
Earlier today, MSSQLTips posted a backup compression tip by Thomas LaRock. In that article, Tom states: "If you are already compressing data then you will not see much benefit from backup compression." I don't want to argue with a rock star, and I will concede that he may be right in some scenarios. Nonetheless, I tweeted that "it depends;" Thomas then asked for "an example where you have data comp and you also see a large benefit from backup comp?" My initial reaction came about for two reasons:
- I know that the benefit you get from data compression depends heavily on data skew and how many repeated patterns you can find on a single page, whereas backup compression is not limited to finding compressible data only within the same page; and,
- I see no reason why anyone should NOT use backup compression, if they have the capability available to them (in SQL Server 2008, Enterprise Edition only; in SQL Server 2008 R2, Standard Edition and higher), unless they are already extremely CPU-bound (typically these days we are predominately I/O-bound).
I've performed several tests of data compression and the additional CPU required was more than worth the savings in I/O (and ultimately duration), so I would expect the same type of benefit here. But I need to put my money where my mouth is… so here is an example that shows two different scenarios where data compression is used, and a variance in the benefit that data compression and then using backup compression gains you. I created 6 databases, all prefixed with ct (which stands for "compression test"):
CREATE DATABASE ct_none_ordered; CREATE DATABASE ct_row_ordered; CREATE DATABASE ct_page_ordered; CREATE DATABASE ct_none_not_ordered; CREATE DATABASE ct_row_not_ordered; CREATE DATABASE ct_page_not_ordered;
In each database I created a table with an IDENTITY column and a single varchar(36) column. In each case, I used a different compression setting to match the database. In the databases with the _ordered suffix, I created a clustered index on the varchar column:
CREATE TABLE dbo.a ( i int IDENTITY(1,1) PRIMARY KEY NONCLUSTERED, a varchar(36) ) WITH (DATA_COMPRESSION = NONE|ROW|PAGE); GO CREATE CLUSTERED INDEX a ON dbo.a(a) WITH (DATA_COMPRESSION = NONE|ROW|PAGE); GO
And in the the databases with the _not_ordered suffix, I made the primary key on the IDENTITY column clustered (and for as much symmetry as possible, created a non-clustered index on the GUID column):
CREATE TABLE dbo.a ( i int IDENTITY(1,1) PRIMARY KEY CLUSTERED, a varchar(36) ) WITH (DATA_COMPRESSION = NONE|ROW|PAGE); GO CREATE INDEX a ON dbo.a(a) WITH (DATA_COMPRESSION = NONE|ROW|PAGE); GO
Then I created two tables in tempdb to store a seed list of strings – one with relatively ordered values, and one in random order. The quickest way I could think of to do this would be to use NEWSEQUENTIALID() and NEWID(). Now, this isn't exactly scientific because NEWSEQUENTIALID() doesn't increment by the leading character, but there are enough repeating sequences on a page that I predicted it would accomplish the results I was after (and if it didn't, I could come up with something else). I populated each table with 100,000 rows. My plan was to then load 10,000,000 rows into each of the above 6 tables, compare the space used on disk, and then compare the backup sizes and durations.
USE tempdb; SET NOCOUNT ON; GO CREATE TABLE dbo.[seq] ( i uniqueidentifier NOT NULL DEFAULT NEWSEQUENTIALID() ); GO INSERT dbo.[seq] DEFAULT VALUES; GO 100000 CREATE TABLE dbo.[rand] ( i uniqueidentifier NOT NULL DEFAULT NEWID() ); GO INSERT dbo.[rand] DEFAULT VALUES; GO 100000
Now that I had my seed values, I could start populating my real tables. I had a loop like this for each _ordered table:
INSERT dbo.a(a) SELECT a = RTRIM(i) FROM tempdb.dbo.[seq] ORDER BY a; GO 100
And then a loop like this for each _not_ordered table:
INSERT dbo.a(a) SELECT a = RTRIM(i) FROM tempdb.dbo.[rand] ORDER BY NEWID(); GO 100
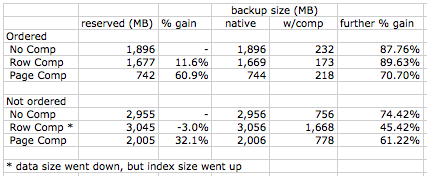
Was this experiment going to be fast? Heck no! It ended up taking about an hour and a half to populate the data (60,000,000 rows), and around 12 minutes to perform 12 backups. Here are the results for backup sizes:
And here are the results for backup times:
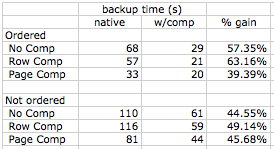
As I expected, the ordered data did not compress well using only row compression, but it did compress very well when using page compression (over 60%). And even at the best data compression rate, we see backup compression rates over 70%, and 40% less time is required to perform those backups. In fact I was unable to come up with a counter-example – where backup compression did NOT improve things, or even where they remained the same. I saw benefits to using backup compression in every single case I tested, and the savings are substantial in even the worst case (45% space savings).
I will concede, though, that all of these tests were performed on a relatively idle server with no CPU or memory pressure. So there are certainly cases I can envision where the advantages gained by the improved I/O when using backup compression can be outweighed by the additional cost to CPU. But as I mentioned before, most of the systems I come across are I/O bound, and can afford to trade some CPU for better I/O.
Worth repeating, the Compression Backup option is not available with SQL 2008 Standard or Express version. Boo. I think this fairly obvious option should be available to any MS SQL paying customer. For my SQL Standard clients I had to write scripts to ZIP up the BAK files.
Aaron, I did this test myself and while you don't really gain in size you will gain in restore and backup time
See here: http://blogs.lessthandot.com/index.php/DataMgmt/DBAdmin/MSSQLServerAdmin/do-you-get-a-benefit-from-compressing-ba
I will repeat the test with a real database at work in a week or so
Hi Aaron… thanks for the great post. Have you done any comparitive tests on Databases with Data Compression with TDE enabled and the effect on Backup Compression vs a Native Backup of such a database? Thanks in advance.
yes, Aaron, my wording was poor in the tip.
Yes, there are some additional algorithms used by backup compression (I am not sure of all the details). And in spite of what Books Online currently says, I am fairly certain I recall Kevin Farlee explaining that backup compression can look at compressing values across the entire database as opposed to on a single page.
I think more tests are in order to determine exactly what criteria lead to getting favorable results, but clearly there is a benefit to compressing already compressed data that Tom, Paul Randal, and even PSS have overlooked (they all state that you won't get much benefit from compressing compressed data):
http://technet.microsoft.com/en-us/magazine/2009.02.sqlqa.aspx?pr=blog
http://blogs.msdn.com/psssql/archive/2008/03/24/how-it-works-sql-server-2008-backup-compression-database-compression-and-total-data-encryption.aspx
For now, I would just suggest that "it depends" – in your environment, you will need to test whether applying backup compression helps, and don't forget to do this during heavy load so you can monitor CPU deltas as well as impact on other workloads (information I did not include above). My point remains: you *can* achieve benefits from dual compression.
The reason for the successful dual compression, is that page and row compression has "prefix" algorithm, and backup compression has "suffix" algorithm?
Tom
I had a client with 1 TB database who implemented PAGE Compression on all NCI indexes (in fact there were the only NCI on that database) and he used BACKUP Compression as well. I do not remember what the exact numbers were but we have seen certainly performance improvment for the queries as well as 1TB database was comressed to 458GB ….
Thanks for the test results Aaron. This is exactly what I was told by the Storage Engine team at MS when I was writing my latest book (which I guess Tom hasn't read). I didn't have any tests of my own (or scripts that I could just run) that showed the results so clearly. I just had some numbers given to me by MS. So thanks again!
~Kalen
Tom, the 14 MB difference you cite is showing the impact of data compression vs. not compressing the data, as opposed to backup compression vs. not compressing the backup. Compare the values in the row, not the column.
In your post you said (and I'm paraphrasing), "if you are already doing data compression, then you won't get much from backup compression." My rebuttal was intended to (among other things) compare a page compressed database that is backed up natively vs. the same page compressed database that is backed up compressed. As the graphic shows, this particular database that was page compressed was backed up natively at 744MB, but when WITH COMPRESSION was added, it compressed over 70% further to 218 MB. I think this shows that you *can* achieve significant (not 14 MB) differences when you choose to use backup compression on the same compressed data. Can you provide an example where a backup of compressed data does *not* yield significantly better compression in the eventual backup size (either in terms of speed or size)?
In test backups on a 40GB datawarehouse we saw a significant reduction in size of a compressed backup of a page compressed database vs compressed backups of the same data not compressed.
raw data, raw backup 41.51 GB
raw data, compressed backup 7.24 GB
compressed data, raw backup 11.07 GB
compressed data, compressed backup 4.79 GB
This was done over several similarly sized test datamart databases for similar outcomes
Aaron,
I see the confusion now. I see above that you have a 232Mb compressed backup for a db with no data compression, versus a 218Mb compressed backup for a database with page compression.
That's the difference I was trying to talk about. Yes, there is a difference in size and times above, and if we were to extrapolate I suppose we could find the difference to be an order of magnitude greater.
I wasn't trying to say that it wasn't useful to have both, just that the end result (in your example a 14Mb difference) may not be as much as some would expect.
Thanks for supplying the examples above.
I have not seen any cases in real life yet where backup compression was not a big win, both in elapsed time and I/O. Stacking data compression with backup compression is still a big win, especially since most databases don't have data compression for every table and index. Good post.