiveList AS BEGIN SET NOCOUNT ON; SELECT UserID, Email FROM dbo.Users WHERE IsActive = 1 ORDER BY Email; END GO
And if we call that procedure:
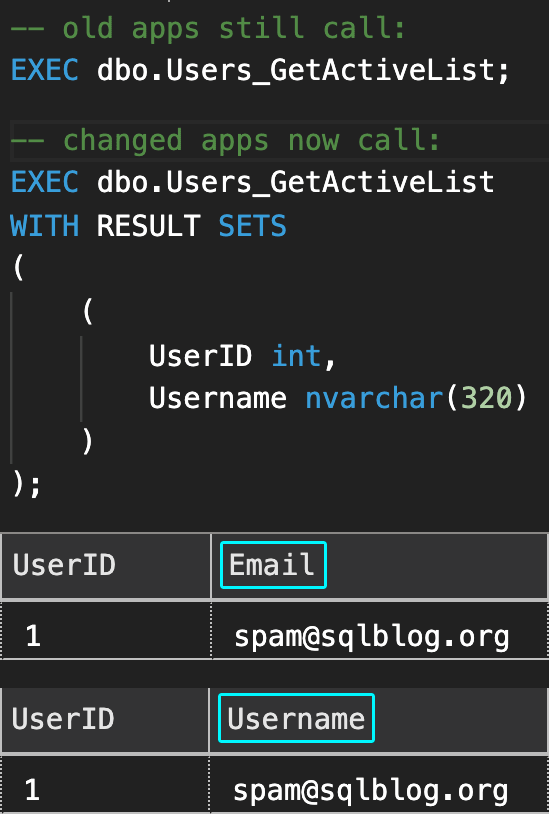
EXEC dbo.Users_GetActiveList;
Results:

Now a business logic change is coming that changes Email to Username because a username no longer has to be an e-mail address. We could change the column name in the table and in the stored procedure, but imagine we have multiple applications that call this stored procedure, and we don't have control over all of them (they are distributed, belong to a vendor, or are on a different release cadence).
For the apps we can alter now, we can change the call to:
EXEC dbo.Users_GetActiveList WITH RESULT SETS ( ( UserID int, Username nvarchar(320) ) );
This gives us the freedom to change the column to the new name, and the query in the stored procedure so that the old name is still referenced for the apps we can't change yet:
EXEC sys.sp_rename N'dbo.Users.Email', N'Username', N'COLUMN'; GO ALTER PROCEDURE dbo.Users_GetActiveList AS BEGIN SET NOCOUNT ON; SELECT UserID, Email = Username FROM dbo.Users WHERE IsActive = 1 ORDER BY Username; END GO
When the other apps catch up, we can simply remove the Email = alias. But in the meantime, the old apps can continue obvious of any change, and the apps we can change can completely absorb the new column name:
Fix output of system stored procedures
When I used to run sp_who2, I would cringe. (These days, of course, I use sp_whoisactive.) But it is a good example of a widely-used stored procedure that has, well, imperfect output. There are two SPID columns for some reason and, for some other reason, both are char(5). And there is a column called BlkBy, a name that is unnecessarily truncated (it is also a char(5), but I'll leave it this way).
Here is an example of using WITH RESULT SETS to make the output more consumable:
EXEC [master].sys.sp_who2 WITH RESULT SETS ( ( [SPID] int, -- <-- fixed the data type [Status] nvarchar(32), [Login] sysname, HostName sysname, Blocker char(5), -- <-- renamed this column [Database] sysname, Command nvarchar(32), CPUTime varchar(30), DiskIO varchar(30), LastBatch varchar(48), ProgramName nvarchar(255), Redundant_SPID int, -- <-- renamed and fixed type RequestID int ) );
You could also replace some of those reserved word column names so you don't need square brackets all over the place.
Make more usable output in Management Studio
In SQL Server 2012, there is a new system stored procedure called sys.sp_server_diagnostics, which returns some core system health metrics in XML format. Unfortunately, the implementation returns this XML data as a string, which makes the output pretty useless in Management Studio. (I complained about this in Connect #625262, but they didn't seem to agree with my reasoning.)
In order to make the output more useful, we can do the following to convert the last column to XML, making it clickable within SSMS grid results:
EXEC sys.sp_server_diagnostics WITH RESULT SETS ( ( create_time datetime, component_name varchar(20), [state] int, state_desc varchar(20), data xml ) );
In the results, we can now click on the data column in any row, and it will open a new XML document that is much easier to read and parse.
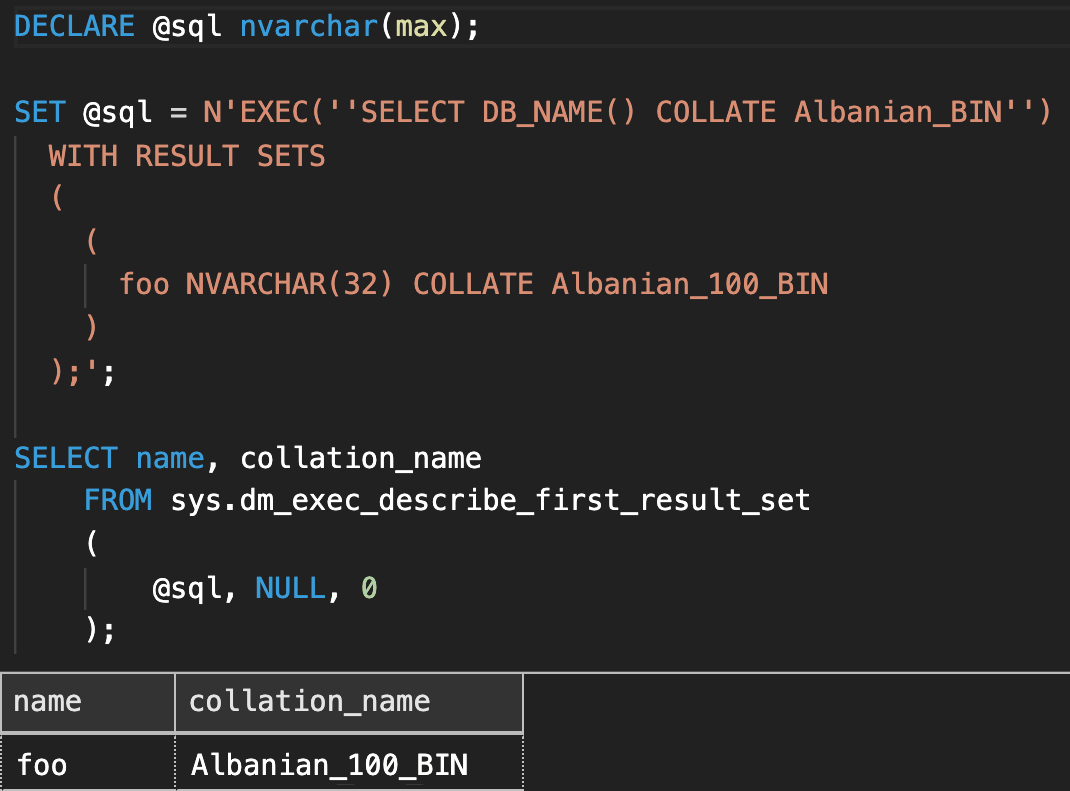
Changing the output collation
If a query is outputting a column in a certain collation, you can override that collation using WITH RESULT SETS. Here is an example that changes Albanian_BIN to Albanian_100_BIN:
DECLARE @sql nvarchar(max); SET @sql = N'EXEC(''SELECT DB_NAME() COLLATE Albanian_BIN'') WITH RESULT SETS ( ( foo NVARCHAR(32) COLLATE Albanian_100_BIN ) );'; SELECT name, collation_name FROM sys.dm_exec_describe_first_result_set ( @sql, NULL, 0 );
Easier translation in SSIS
Finally, here is a blog post from James Rowland-Jones demonstrating how EXEC ... WITH RESULT SETS can be very handy in SSIS: Denali – Using EXECUTE WITH RESULT SETS (example using SSIS Source Adaptors)
Caveats
There are a few other things to point out about these new features.
First resultset only
The DMVs and stored procedures for describing result sets are currently written to only inspect the *first* resultset. So for something like sp_help, it will only assist in determining the very first set of output. I suspect they will correct this in the future, and am thankful they named the objects in an unambiguous way.
No #temp tables
There are certain types of batches that will simply return an error when you try to examine them. For example, while a batch with a table variable can be passed to sys.sp_describe_first_result_set, a batch with a temp table cannot:
EXEC sys.sp_describe_first_result_set @tsql = N'CREATE TABLE #y (j INT);SELECT j FROM #y;';
The metadata could not be determined because statement 'SELECT j FROM #y;' uses a temp table.
Double parentheses
WITH RESULT SETS requires a double-nesting of parentheses. If you try the following:
EXEC (N'SELECT foo = 1;') WITH RESULT SETS ( -- ( foo tinyint -- ) );
Results:
Incorrect syntax near 'foo'.
To get around this, you will need to un-comment the commented parentheses. The reason this syntax is required (and the reason WITH RESULT SETS is plural) is that you can dictate the shape of multiple result sets, as demonstrated here:
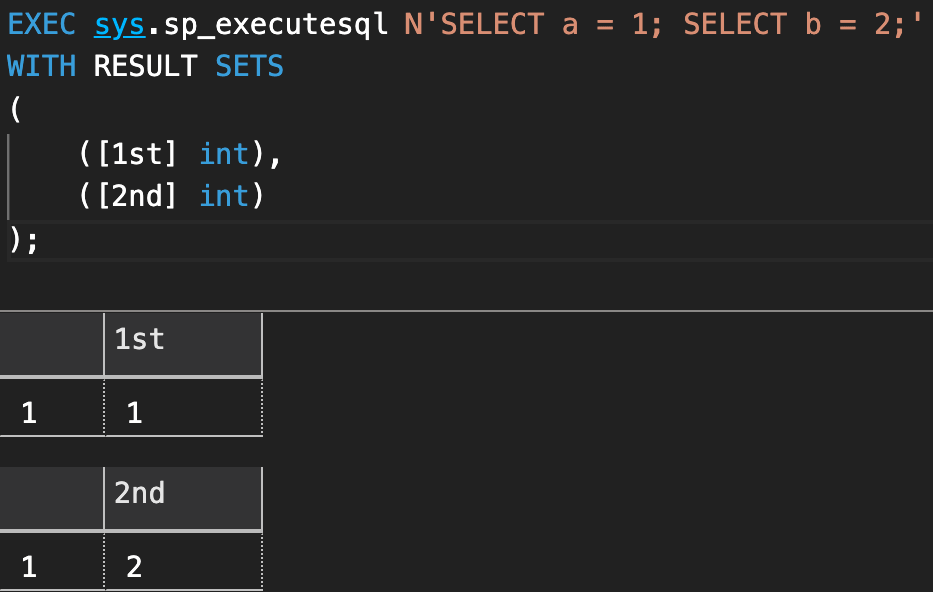
Shape of resultset is fixed
You can't use WITH RESULT SETS to add or remove columns from the output; you can only mess with the column names, data types, nullability, and collation.For example, if you try to eliminate columns from the result set as follows:
EXEC ('SELECT foo = 1, bar = 2;') WITH RESULT SETS ( (foo int) );
Results:
EXECUTE statement failed because its WITH RESULT SETS clause specified 1 column(s) for result set number 1, but the statement sent 2 column(s) at run time.
And if you try to convert to an incompatible data type, it will fail at runtime. For example, the following code will compile:
EXEC('SELECT foo = N''bar'';') WITH RESULT SETS ( (foo int) );
But if you run it:
Error converting data type varchar to int.
There are many other limitations and caveats to using these metadata enhancements; if you can see usefulness in some of these capabilities, I strongly recommend reviewing the official documentation and playing with the features for yourself.
dm_exec_describe_first_result_set is so pretty.
I can't wait!