
SQL Server 2012 introduces a feature that Oracle professionals will certainly recognize: SEQUENCE. SEQUENCE allows you to define a central place where SQL Server will maintain a counter of values for you. The last-used value is stored in memory and so no storage is required. Here is an example:
CREATE SEQUENCE dbo.OrderIDs AS INT MINVALUE 1 NO MAXVALUE START WITH 1; SET NOCOUNT ON; SELECT NextOrderID = NEXT VALUE FOR dbo.OrderIDs UNION ALL SELECT NEXT VALUE FOR dbo.OrderIDs UNION ALL SELECT NEXT VALUE FOR dbo.OrderIDs;
Results:
NextOrderID ----------- 1 2 3
Notice I did not have to create any tables or worry about persisting information to disk in any way. What about reseeding? This is a common problem with IDENTITY columns. You can "reseed" a sequence using ALTER and RESTART WITH:
ALTER SEQUENCE dbo.foo RESTART WITH 20; SET NOCOUNT ON; SELECT NextOrderID = NEXT VALUE FOR dbo.OrderIDs UNION ALL SELECT NEXT VALUE FOR dbo.OrderIDs UNION ALL SELECT NEXT VALUE FOR dbo.OrderIDs;
Results:
NextOrderID ----------- 20 21 22
And if you want to roll back the clock or re-use an existing sequence, you can use a lower number with RESTART WITH as well – though I'd be careful with this depending on how you are using the values. Want to increment by a value other than 1 (the default)? You can use INCREMENT BY:
ALTER SEQUENCE dbo.foo RESTART WITH 1 INCREMENT BY 5; SET NOCOUNT ON; SELECT NextOrderID = NEXT VALUE FOR dbo.OrderIDs UNION ALL SELECT NEXT VALUE FOR dbo.OrderIDs UNION ALL SELECT NEXT VALUE FOR dbo.OrderIDs;
Results:
NextOrderID ----------- 1 6 11
You can start a sequence at a value greater than 1 simply by changing the MINVALUE. You can also start at the low end of the data range, e.g. to use all 4 billion values for INT instead of just the 2 billion positive values. And you can even use INCREMENT BY to count down instead of up; just use a negative value.
You can also ensure that the sequence doesn't use all the possible values, for example if you wanted to have a maximum of 20 values in a TINYINT sequence, you could use the following code to produce a max of 20 values instead of all 255:
CREATE SEQUENCE dbo.foo AS TINYINT MINVALUE 1 MAXVALUE 20 START WITH 1;
When you create such a sequence, you will get the following warning message (note that it is not an error):
And if you actually try to go past the first 20 values:
SELECT NEXT VALUE FOR dbo.foo; GO 21
You will get this error message:
The sequence object 'foo' has reached its minimum or maximum value. Restart the sequence object to allow new values to be generated.
You can restart the sequence using ALTER SEQUENCE … RESTART WITH. If you want to use up all of the values and then loop around and start over, you can use the CYCLE option.
Surprisingly, if you simply overflow the datatype, you get the same sequence-related error message as opposed to the more familiar Msg 220 (arithmetic overflow) error:
SELECT NEXT VALUE FOR dbo.foo; GO 256
It is important to note that SEQUENCE will not provide you a transactionally consistent and gap-free stream of values. For example, just like IDENTITY, if your transaction rolls back, the next value is still taken:
CREATE SEQUENCE dbo.bar AS INT MINVALUE 1 NO MAXVALUE START WITH 1; GO BEGIN TRANSACTION; SELECT NextBar = NEXT VALUE FOR dbo.bar; ROLLBACK TRANSACTION; SELECT NextBar = NEXT VALUE FOR dbo.bar;
Results:
NextBar ----------- 1 NextBar ----------- 2
And if you want to check the current value of the sequence without actually using up a value (like checking IDENT_CURRENT() or DBCC CHECKIDENT), you can check the new catalog view, sys.sequences:
SELECT current_value FROM sys.sequences WHERE name = 'OrderIDs';
You can also check several other properties of the sequence this way (don't bother trying to use sp_help – all it will tell you is that it is a sequence object).
Want to get a range of SEQUENCE values? Don't use a loop; there's a stored procedure for that: sys.sp_sequence_get_range. Here is a sample:
DECLARE @fv SQL_VARIANT, @lv SQL_VARIANT; EXEC sys.sp_sequence_get_range @sequence_name = 'OrderIDs', @range_size = 20, @range_first_value = @fv OUTPUT, @range_last_value = @lv OUTPUT; SELECT fv = CONVERT(INT, @fv), lv = CONVERT(INT, @lv), next = NEXT VALUE FOR dbo.OrderIDs;
Results:
fv lv next ---- ---- ---- 5 24 25
But how does it perform?
I can see significant performance improvements over using a central identity table or a custom increment table (two typical ways this feature has been implemented). In the following example, I show five different ways to manage a central value generator. The first is a custom increment table, a popular method which uses a quirky update and is certainly far from standard. Next there are two methods using an IDENTITY column: one where the old rows are deleted before the next value is generated (for no other reason other than to save space), and the other that doesn't bother to do the delete, letting the table grow as new values are generated. Finally, we use the sequence, once with a procedure wrapper to simplify the changes to existing scripts, and once with the new NEXT VALUE syntax inserted into the code:
USE [master]; GO -- drop database and #temp table if they exist -- then create the database IF DB_ID(N'BookStore') > 0 BEGIN DROP DATABASE [BookStore]; END GO IF OBJECT_ID(N'tempdb..#timing') IS NOT NULL BEGIN DROP TABLE #timing; END GO CREATE DATABASE [BookStore]; GO USE [BookStore]; GO SET NOCOUNT ON; GO -- create a table with an IDENTITY column CREATE TABLE dbo.CentralIdentity ( ID BIGINT IDENTITY(1,1) PRIMARY KEY ); -- create a "roll your own" increment table -- and seed initial value CREATE TABLE dbo.CentralIncrement ( ID BIGINT PRIMARY KEY ); GO INSERT dbo.CentralIncrement(ID) SELECT 0; GO -- create a sequence with the same seed -- and increment properties CREATE SEQUENCE dbo.CentralSequence AS BIGINT MINVALUE 1 NO MAXVALUE START WITH 1; GO -- stored procedure for increment using quirky update CREATE PROCEDURE dbo.Central_CreateIncrement @NextID BIGINT OUTPUT AS BEGIN SET NOCOUNT ON; UPDATE dbo.CentralIncrement SET @NextID = ID = ID + 1; END GO -- stored procedure for increasing IDENTITY -- optionally deleting existing value(s) first CREATE PROCEDURE dbo.Central_CreateIdentity @NextID BIGINT OUTPUT, @Delete BIT = 0 AS BEGIN SET NOCOUNT ON; IF @Delete = 1 BEGIN DELETE dbo.CentralIdentity; END INSERT dbo.CentralIdentity DEFAULT VALUES; SELECT @NextID = SCOPE_IDENTITY(); END GO -- stored procedure for handling bumping the SEQUENCE CREATE PROCEDURE dbo.Central_CreateSequence @NextID bigint OUTPUT AS BEGIN SET NOCOUNT ON; SELECT @NextID = NEXT VALUE FOR dbo.CentralSequence; END GO -- simple table that will be the recipient of key values CREATE TABLE dbo.Orders ( OrderID int PRIMARY KEY ); GO -- simple table for tracking timings CREATE TABLE #timing ( Step varchar(64), dt datetime2(7) NOT NULL DEFAULT SYSUTCDATETIME() ); GO -- start each step with a blank orders table TRUNCATE TABLE dbo.Orders; GO INSERT #timing(Step) SELECT 'Starting increment'; GO DECLARE @NextID BIGINT; EXEC dbo.Central_CreateIncrement @NextID = @NextID OUTPUT; INSERT dbo.Orders(OrderID) SELECT @NextID; GO 100000 INSERT #timing(Step) SELECT 'Finished increment'; GO TRUNCATE TABLE dbo.Orders; GO INSERT #timing(Step) SELECT 'Starting identity + delete'; GO DECLARE @NextID BIGINT; EXEC dbo.Central_CreateIdentity @NextID = @NextID OUTPUT, @Delete = 1; INSERT dbo.Orders(OrderID) SELECT @NextID; GO 100000 INSERT #timing(Step) SELECT 'Finished identity + delete'; GO TRUNCATE TABLE dbo.Orders; GO INSERT #timing(Step) SELECT 'Starting identity without delete'; GO DECLARE @NextID BIGINT; EXEC dbo.Central_CreateIdentity @NextID = @NextID OUTPUT, @Delete = 1; INSERT dbo.Orders(OrderID) SELECT @NextID; GO 100000 INSERT #timing(Step) SELECT 'Finished identity without delete'; GO TRUNCATE TABLE dbo.Orders; GO INSERT #timing(Step) SELECT 'Starting sequence with PROC'; GO DECLARE @NextID BIGINT; EXEC dbo.Central_CreateSequence @NextID = @NextID OUTPUT; INSERT dbo.Orders(OrderID) SELECT @NextID; GO 100000 INSERT #timing(Step) SELECT 'Finished sequence with PROC'; GO -- this step handles the SEQUENCE directly TRUNCATE TABLE dbo.Orders; GO INSERT #timing(Step) SELECT 'Starting sequence without PROC'; GO INSERT dbo.Orders(OrderID) SELECT NEXT VALUE FOR dbo.CentralSequence; GO 100000 INSERT #timing(Step) SELECT 'Finished sequence without PROC'; GO -- ok, now we can run a query to measure timings ;WITH t AS ( SELECT Step, dt, rn = ROW_NUMBER() OVER (ORDER BY dt) FROM #timing ) SELECT t1.Step, dur_s = DATEDIFF(SECOND, t1.dt, t2.dt) FROM t AS t1 INNER JOIN t AS t2 ON t1.rn = t2.rn - 1 WHERE t1.rn % 2 = 1 AND t2.rn % 2 = 0; GO
The results, keeping in mind that this was in a VM on a laptop:
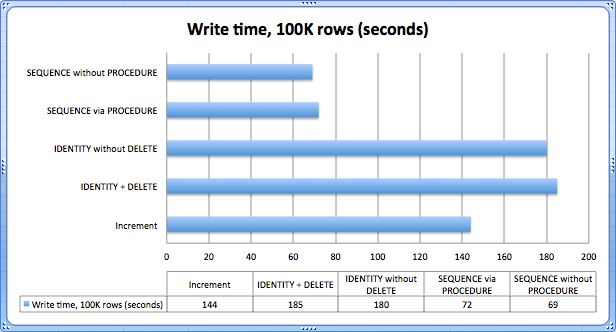
The clear winner is obviously the SEQUENCE operator, since it doesn't have to write the data to disk in order to persist the current value. Next I ran the same tests, but this time turned page compression on for the increment and identity tables, to see if the reduced I/O might let the existing solutions come a little closer:
CREATE TABLE dbo.CentralIdentity ( ID BIGINT IDENTITY(1,1) PRIMARY KEY ) WITH (DATA_COMPRESSION = PAGE); CREATE TABLE dbo.CentralIncrement ( ID BIGINT PRIMARY KEY ) WITH (DATA_COMPRESSION = PAGE);
The results were indistinguishable. In fact, from run to run, one method would gain a second, and another would lose two; on the next run, the first one would lose three seconds and another would gain one.
I also tried putting a NEXT VALUE FOR command in a user-defined function, to see if there was an easier way to inline the syntax, and see if the UDF overhead would impact the observed benefit. However if you try to create a function with a reference to a sequence object, here is the error you will get (which will also point out a few other places where you shouldn't bother trying to use them – it's a pretty long laundry list):
NEXT VALUE FOR function is not allowed in check constraints, default objects, computed columns, views, user-defined functions, user-defined aggregates, sub-queries, common table expressions, or derived tables.
Note also that you can use NEXT VALUE FOR in a UNION ALL, but not in a UNION, EXCEPT, INTERSECT, or with DISTINCT:
NEXT VALUE FOR function cannot be used directly in a statement that uses a DISTINCT, UNION (except UNION ALL), EXCEPT or INTERSECT operator.
If you look in sys.messages, you'll see there are several other limitations in the initial implementation of SEQUENCE. Some of these error messages are quite logical, but others are quite interesting. For example, it is okay to reference a sequence object in another database, but not when defined as a default constraint.
| Msg | Text |
| 11700 | The increment for sequence object '%.*ls' cannot be zero. |
| 11701 | The absolute value of the increment for sequence object '%.*ls' must be less than or equal to the difference between the minimum and maximum value of the sequence object. |
| 11702 | The sequence object '%.*ls' must be of data type int, bigint, smallint, tinyint, or decimal or numeric with a scale of 0, or any user-defined data type that is based on one of the above integer data types. |
| 11703 | The start value for style="border: 1px solid black;"sequence object '%.*ls' must be between the minimum and maximum value of the sequence object. |
| 11704 | The current value '%.*ls' for sequence object '%.*ls' must be between the minimum and maximum value of the sequence object. |
| 11705 | The minimum value for sequence object '%.*ls' must be less than its maximum value. |
| 11706 | The cache size for sequence object '%.*ls' must be greater than 0. |
| 11707 | The cache size for sequence object '%.*ls' has been set to NO CACHE. |
| 11709 | The 'RESTART WITH' argument cannot be used in a CREATE SEQUENCE statement. |
| 11710 | Argument 'START WITH' cannot be used in an ALTER SEQUENCE statement. |
| 11711 | Argument 'AS' cannot be used in an ALTER SEQUENCE statement. |
| 11714 | Invalid sequence name '%.*ls'. |
| 11715 | No properties specified for ALTER SEQUENCE. |
| 11716 | NEXT VALUE FOR function does not support the PARTITION BY clause. |
| 11717 | NEXT VALUE FOR function does not support the OVER clause in default constraints, UPDATE statements, or MERGE statements. |
| 11718 | NEXT VALUE FOR function does not support an empty OVER clause. |
| 11719 | NEXT VALUE FOR function is not allowed in check constraints, default objects, computed columns, views, user-defined functions, user-defined aggregates, sub-queries, common table expressions, or derived tables. |
| 11720 | NEXT VALUE FOR function is not allowed in the TOP, OVER, OUTPUT, ON, WHERE, GROUP BY, HAVING, ORDER BY, COMPUTE, or COMPUTE BY clauses. |
| 11721 | NEXT VALUE FOR function cannot be used directly in a statement that uses a DISTINCT, UNION (except UNION ALL), EXCEPT or INTERSECT operator. |
| 11722 | NEXT VALUE FOR function is not allowed in the WHEN MATCHED clause, the WHEN NOT MATCHED clause, or the WHEN NOT MATCHED BY SOURCE clause of a merge statement. |
| 11723 | NEXT VALUE FOR function cannot be used directly in a statement that contains an ORDER BY clause unless the OVER clause is specified. |
| 11724 | An expression that contains a NEXT VALUE FOR function cannot be passed as an argument to a table-valued function. |
| 11725 | An expression that contains a NEXT VALUE FOR function cannot be passed as an argument to an aggregate. |
| 11726 | Object '%.*ls' is not a sequence object. |
| 11727 | NEXT VALUE FOR functions for a given sequence object must have exactly the same OVER clause definition. |
| 11728 | The sequence object '%.*ls' has reached its minimum or maximum value. Restart the sequence object to allow new values to be generated. |
| 11729 | The sequence object '%.*ls' cache size is greater than the number of available values; the cache size has been automatically set to accommodate the remaining sequence values. |
| 11730 | Database name cannot be specified for the sequence object in default constraints. |
| 11731 | A column that uses a sequence object in the default constraint must be present in the target columns list, if the same sequence object appears in either a row constructor or under UNION ALL. |
| 11732 | The requested range for sequence object '%.*ls' exceeds the maximum or minimum limit. Retry with a smaller range. |
I hope that gives a good taste of SEQUENCE. As you start contemplating the move to the next version of SQL Server, you may want to consider this feature if you are currently using a central identity or increment table – as long as you can get along with its limitations. If you want more official information on SEQUENCE, including a great description on how memory is used to cache sequence values and avoid I/O, you can start at this Books Online topic, Sequence Numbers.
I have tried to assess performance with a table, a bit different than yours:
CREATE TABLE [dbo].[cms_tblTest](
[ID] [bigint] NOT NULL,
[TEXT] [nvarchar](250) NULL,
CONSTRAINT [PK_cms_tblTest] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
/****** Object: Sequence [dbo].[cms_sqTest] Script Date: 06.01.2014 8:52:04 ******/
CREATE SEQUENCE [dbo].[cms_sqTest]
AS [bigint]
START WITH 0
INCREMENT BY 1
MINVALUE 0
MAXVALUE 9223372036854775807
CACHE 20
GO
against identity table:
CREATE TABLE [dbo].[cms_tblTestClassic](
[ID] [bigint] IDENTITY(1,1) NOT NULL,
[TEXT] [nvarchar](250) NULL,
CONSTRAINT [PK_cms_tblTestClassic] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
testing scripts:
for seq table:
declare
@pI int =0,
@pId bigint,
@pText nvarchar(250),
@pDate datetime = getdate()
while @pI<100000
begin
select @pId = next value for dbo.cms_sqTest
set @pText = 'Text'+convert(nvarchar(100),@pI)
insert into cms_tblTest
([ID],[TEXT])
values
(@pId,@pText)
set @pI =@pI+1
end
select convert(time,getdate()-@pDate)
for identity table:
declare
@pI int =0,
@pText nvarchar(250),
@pDate datetime = getdate()
while @pI<100000
begin
set @pText = 'Text'+convert(nvarchar(100),@pI)
insert into cms_tblTestClassic
([TEXT])
values
(@pText)
set @pI =@pI+1
end
select convert(time,getdate()-@pDate)
and results are:
Identity table: 00:00:24.7830000
seq table:00:00:25.1330000
If you simplify how you use it, you'll find the SEQUENCE object is significantly faster. John talks about it here:
http://www.sqlnotes.info/2011/11/18/sql-server-sequence-internal/
Have you tried setting a default of the id column with "next value for XX"?
@Mark Freeman – "I would be curious as to the performance or other advantages to SEQUENCE vs. IDENTITY when used for the same purpose as IDENTITY. In other words, why would someone want to switch an IDENTITY column to one populated using a SEQUENCE"
In the use case you describe, IDENTITY does appear to outperform sequence…at least in my test cases (http://byobi.com/blog/2012/09/sequence-vs-identity-performance-comparison/)…so the flexibility provided by a sequence object comes at a (slight) performance cost.
Speedbird186 yes, this is true, some of the syntax that was allowed in previous betas was cut between RC0 and RTM. You can see the final list of restrictions in the updated BOL docs.
http://msdn.microsoft.com/en-us/library/ff878370.aspx
It seems like SQL Server 2012 RTM no longer supports UNION or UNION ALL with the NEXT VALUE FOR function:
Msg 11721, Level 15, State 1, Line 3
NEXT VALUE FOR function cannot be used directly in a statement that uses a DISTINCT, UNION, UNION ALL, EXCEPT or INTERSECT operator.
Very Nice writeup for SEQUENCE
Thanks for the great post. Does someone know when SQL Azure Database will support sequences?
Thanks Richard, it's a good point. I wanted to keep the initial performance analysis simple, especially since this was a very early beta. I do have a more thorough blog post planned for RTM or something much closer to it.
Another benefit of sequences vs. the incrementing method is that the incrementing methods causes transactions to become serialized. If you're doing any kind of batch update, the sequence table is going to be locked until that batch finishes and everything else waits. Sequences don't affect transactions in this manner. Your performanced analysis doesn't show the benefits when there are multiple simultaneous transactions occurring. In this case the performance difference is huge.
how to implement, managing sequences and performance which is better identity or sequences please use the below link
http://sqljunkieshare.com/2011/12/11/sequences-in-sql-server-2012-implementingmanaging-performance/
I would be curious as to the performance or other advantages to SEQUENCE vs. IDENTITY when used for the same purpose as IDENTITY. In other words, why would someone want to switch an IDENTITY column to one populated using a SEQUENCE (including the default constraint that I assume would be needed)?
Gints, I'm not sure why you are opening a cursor to insert rows into another table one by one, but I suspect that the difference between a sequence and identity is not going to magically make this fast.
If there isn't any possibility to get sequence value for each inserted row in an insert statement, which inserts many rows in one go then there isn't much sense, but if it is possible then I would like to know is there any difference between these two (and I mean just execution time):
INSERT INTO tableX SELECT seq.nextval, tableYcolumns FROM tableY
vs
INSERT INTO tableX SELECT tableYcolumns FROM tableY (and identity column is populated automatically).
Because when testing using a procedure, which for example opens cursor to select rows from tableY and then inserts row by row into tableX it takes too much time to process cursor and loop and sequence weakness or strength is lost into this row by row (or rather we can say slow by slow 🙂 approach.
Gints, for the first comment, there is no NEXT n VALUES FOR. It would be nice if there was a better construct to grab multiple rows from a sequence. I'll play with some experiments though and perhaps post another entry because I think there are some workarounds.
As for your second comment, not sure what you mean. Do you mean measure the time it takes to write code that uses sequence compared to a plain set-based SQL statement? What plain set-based SQL statement? Or do you mean the time it takes to wrap "CREATE PROCEDURE" around your SQL statement? I did measure timings above, comparing sequence to other methods (identity, homemade increment). You need to be more descriptive.
I'd also like to know is there any possibility whether we can use SQL Server sequences for multiple rows e.g. INSERT INTO aTable SELECT colmns, including sequence FROM anotherTable
And if possible could you measure timings here? Because when using procedures tooo much time is wasted for running t-sql instead of just plain set based SQL statement.
Aaron,
This will be nice to use especially since I have worked in Oracle and used this function regularly. Always wished SQL Server had it.
Thanks for the information.
Cheers!
Yep nice explanation and thanks for sharing!
Thanks for this great writeup! I was exploring Denali on the plane and came across SEQUENCE but didn't have books online installed so this new keyword's usage remained a mystery for me until now.
PostgreSQL has the same feature. Has had it since the beginning of time.
You can create it as part of the definition of a table using serial.
CREATE TABLE sometable(someid serial PRIMARY KEY etc.);
and it increments much like the SQL Server identity does.
But what is cool is you can also create it apart from the table and use it as an incrementor of multiple tables or manually increment it.
the serial is really a fictitious type for convenience that behinds the scenes creates a sequence object and sets the default value of the column to the next value of the sequence
CREATE SEQUENCE sometable_someid_seq
INCREMENT 1
MINVALUE 1
MAXVALUE 9223372036854775807
START 1
CACHE 1;
then you can use nextval, curval etc functions to push it forward etc or use nextval as a default for a table
Jack, what do you mean? Like you want it to replace a numbers table?
The one question I have, is there a way to use SEQUENCE in a set-based manner?