
Aaron Bertrand announces the first annual Community Influencer of the Year award.

Aaron Bertrand announces the first annual Community Influencer of the Year award.

I take an initial look at the performance of a new function, STRING_AGG, in SQL Server v.Next CTP 1.1.

For both T-SQL Tuesday and #BackToBasics, I provide information about SQL Server backups, and why your restores can be just as important.

I explain a few details about the memory limits in SQL Server 2016 Service Pack 1 that make this upgrade even more compelling.

Tip : Top 5 Reasons for Wrong Results in SQL Server

I describe my steps for setting up a development stack, with VS Code on Mac, managing SQL Server on Ubuntu, inside a Docker container.
Microsoft has made a bold change with SQL Server 2016 Service Pack 1 : Many Enterprise features are now available in lower editions. Read on for details.
Tip : New Features in SQL Server 2016 Service Pack 1
After a conversation online, I show where excessive comments in your stored procedures might have an impact on performance.

I explain why I always opt for one of these options over the other.

We've all accidentally placed objects in master. In this tip, I show how you can clean it up a little.

I refreshed the demo kit that helps you learn (or teach!) the ins and outs of SentryOne Plan Explorer.

I explains why I code defensively – matching the case of data type names, even when it is irrelevant.

I explain why you shouldn't bother adding ORDER BY to views in SQL Server.

I run some tests to challenge the notion that CHARINDEX is always faster at pattern matching than LEFT and LIKE.

I talk about two core issues to consider when choosing a standard for stored procedure names.

I continue a series on widening an IDENTITY column, showing how I would attack the problem directly.

I take a look at one of the classic debates in SQL Server: whether to support Unicode.
Tip : Beware of Side-Channel Attacks in Row-Level Security in SQL Server 2016

I show a few different ways to download SQL Server 2016 Developer Edition, which is a bit harder to obtain than it should be.

I submit a wish list item for the 80th T-SQL Tuesday: CREATE OR REPLACE, a cleaner way to deploy objects without losing permissions.

I follow up on a recent post about DATEFROMPARTS() with a deeper look into the estimates and potential mitigation techniques.
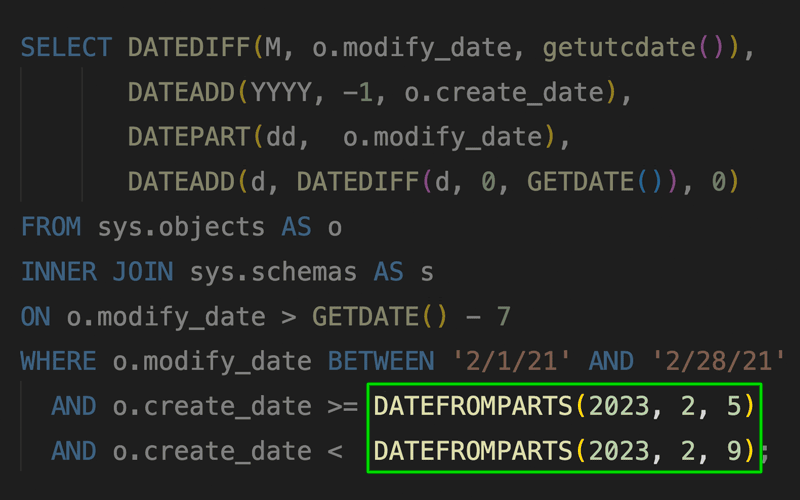
I continue my #EntryLevel challenge, discussing DATEFROMPARTS() and similar functions introduced in SQL Server 2012.
I ask you to vote for and, more importantly, comment on a Connect item aimed at adding MAXDOP controls to statistics updates.
For this T-SQL Tuesday, I talk about a feature long missing from SQL Server: The ability for Developer Edition to act like Standard.

Continuing the #EntryLevel challenge, I discuss optimizing the kitchen sink procedure with dynamic SQL and, optionally, OPTION (RECOMPILE).

For T-SQL Tuesday #78, I take a look at whether RID Lookups are faster than key Lookups, with a small battery of fairly simple duration tests.

I explain some of the more common acronyms you might see flung around in blog posts, Connect items, and Knowledge Base articles.

With additional tests comparing splitting techniques to TVPs, I round out my series on STRING_SPLIT() in SQL Server 2016.
I follow up on a recent post about the performance of STRING_SPLIT() with a few additional reader-motivated tests.
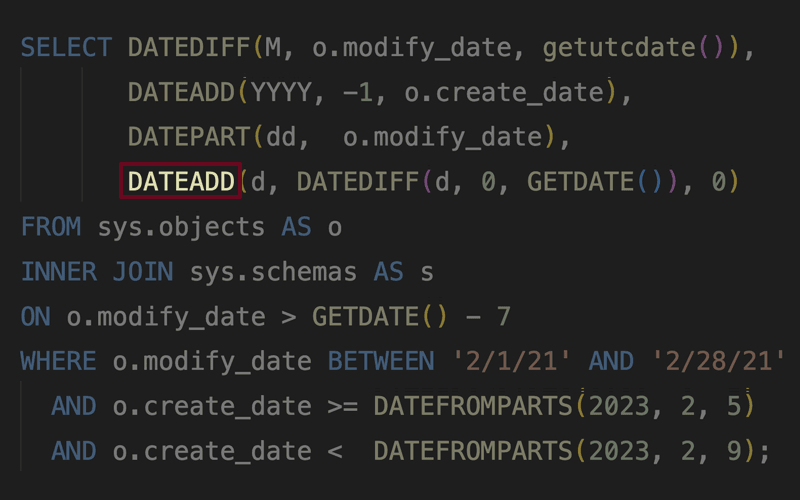
I explore yet another scenario where a date/time function seems to cause the optimizer to behave unexpectedly.

I give four quick tips on using date and time values effectively in SQL Server.

I talk about some of the upcoming changes to telemetry and other privacy settings in SQL Server 2016.

Following up on an earlier post about metadata, I reveal a few more ways I discover changes in SQL Server.
SQL Server 2016 RC0 introduces a new native string splitting function, STRING_SPLIT; I compare its performance to existing methods.

SQL Server 2016 allows you to enable instant file initialization during installation; I look at how this can impact tempdb data file creation.

Tip : Extracting ShowPlan XML from SQL Server Extended Events
I share some insight about early changes to Plan Explorer that help to provide you with the most accurate information we can.

In this post, I talk about synonyms and how they can be used.

I revisit the impact that eliminating DONE_IN_PROC messages using SET NOCOUNT ON may or may not have on query performance.

Tip : The SQL Server Numbers Table, Explained – Part 2
Tip : The SQL Server Numbers Table, Explained – Part 1

I continue a series on upsizing an IDENTITY column from INT to BIGINT – this time focusing on workarounds.

I continue a series on upsizing an IDENTITY column from int to bigint, detailing several challenging obstacles.

A recent Visual Studio outage has been largely blamed on the cardinality estimator, but I think the query itself has a share of the blame.

I describe a few different causes for a symptom you might describe as a "runaway" query in SQL Server.

As part of a new series, I take a look at what happens to the structure of a page when an INT column needs to be upsized to a BIGINT.
I compare the performance of different UDFs and raw queries used for splitting and reassembling a delimited string.