
When SQL Server 2008 R2 was first released, I wrote a quick blog post discussing the additional space savings gained by Unicode compression. In one of the follow-up comments, Adam Machanic was quick to suggest that compression can bring significant CPU overhead, and can as much as double the amount of time it takes to retrieve data. He was absolutely right that I was extolling the space savings of the feature, but pretending that there was either no cost or that the cost was worth it.
My gut feeling is that, while additional CPU overhead is almost guaranteed, the overall duration should go down in many cases, because most systems are I/O-bound; thus, the extra CPU cost is more than compensated for by the savings in I/O. The algorithm is also smart about not compressing the data at all if it does not consider that enough space will be gained by doing so, so in cases where the space savings would not be significant, no extra CPU cost is incurred because no compression/decompression needs to occur when reading or writing to those pages (and there are neat little tricks that help the engine determine which pages are compressed, and which are not).
But why rely on a gut feeling? I wanted to put this to the test.
Methodology
Pretty simple, actually. Create tables with compression = page / row / none, fill up one or more nvarchar columns with random Unicode data, and measure read/write operations as well as storage requirements. Compare page / row / none within R2 (where Unicode compression can take place), within 2008 SP1 (where it cannot), and ultimately against each other. Hopefully, this will help show whether there are cases where the benefits of Unicode compression outweigh the costs.
Comparison Matrix
Again, pretty simple. We have two versions of SQL Server, three different types of table structures, and three different compression methods, for a total of 18 tests:
Version |
Table / Column Layout |
Compression |
||
None |
Page |
Row |
||
|---|---|---|---|---|
(10.00.2723.0, x64) |
• |
• |
• |
|
(10.50.1092.0, x64) |
• |
• |
• |
|
• |
• |
• |
||
• |
• |
• |
||
• |
• |
• |
||
• |
• |
• |
||
Full disclosure: these are two named instances on the same hardware, running in a virtual machine, with 4 virtual processors and 8 GB of RAM. The operating system is Windows Server 2008 R2 x64 RTM, the underlying disks are SATA, the host operating system is Mac OS 10.5.6, and the VM was built using VMWare Fusion 2.0.
Measurements
- Performance metrics : from a trace, I will measure Duration, Reads, Writes, and CPU.
- Storage metrics : sys.dm_db_partition_stats will show how much space is occupied by each version of the table.
Data
I borrowed some random characters from Alan Wood's page, Samples of Unicode character ranges. The initial string I used to generate random data, literally across many different languages and characters sets, is as follows:
DECLARE @f nvarchar(2048) = N'üäāšßåøæ¥Ñ龥ñЉЩщӃ※℀℃№™③㒅㝬㿜abcdefg1234567890';
Database and Login
In order to make trace filtering easy, I am going to create a dedicated database and login for these tests. Since I am not very creative, I am going to call both UnicodeTesting. Connecting as sa, I repeat this script on both the 2008 and 2008 R2 instances:
USE [master]; GO IF DB_ID(N'UnicodeTesting') IS NOT NULL BEGIN ALTER DATABASE UnicodeTesting SET SINGLE_USER WITH ROLLBACK IMMEDIATE; DROP DATABASE UnicodeTesting; END GO CREATE DATABASE UnicodeTesting; GO IF USER_ID(N'UnicodeTesting') IS NOT NULL DROP LOGIN UnicodeTesting; GO CREATE LOGIN UnicodeTesting WITH PASSWORD = N'UnicodeTesting', DEFAULT_DATABASE = [UnicodeTesting], CHECK_EXPIRATION = OFF, CHECK_POLICY = OFF; GO ALTER AUTHORIZATION ON DATABASE::UnicodeTesting TO UnicodeTesting; GO USE UnicodeTesting; GO CREATE TABLE dbo.indexstats ( description varchar(20), index_id int, in_row_data_page_count bigint, used_page_count bigint, reserved_page_count bigint, row_count bigint ); GO
The Tests
In the first test, I will create a single-column heap. I am going to be tracing this activity (using SQL:BatchCompleted), so adding the type of compression in use at the beginning of each batch will allow me to easily group and aggregate based on each type of compression.
-- heap, data compression = none DECLARE @f nvarchar(2048) = N'üäāšßåøæ¥Ñ龥ñЉЩщӃ※℀℃№™③㒅㝬㿜abcdefg1234567890', @s nvarchar(2048) = N''; IF OBJECT_ID(N'dbo.foo', 'U') IS NOT NULL DROP TABLE dbo.foo; CREATE TABLE dbo.foo ( i int IDENTITY(1,1), bar nvarchar(2048) ) WITH (DATA_COMPRESSION = NONE); SET NOCOUNT ON; DECLARE @i int, @j int = 0; DECLARE @foo TABLE (bar nvarchar(2048)); WHILE @j < 20000 BEGIN SELECT @i = 0, @s = N''; WHILE @i <= (2048 - (RAND()*250)) BEGIN SELECT @s += SUBSTRING(@f, CONVERT(int, (RAND()) * LEN(@f)), 1), @i += 1; END -- TABLOCK required for compression on heap INSERT dbo.foo WITH (TABLOCK) (bar) SELECT @s; SET @j += 1; END GO 10 -- heap, data compression = none SELECT TOP (1) bar FROM dbo.foo ORDER BY NEWID(); GO 10 -- heap, data compression = none SELECT TOP (1) bar FROM dbo.foo WHERE bar LIKE '2%' ORDER BY NEWID(); GO 10 -- heap, data compression = none SELECT TOP (1) bar FROM dbo.foo ORDER BY bar; GO 10 -- heap, data compression = none UPDATE dbo.foo SET bar = REPLACE(bar, '12', '※') WHERE bar LIKE '%12%'; UPDATE dbo.foo SET bar = REPLACE(bar, '21', '※') WHERE bar LIKE '%21%'; UPDATE dbo.foo SET bar = REPLACE(bar, '34', '※') WHERE bar LIKE '%34%'; UPDATE dbo.foo SET bar = REPLACE(bar, '43', '※') WHERE bar LIKE '%43%'; UPDATE dbo.foo SET bar = REPLACE(bar, '14', '※') WHERE bar LIKE '%14%'; GO 2 -- heap, data compression = none UPDATE dbo.foo SET bar = bar + N'x' WHERE bar LIKE 'a%'; UPDATE dbo.foo SET bar = bar + N'x' WHERE bar LIKE 'b%'; UPDATE dbo.foo SET bar = bar + N'x' WHERE bar LIKE 'c%'; UPDATE dbo.foo SET bar = bar + N'x' WHERE bar LIKE 'd%'; UPDATE dbo.foo SET bar = bar + N'x' WHERE bar LIKE 'e%'; GO 2 -- heap, data compression = none INSERT dbo.indexstats SELECT 'heap + none', index_id, in_row_data_page_count, used_page_count, reserved_page_count, row_count FROM sys.dm_db_partition_stats WHERE [object_id] = OBJECT_ID('dbo.foo'); GO
I repeat this above script for DATA_COMPRESSION of both PAGE and ROW. Now, this data is neither sequential nor is it indexed, so because the data is scattered all over the place, I would not expect page compression to help out a lot (since it depends on dictionary and column prefix compression, which look for similar patterns on the same page); likewise, because the lengths of all of the values are between 1,950 and 2,048 characters, we're not going to get anything out of row compression, either. Performance should not be great because of the additional TABLOCK hint that is required in order to utilize page compression on a heap. As it turned out, the nature of the data and how it filled the pages made it so that on a heap, page and row compression yielded exactly zero benefit in terms of storage space (and since the engine decided not to actually compress any of the pages, Unicode compression did not kick in either). In any case, I wanted to use data that was large enough to show statistical discrepancies in the overhead of reading/writing data, and the only way to ensure that Unicode compression could be used is to enable page compression, even though in this case it turned out to be a flop and a major resource drain in rounding out this post. Though I will treat this as a special case and cover at least the storage savings that can be achieved with Unicode compression, even on a heap, towards the end of this post.
Next I moved on to a single-column table with an nvarchar(450) column as the clustered, primary key. Because of the way the random strings were being calculated (RAND() is called for every character), I was fairly confident that I had no chance of generating duplicates. In this case I would expect that I would see a little bit of a benefit from page and/or row compression, but my hopes weren't very high. The script is as follows, and looks remarkably similar to the script above:
-- CI 450, data compression = none DECLARE @f nvarchar(2048) = N'üäāšßåøæ¥Ñ龥ñЉЩщӃ※℀℃№™③㒅㝬㿜abcdefg1234567890', @s nvarchar(2048) = N''; IF OBJECT_ID(N'dbo.foo', 'U') IS NOT NULL DROP TABLE dbo.foo; CREATE TABLE dbo.foo ( bar nvarchar(450) PRIMARY KEY CLUSTERED ) WITH (DATA_COMPRESSION = NONE); SET NOCOUNT ON; DECLARE @i int, @j int = 0; WHILE @j < 20000 BEGIN SELECT @i = 0, @s = N''; WHILE @i <= (450 - (RAND()*25)) BEGIN SELECT @s += SUBSTRING(@f, CONVERT(INT, (RAND()) * LEN(@f)), 1), @i += 1; END INSERT dbo.foo(bar) SELECT @s; SET @j += 1; END GO 10 -- CI 450, data compression = none SELECT TOP (1) bar FROM dbo.foo ORDER BY NEWID(); GO 10 -- CI 450, data compression = none SELECT TOP (1) bar FROM dbo.foo WHERE bar LIKE '2%' ORDER BY NEWID(); GO 10 -- CI 450, data compression = none SELECT TOP (1) bar FROM dbo.foo ORDER BY bar; GO 10 -- CI 450, data compression = none UPDATE dbo.foo SET bar = REPLACE(bar, '12', '※') WHERE bar LIKE '%12%'; UPDATE dbo.foo SET bar = REPLACE(bar, '21', '※') WHERE bar LIKE '%21%'; UPDATE dbo.foo SET bar = REPLACE(bar, '34', '※') WHERE bar LIKE '%34%'; UPDATE dbo.foo SET bar = REPLACE(bar, '43', '※') WHERE bar LIKE '%43%'; UPDATE dbo.foo SET bar = REPLACE(bar, '14', '※') WHERE bar LIKE '%14%'; GO 2 -- CI 450, data compression = none UPDATE dbo.foo SET bar = bar + N'x' WHERE bar LIKE 'a%'; UPDATE dbo.foo SET bar = bar + N'x' WHERE bar LIKE 'b%'; UPDATE dbo.foo SET bar = bar + N'x' WHERE bar LIKE 'c%'; UPDATE dbo.foo SET bar = bar + N'x' WHERE bar LIKE 'd%'; UPDATE dbo.foo SET bar = bar + N'x' WHERE bar LIKE 'e%'; GO 2 -- CI 450, data compression = none INSERT dbo.indexstats SELECT 'ci + none', index_id, in_row_data_page_count, used_page_count, reserved_page_count, row_count FROM sys.dm_db_partition_stats WHERE [object_id] = OBJECT_ID('dbo.foo'); GO
Again, I create copies of this script with minor changes for both PAGE and ROW compression.
My third test script mixes it up a bit by adding multiple columns, a composite clustered index, and a couple of non-clustered indexes as well. I also insert each simulated row 5 times. This has two effects: 1) it substantially increases I/O on both DML and SELECT statements; and, 2) by fitting much more data on a page *and* ensuring there is a lot of repeated data, it gives us much greater opportunities for taking advantage of PAGE and ROW compression algorithms.
-- 4*32, data compression = none DECLARE @f nvarchar(2048) = N'üäāšßåøæ¥Ñ龥ñЉЩщӃ※℀℃№™③㒅㝬㿜abcdefg1234567890', @s1 nvarchar(32) = N'', @s2 nvarchar(32) = N'', @s3 nvarchar(32) = N'', @s4 nvarchar(32) = N''; IF OBJECT_ID(N'dbo.foo', 'U') IS NOT NULL DROP TABLE dbo.foo; CREATE TABLE dbo.foo ( c1 nvarchar(32), c2 nvarchar(32), c3 nvarchar(32), c4 nvarchar(32) ) WITH (DATA_COMPRESSION = NONE); CREATE CLUSTERED INDEX i1 ON dbo.foo(c1,c2,c3,c4); CREATE INDEX i2 ON dbo.foo(c3 DESC) INCLUDE (c2); CREATE INDEX i3 ON dbo.foo(c2, c4 DESC); SET NOCOUNT ON; DECLARE @i int, @j int = 0; WHILE @j < 20000 BEGIN SELECT @i = 0, @s1 = N'', @s2 = N'', @s3 = N'', @s4 = N''; WHILE @i <= (RAND()*28) BEGIN SELECT @s1 += SUBSTRING(@f, CONVERT(INT, (RAND()) * LEN(@f)), 1), @s2 += SUBSTRING(@f, CONVERT(INT, (RAND()) * LEN(@f)), 1), @s3 += SUBSTRING(@f, CONVERT(INT, (RAND()) * LEN(@f)), 1), @s4 += SUBSTRING(@f, CONVERT(INT, (RAND()) * LEN(@f)), 1), @i += 1; END INSERT dbo.foo (c1,c2,c3,c4) VALUES (@s1,@s2,@s3,@s4), (@s1,@s2,@s3,@s4), (@s1,@s2,@s3,@s4), (@s1,@s2,@s3,@s4), (@s1,@s2,@s3,@s4); SET @j += 1; END GO 10 -- 4*32, data compression = none SELECT TOP (1) c1,c2,c3,c4 FROM dbo.foo ORDER BY NEWID(); GO 10 -- 4*32, data compression = none SELECT TOP (1) c1,c2,c3,c4 FROM dbo.foo WHERE c1 LIKE '2%' ORDER BY NEWID(); GO 10 -- 4*32, data compression = none SELECT TOP (1) c1,c2,c3,c4 FROM dbo.foo ORDER BY c2 DESC; GO 10 -- 4*32, data compression = none SELECT TOP (1) c1,c2,c3,c4 FROM dbo.foo ORDER BY c1,c2; GO 10 -- 4*32, data compression = none UPDATE dbo.foo SET c1 = REPLACE(c1, '1', '※') WHERE c1 LIKE '%1%'; UPDATE dbo.foo SET c2 = REPLACE(c2, '2', '※') WHERE c2 LIKE '%2%'; UPDATE dbo.foo SET c3 = REPLACE(c3, '3', '※') WHERE c3 LIKE '%3%'; UPDATE dbo.foo SET c4 = REPLACE(c4, '4', '※') WHERE c4 LIKE '%4%'; GO 2 -- 4*32, data compression = none UPDATE dbo.foo SET c1 = c1 + N'x' WHERE c1 LIKE 'a%'; UPDATE dbo.foo SET c2 = c2 + N'x' WHERE c2 LIKE 'a%'; UPDATE dbo.foo SET c3 = c3 + N'x' WHERE c3 LIKE 'a%'; UPDATE dbo.foo SET c4 = c4 + N'x' WHERE c4 LIKE 'a%'; GO 2 -- 4*32, data compression = none INSERT dbo.indexstats SELECT 'four32 + none', index_id, in_row_data_page_count, used_page_count, reserved_page_count, row_count FROM sys.dm_db_partition_stats WHERE [object_id] = OBJECT_ID('dbo.foo'); GO
Yet again, there are two other versions of this script, which only differ in the compression method in the comments and in the table declaration.
I primed the system by running each script a few times before taking metrics. This helps to ensure that external factors, such as autogrow events, do not inadvertently impact duration. Then I created this trace on both systems (I can re-use the code if both are named instances, otherwise I would hard-code the trace name):
DECLARE @rc int, @TraceID int, @TraceName sysname = N'C:\temp\UC_' + CONVERT(sysname, SERVERPROPERTY('InstanceName')), @MaxFS bigint = 5; EXEC @rc = sys.sp_trace_create @TraceID OUTPUT, 0, @TraceName, @MaxFS, NULL; EXEC sp_trace_setevent @TraceID, 12, 15, 1; EXEC sp_trace_setevent @TraceID, 12, 16, 1; EXEC sp_trace_setevent @TraceID, 12, 1, 1; EXEC sp_trace_setevent @TraceID, 12, 17, 1; EXEC sp_trace_setevent @TraceID, 12, 14, 1; EXEC sp_trace_setevent @TraceID, 12, 18, 1; EXEC sp_trace_setevent @TraceID, 12, 11, 1; EXEC sp_trace_setevent @TraceID, 12, 35, 1; EXEC sp_trace_setevent @TraceID, 12, 12, 1; EXEC sp_trace_setevent @TraceID, 12, 13, 1; EXEC sp_trace_setfilter @TraceID, 11, 0, 6, N'UnicodeTesting'; EXEC sp_trace_setfilter @TraceID, 35, 0, 6, N'UnicodeTesting'; EXEC sp_trace_setstatus @TraceID, 1; SELECT TraceID = @TraceID, TraceFile = @TraceName + N'.trc';
Make a note of the output in both cases, because after you run the tests, you will need them later to pull data from the trace output and ultimately to shut down and dispose of each trace.
Now, when I am actually going to run the tests, I make certain that I connect as the UnicodeTesting SQL authentication login, and not as the Windows authentication login I would normally use for any other activity. Not for security purposes, but to make sure the tests get picked up by the trace, and also to prevent the trace from being contaminated with non-test-related data that I will only have to filter out later. Then I run them all — in sequence, not in parallel, so that they do not interfere with each other, since they all share the same limited hardware. I found that most of the scripts would take upwards of 20 minutes to run on my paltry VM, so I was in for a long afternoon waiting for one script to finish before I fired off the next. I didn't feel like rigging up some tool to automate that (again, it would probably have taken longer in the long run, for this battery of tests). Hey, I had other computer stuff to do while I was waiting, don't worry.
When all 18 scripts had finished, I had plenty of trace and index stats data to look at, and here are the queries I ran (and a quick visual sample of the output):
DECLARE @TraceName sysname = N'C:\temp\UC_' + CONVERT(sysname, SERVERPROPERTY('InstanceName')) + N'.trc'; SELECT [Event] = LEFT(CONVERT(nvarchar(MAX), [TextData]), 42), [Count] = COUNT(*), [Elapsed_s] = SUM(Duration)/1000/1000.0, [AvgTime_s] = AVG(Duration)/1000/1000.0, [Avg_IO] = AVG(Reads+Writes), [Avg_CPU] = AVG(CPU) FROM sys.fn_trace_gettable(@TraceName, default) WHERE [TextData] NOT LIKE N'%dbo.indexstats%' GROUP BY LEFT(CONVERT(nvarchar(MAX), [TextData]), 42); SELECT [test] = description, [index_id], [rows] = row_count, [reserved_kb] = reserved_page_count * 8, [data_kb] = in_row_data_page_count * 8, [index_kb] = (used_page_count - in_row_data_page_count) * 8, [unused_kb] = (reserved_page_count - used_page_count) * 8 FROM UnicodeTesting.dbo.indexstats;
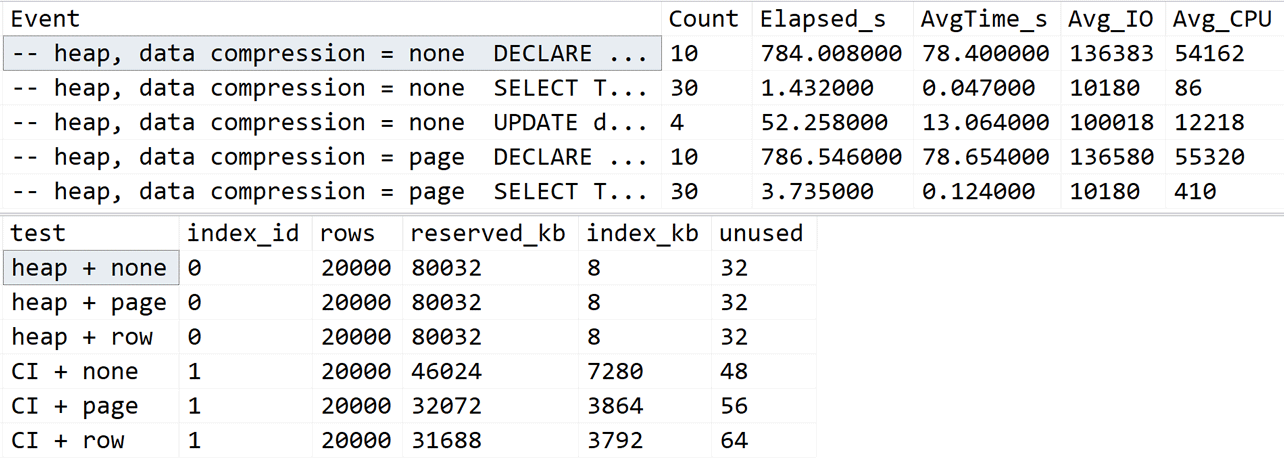
Partial output from trace and index stats queries
I then output the data into Excel, moved it around, waved my hands a bit, said some magic words, and tried to generate pretty charts like Linchi Shea always does.
The Results
I pulled out three interesting graphs from this data: duration, CPU usage and space savings. From the tests I performed, Unicode compression (when actually used) reduced space usage in every example — though I left the heap out of the graph, since the gains were 0 initially. And in almost every case, overall duration and CPU utilization of the same code went down when using compression (the exception is for the table with multiple indexes, where index maintenance overhead yielded slightly longer runtimes – but barely). In general, durations were lower in SQL Server 2008 R2, and this was repeatable no matter what order I ran the tests in. I am not sure if I was seeing the benefits of untold enhancements there, or cosmic rays, or gremlins, or what. I left the I/O metrics I captured out of the analysis, because the differences were negligible across all of the tests.
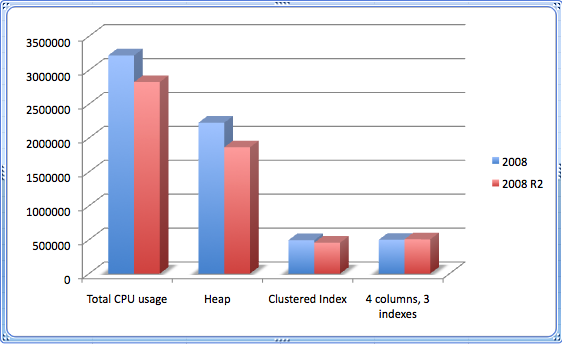
CPU Usage – lower is better
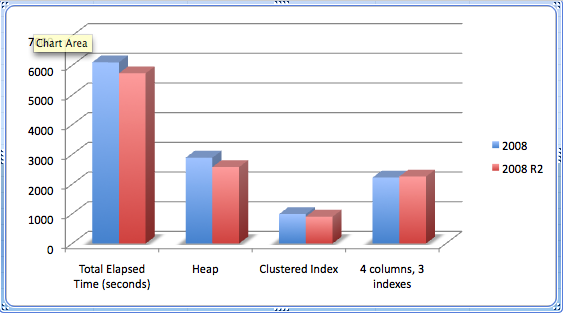
Elapsed Time (seconds) – lower is better
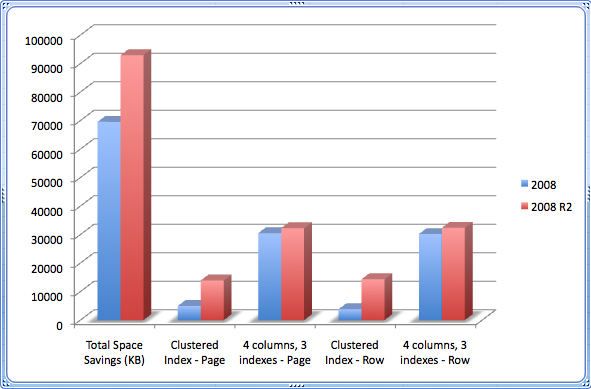
Space Savings (KB) – higher is better
The charts speak for themselves… as long as your index maintenance is not incredibly high, there can be some significant gains in using compression on nvarchar columns, and that only gets better in SQL Server 2008 R2.
Revisiting Heaps
I did go back and discover that if I ran the following manually, I *was* able to recover a significant amount of space in the heap tables:
ALTER TABLE dbo.foo REBUILD WITH (DATA_COMPRESSION = PAGE);
So, the documentation, which states that you can benefit from compression simply by adding TABLOCK to a normal INSERT statement, did not ring true in my case. I will have to remember to follow up on that later with more tests. In any case, for heaps that are large enough where you can gain a substantial advantage, how often are you going to be issuing a rebuild? I didn't think this was a realistic enough scenario to go back and re-do the tests, but if you feel it worthy, I will certainly work it into any further tests I do. I did compare the space savings between 2008 and 2008 R2, without going back and re-calculating CPU and IO metrics for DML operations, just to give an idea of the difference that Unicode compression can make when the stars align. The results were as follows:
In 2008 R2, the rebuild provides a significant space savings, all due to Unicode compression. I can assume this because, without the Unicode compression, I actually *lost* a tiny sliver of space on the heap in SQL Server 2008, after performing the same rebuild with the same page compression setting.
Conclusion
If your system is already CPU-bound, then maybe data and backup compression are not for you in the first place, so you won't benefit from Unicode compression either. It may also not be a very useful enhancement for you if you have few or no nvarchar columns (but you get it for free if you are using page compression anyway; there is no separate option). We are in the opposite scenario, because we are I/O bound and have a lot of nvarchar columns, so I think we could benefit greatly from further compression — on top of what we already expected to gain from page compression (dictionary and column-prefix compression) and row compression (variable length storage). And even if you can't benefit much from page and row compression, you may still benefit from Unicode compression once you have enabled them.
I later plan to investigate what happens with "more traditional" data in a "more common" scenario, where nvarchar is in use in an English scenario and the actual extra-byte characters that are in use are few and far between. I suppose I could take the script above and just make the input string a lot longer, and contain very few "foreign" characters. More likely though, I will generate all of the test data in one pass, and use BULK INSERT to populate the tables — this will ensure that every single version of the table contains the exact same data, and hopefully will use compression automatically on a heap without having to manually rebuild.
But not today. It's amazing sometimes how these "simple" experiments steal away your entire weekend.
More info
If you want more details about page, row and Unicode compression, you can see these topics in Books Online:
Clean Up
Don't forget to clean up your traces on both systems (since I don't have other user-defined traces, <traceID> was always 2 in my case, but if your system is busier, this is where making a note of the trace output above would come in handy, otherwise you will have to figure it out from sys.traces):
EXEC sp_trace_setstatus <traceID>, 0; EXEC sp_trace_setstatus <traceID>, 2;
Once you are done with analyzing the trace output, delete the .trc files from the file system.
And finally, to clean up the database and login, after closing down all the existing sessions you created (perhaps easiest to shut down SSMS and launch a new window, connected as someone *other* than UnicodeTesting):
USE [master]; GO ALTER DATABASE UnicodeTesting SET SINGLE_USER WITH ROLLBACK IMMEDIATE; GO DROP DATABASE UnicodeTesting; GO DROP LOGIN UnicodeTesting; GO
In a conversation with Microsoft's Marcel van der Holst, I learned why compression in SQL Server 2008 R2, in spite of performing more work than in 2008, actually uses less CPU. While the SQL Server MVPs have already read this statement, I thought I would crop out the good bits for the rest of you:
"…as part of the performance testing of Unicode Compression I refactored the code paths that gets used for the other compression data types as well. Further, I was able to get about 2-3% of performance gain by refactoring a comparison routine that was used for both compressed and uncompressed data. By splitting the function in two, actually both the uncompressed and compressed codepaths got faster, as the compiler was able to better inline the code in both cases."
So it turns out that my guess was right: there *is* some tuning in R2 that we don't yet see in 2008, though it seems unlikely to me that those optimizations will ever make it back into the original 2008 codebase.
Adam, I found it surprising as well. What I didn't show in the graphs was a comparison of no compression at all vs. page + Unicode compression, but on one version. Comparing compression on 2008 vs. compression on 2008 R2 was my main target, as I was trying to demonstrate how much CPU Unicode compression alone would add. Unfortunately this back-fired as I am trying to compare too many variables.
My guess is that there is some tuning in R2 that we don't yet see in 2008. I still have all of the data so maybe I can figure out some more data to extrapolate, but I certainly intend to do more realistic tests. Unfortunately I can't isolate the cost of Unicode compression on 2008 R2 only, since there is no way to have page/row without Unicode. <shrug>
Interesting tests, Aaron. I'm surprised that you're actually seeing lower CPU utilization in some cases–I'll definitely have to dig in to those tests. Thanks for posting this.
Yes, I agree the data was not very realistic, and stated that I would like to further my research by performing more real-world tests in the future.
This looks pretty cool!
Thorough research.
I'm not sure about the validity of your test data (using chars from so many unicode ranges); a more typical load will behave differently on unicode compression: http://en.wikipedia.org/wiki/Standard_Compression_Scheme_for_Unicode
I will certainly use this thing. I didn't like vardecimal, so I didn't think I would like the next evolutionary step either, but this looks sweet. Wonder if anyone has measured unicode compression vs typical VARCHAR on large data bases running on serious hardware. Should be interesting.