
A very common request over the past, oh, 10 years, maybe more, has been better support for paging within T-SQL (this Connect request dates back to 2005). Well, you will see some broader support for this within a year, give or take: the next version of SQL Server will offer OFFSET / FETCH syntax. Tobias Ternstrom spilled the beans during yesterday's keynote at SQL Connections, so there's not much to stop anyone from starting to publish code samples I thought I would just show a quick example using AdventureWorks2008R2, demonstrating both the shorter syntax as well as a slightly more efficient plan.
Here is the way we might handle paging today… several variations exist, but hopefully we can agree that typically the approach is similarly ugly and verbose:
DECLARE @PageSize tinyint = 20, @CurrentPage int = 1500; WITH o AS ( SELECT TOP (@CurrentPage * @PageSize) [RowNumber] = ROW_NUMBER() OVER (ORDER BY SalesOrderID), SalesOrderID /* , ... */ FROM Sales.SalesOrderHeader ) SELECT SalesOrderID /* , ... */ FROM o WHERE [RowNumber] BETWEEN ((@CurrentPage - 1) * @PageSize + 1) AND (((@CurrentPage - 1) * @PageSize) + @PageSize) ORDER BY [RowNumber];
Now with the new syntax, coming soon to a virtual machine near you, a lot of this messiness and redundancy goes away:
DECLARE @PageSize tinyint = 20, @CurrentPage int = 1500; SELECT SalesOrderID /* , ... */ FROM Sales.SalesOrderHeader ORDER BY SalesOrderID OFFSET (@PageSize * (@CurrentPage - 1)) ROWS FETCH NEXT @PageSize ROWS ONLY;
Isn't that nicer? I thought so. (Though do check out this subsequent post for an even better approach.)
But wait, what about the plans?
In Management Studio, running the actual execution plan yields very little difference. There is an additional filter (the WHERE clause) and a SEQUENCE project (the ROW_NUMBER()), but otherwise these plans seem pretty equivalent:
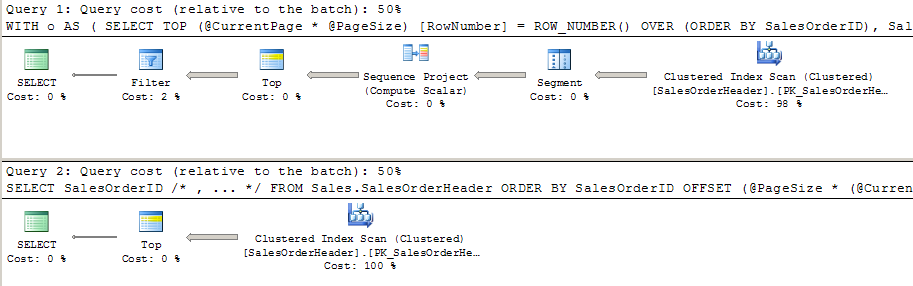
In order to visualize some other facts about these plans, I save the plan XML to disk, and then load it up in Plan Explorer. The first thing I notice right off the bat is that tomayto <> tomatto: In SSMS, the cost % of each plan as a percentage of the batch was rounded off to 50%, but the old way of doing things is (not surprisingly) a wee bit less efficient:

Is it a huge difference? Absolutely not. And when we look at the graphical plans in the default mode in Plan Explorer, we see pretty much the same thing we see in Management Studio.
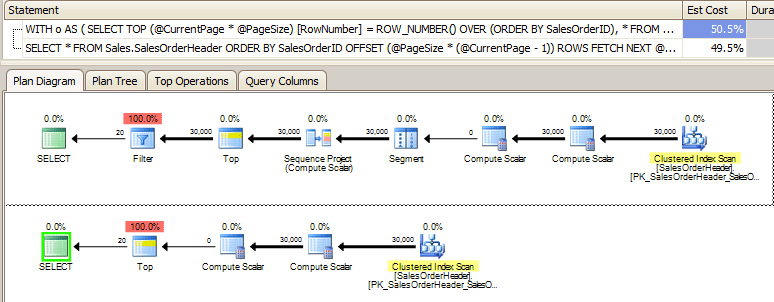
However, when we right-click the plan and change Data Widths By to Data Size (MB), something else becomes a little more apparent… nearly 10 MB of data gets passed between multiple operators using the old plan, whereas this transfer only seems to occur once in the new plan:
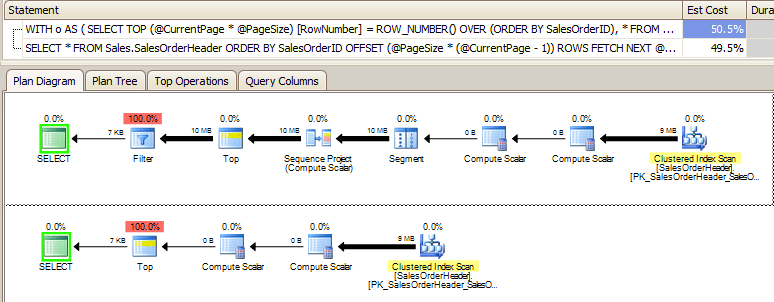
The fact that the "size" of the clustered index scan is passed between many more operators in the old version of the query makes me a little skeptical that it is doing more work than it needs to be, and this could be contributing to the overall cost difference (though I will confess that the I/O costs were actually slightly higher for the new version of the plan).
But by and large, it seems like the work done by the engine under the covers is relatively the same, with only a few minor differences. These differences are unlikely to cause any noticeable change in your existing applications, but keep in mind that this was an overly simplistic test, and that you should always try out alternatives on your own systems, with your own hardware, your own data, and your own load and concurrency. I plan to do some more testing of this feature against some horrific paging scenarios I've had to support in the past.
Now, it wouldn't be a new feature without…
Caveats
There are a couple of notes on the syntax that may be of interest:
- In order to support parameterized ordering, you will still have to use dynamic SQL or complex CASE expressions in the ORDER BY clause. Tobias said that it may be extended in future versions, but the bare minimum is all that made the cut for Denali. I'll try to adapt some old examples to the new syntax – while it will still represent less optimal methods, the code should still end up looking less sloppy.
- In order to use OFFSET, you *must* include an ORDER BY clause. If you try something like this (which essentially says we don't care about the order)…
SELECT * FROM sys.objects OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY;
…you will get the following error messages:
Msg 102, Level 15, State 1
Incorrect syntax near '0'.
Msg 153, Level 15, State 2
Invalid usage of the option NEXT in the FETCH statement.In my opinion, this is the way it should be, and it has always bothered me that you could use TOP in various "dirty" ways – without an ORDER BY clause, or simply to fool SQL Server into allowing an inconsequential ORDER BY clause into a view.
In fact, OFFSET and FETCH NEXT FOR are documented in Books Online under the ORDER BY topic.
Conclusion
Some may consider this a small victory, if a victory at all, but I suspect there is a large faction of people out there who are rejoicing in the introduction of a cohesive way to implement paging. It is probably not as flexible as some of you might have expected, but for a very first try I think we'll take what we can get.
@Jack A, how do you propose SQL Server apply a row_number to the entire table without performing a clustered index scan? What index do you propose to try to circumvent this?
Have you looked into the effect of using indexes?
Both of your query plans are starting with a table scan. My experience so far with ROW_NUMBER() OVER is that an index on the ordering column will yield a much more efficient plan, with an index seek on the ordering column instead of the scan.
I would expect the new syntax to behave the same with respect to index usage, but it's something that's definitely worth verifying.
Great features.. just remember 70's SQL is NOT the solution to all your problems.
I have no option but to throw hardware at SQL scalability issues..
sigh
Hi Aaron,
It was very interesting post, thanks indeed!
I tried similar query and by getting help from Plan Explorer, noticed the data size transfer between operators. But interestingly the duration for first query was less than second one! I'm wondered why the second query is slower while it seems to work less with whole of data?
Thank you again 🙂
———–
use [AdventureWorks]
go
set statistics time on
go
;with tmp
as
(select ROW_NUMBER() over(order by salesorderid) as r ,* from sales.SalesOrderDetail)
select * from tmp where r>121307
order by salesorderid
go
select * from sales.SalesOrderDetail
order by salesorderid offset 121307 rows fetch next 10 rows only
Ahh, I thought it was part of the SQL2000 ANSI standard at one point. Good to know.
Cheers
Actually Adam, Microsoft is adhering to the SQL standard; far from reinventing the wheel. I prefer sticking to the standard rather than following MySQL's proprietary syntax. Violating the standard does little for anyone except those who have a lot of MySQL experience and have a hard tome re-learning.
Please see the following article for some details… note there is no MySQLish syntax denoted in the standard.
http://troels.arvin.dk/db/rdbms/#select-limit-offset
Paul,
I wasn't saying that. I was just wondering why MS would use such a verbose syntax when there is already syntax out there which does the job and is much simpler. MS trying to reinvent the wheel again.
Adam
Adam,
If that were the only consideration in choosing between MySQL and SQL Server, no doubt the former would be considerably more successful than it is ;c)
Paul
I think MySQL and the LIMIT syntax is the best for this. This seems pretty verbose for what it is trying to achieve.
Likewise i cant say that im blown away and suspect that this could cause more issues than it solves. It is simple to use but having to scan to the N'th page of data may not always be the most optimal.
Here's my take on it using Paul's scripts for comparison
http://sqlblogcasts.com/blogs/sqlandthelike/archive/2010/11/10/denali-paging-is-it-win-win.aspx
This really good post. Thank you Aaron.
As the result of new syntax we will get simplified SQL, but similar by "cost" execution plans.
But, did you try to gather these statistics for both queries:
SET STATISTICS IO ON
SET STATISTICS TIME ON
I guess, output of them could provide little bit sharper comparison of plan cost
It's a convenience perhaps, but much like PIVOT I fear people may be ultimately disappointed with the performance. I discussed some of the issues at http://www.sqlservercentral.com/articles/paging/69892/
Nevertheless, it will be interesting to see if the Denali query optimizer is able to produce transform queries into plans which feature this 'Offset Expression' Top.